eBPF
概述
参考:
- 官网
- Kernel 官方文档,BPF
- Cilium 官方文档,BPF Kernel 官方文档中指向的另一个文档,BPF 官方文档什么是 eBPF 最下面也有链接指向这里
- GitHub 项目,torvalds/linux/tools/lib/bpf(libbpf 库)
学习资料
- eBPF 概述:第 1 部分:介绍
- eBPF 概述:第 2 部分:机器和字节码
- eBPF 概述:第 3 部分:软件开发生态
- eBPF 概述:第 4 部分:在嵌入式系统运行
- eBPF 概述:第 5 部分:跟踪用户进程
公众号,阿里云云原生-深入浅出 eBPF | 你要了解的 7 个核心问题
GitHub 项目,DavadDi/bpf_study(DavaDi 的 BPF 学习文章)
https://coolshell.cn/articles/22320.html
eBPF 为什么高效
eBPF 程序比传统程序“跑得”更快,因为它的代码是直接在内核空间中执行的。
设想这样一个场景,假设一个程序想要统计其从 Linux 系统上发送出去的字节数,需要经过哪些步骤?
首先,网络活动发生时,内核会生成原始数据,这些原始数据包含了大量的信息,而且大部分信息都与“字节数”这个信息无关。所以,无论生成的原始数据是个啥,只要你想统计发送出去的字节数,就必须反复过滤,并对其进行数学计算。这个过程每分钟要重复数百次(甚至更多)。
传统的监控程序都运行在用户空间,内核生成的所有原始数据都必须从内核空间复制到用户空间,这种数据复制和过滤的操作会对 CPU 造成极大的负担。这就是为什么 ptrace 很“慢”,而 bpftrace 很”快“。
eBPF 无需将数据从内核空间复制到用户空间,你可以直接在内核空间运行监控程序来聚合可观测性数据,并将其发送到用户空间。eBPF 也可以直接在内核空间过滤数据以及创建 Histogram,这比在用户空间和内核空间之间交换大量数据要快得多。
eBPF 架构与原理简述
参考:
eBPF 是一项革命性的技术,起源于 Linux 内核,可以在操作系统内核中运行 Sandbox Programs(沙箱程序) 而无需修改内核源代码或加载内核模块。
纵观历史,由于内核具有监督和控制整个系统的特权,操作系统一直是实现可观测性、安全性、网络功能的理想场所。同时,操作系统内核由于其核心租用以及对稳定性和安全性的高要求而难以发展。因此,与在操作系统之外实现的功能相比,操作系统级别的创新率传统上较低。
eBPF 从根本上改变了这个套路。通过允许在操作系统中运行沙盒程序,应用程序开发人员可以运行 eBPF 程序以在运行时向操作系统添加额外的功能。然后,操作系统保证安全性和执行效率,就像借助 Just-In-Time(即时,简称 JIT) 编译器和验证引擎进行本地编译一样。这引发了一波基于 eBPF 的项目,涵盖了广泛的用例,包括下一代网络、可观察性和安全功能。

Hook(钩子)
众所周知,Linux 内核是一个事件驱动的系统设计,这意味着所有的操作都是基于事件来描述和执行的。比如打开文件是一种事件、CPU 执行指令是一种事件、接收网络数据包是一种事件等等。eBPF 作为内核中的一个子系统,可以检查这些基于事件的信息源,并且允许开发者编写并运行在内核触发任何事件时安全执行的 BPF 程序。
eBPF 程序也是事件驱动的,当内核或应用程序通过某个 Hook(钩子) 点时会运行这个 eBPF 程序。预定义的 Hook 包括 System Call、函数入口/出口、内核的 Tracepoints、网络事件、etc. ,这些 Hook也可以称为 内核中特定的代码路径。

int syscall__ret_execve(struct pt_regs *ctx)
{
struct comm_event event = {
.pid = bpf_get_current_pid_tgid() >> 32,
.type = TYPE_RETURN,
};
bpf_get_current_comm(&event.comm, sizeof(event.comm));
comm_events.perf_submit(ctx, &event, sizeof(event));
return 0;
}
如果预定义的 Hook 不能满足自己的需求,还可以创建 kprobe(内核探针)、uprobe(用户探针),以便在内核或用户应用程序的几乎任何位置附加 eBPF 程序。

工作流程简述
这是官方的流程图,里面的 eBPF 程序是使用 Go 语言的 eBPF 库编写的

- 编写 # 首先,开发者可以使用 C 语言(或者 Go 等其他高级程序语言)编写自己的 eBPF 程序,然后通过 LLVM/Clang 编译套件,将其编译成 eBPF 字节码。
- 本质上还是可执行的二进制程序,只不过内部有 eBPF 字节码。
- 加载 # 运行编译好的 eBPF 程序,通过 bpf() 系统调用,将程序中的字节码传入内核空间,以加载 eBPF 程序。
- 当 eBPF 程序被加载到 Linux 内核中时,它在被附加到所请求的 Hook 之前还需要经过 验证 与 JIT 这两个步骤。
- 验证 # 传入内核空间之后的 eBPF 程序,并不是直接就在其指定的内核跟踪点上开始执行,而是先通过 Verifier 这个组件,来保证我们传入的这个 BPF 程序可以在内核中安全的运行。
- JIT # 经过安全检测之后,Linux 内核 还为 eBPF 字节码提供了一个实时的编译器(Just-In-Time,JIT),JIT 将确认后的 eBPF 字节码编译为对应的机器码。这样就可以在 eBPF 指定的跟踪点上执行我们的操作逻辑了。
- Maps # 那么,用户空间的应用程序怎么样拿到我们插入到内核中的 eBPF 程序产生的数据呢?eBPF 是通过一种 MAP 的数据结构来进行数据的存储和管理的,eBPF 将产生的数据,通过指定的 MAP 数据类型进行存储,用户空间的应用程序,作为消费者,通过 bpf() 系统调用,从 MAP 数据结构中读取数据并进行相应的存储和处理。这样一个完整 eBPF 程序的流程就完成了。
一个 eBPF 程序从某种角度来说,其实可以分为两部分看:
- 一部分字节码被加载进内核并 Hook 到某个或某些地方;
- 另一部分是当前一部分被加载的字节码触发时,对产生的数据进行处理的逻辑。

编写 eBPF 程序
在很多情况下,eBPF 不是直接使用,而是通过像 Cilium、bcc 或 bpftrace 这样的项目间接使用,这些项目提供了 eBPF 之上的抽象,不需要直接编写程序,而是提供了指定基于意图的来定义实现的能力,然后用 eBPF 实现。

如果不存在更高层次的抽象(i.e. 满足某些意图的 eBPF 程序),则需要直接编写程序。Linux 内核期望 eBPF 程序以字节码的形式加载。虽然直接编写字节码也是可以的,但更常见的开发实践是利用像 LLVM 这样的编译器套件将伪 c 代码编译成 eBPF 字节码。
加载器
运行 eBPF 程序后,会识别出 Hook,利用 bpf() 系统调用将 eBPF 程序加载到 Linux 内核中。
Notes: 这通常是利用 eBPF 库来实现的,加载的是程序中的 eBPF 字节码

Notes: 图里最上面两个 Process 是分开的,本质是两个不同的程序。整个图也应该左右分开看。左半部分是 eBPF 程序编译和加载的过程;右半部分是用户空间应用程序运行时的过程。
其中 JIT 到后边的过程是指:eBPF 程序进入内核,被附加到 Syscall 上。右边的 Process 在运行时调用的 Syscall 会触发已经 Hook 了某个点的 eBPF 程序进行工作。
当 eBPF 程序被加载到 Linux 内核中时,它在被附加到所请求的 Hook 之前还需要经过 “验证” 与 “JIT编译” 这两个步骤。
验证与 JIT 编译
验证步骤确保 eBPF 程序可以安全运行。它验证程序是否满足多个条件,例如:
- 加载 eBPF 程序的进程必须有所需的能力(特权)。除非启用非特权 eBPF,否则只有特权进程可以加载 eBPF 程序。
- eBPF 程序不会崩溃或者对系统造成损害。
- eBPF 程序一定会运行至结束(即程序不会处于循环状态中,否则会阻塞进一步的处理)。
Just-in-Time(即时,简称 JIT),JIT 编译步骤将第一步编写代码后生成的字节码转换为机器特定的指令集,用以优化程序的执行速度。这使得 eBPF 程序可以像本地编译的内核代码或作为内核模块加载的代码一样高效地运行。
JIT 后,加载到内核 eBPF 程序将会运行并产生数据,作为用户,如何拿到这些数据?依靠 eBPF Maps
Map
eBPF 有一个黑科技,它会使用 eBPF Map(eBPF 映射) 来允许用户空间和内核空间之间进行双向数据交换。在 Linux 中,映射(Map)是一种通用的存储类型,用于在用户空间和内核空间之间共享数据,它们是驻留在内核中的键值存储。
对于可观测性这种应用场景,eBPF 程序会直接在内核空间进行计算,并将结果写入用户空间应用程序可以读取/写入的 eBPF 映射中。
eBPF 的高效主要还是:eBPF 提供了一种直接在内核空间运行自定义程序,并且避免了在内核空间和用户空间之间复制无关数据的方法。

eBPF 程序的一个重要方面是共享收集的信息和存储状态的能力。为此,eBPF 程序可以利用 eBPF Maps 的概念来存储和检索各种数据结构中的数据。 eBPF Maps 可以通过系统调用从 eBPF 程序以及用户空间中的应用程序访问。
其他
Helper Calls
5 个模块
eBPF 在内核主要由 5 个模块协作:
1、BPF Verifier(验证器)
确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令,这里通过和个别同学了解到,这里的验证器并无法保证 100%的安全,所以对于所有 BPF 程序,都还需要严格的监控和评审。
2、BPF JIT
将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
3、多个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块
用于控制 eBPF 程序的运行,保存栈数据,入参与出参。
4、BPF Helpers(辅助函数)
提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。注意,eBPF 里面所有对入参,出参的修改都必须符合 BPF 规范,除了本地变量的变更,其他变化都应当使用 BPF Helpers 完成,如果 BPF Helpers 不支持,则无法修改。
bpftool feature probe
通过以上命令可以看到不同类型的 eBPF 程序可以运行哪些 BPF Helpers。
5、BPF Map & context
用于提供大块的存储,这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
bpftool feature probe | grep map_type
通过以上命令可以看到系统支持哪些类型的 map。
3 个动作
先说下重要的系统调用 bpf:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
这里 cmd 是关键,attr 是 cmd 的参数,size 是参数大小,所以关键是看 cmd 有哪些:
// 5.11内核
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
......
};
最核心的就是 PROG,MAP 相关的 cmd,就是程序加载和映射处理。
1、程序加载
调用 BPF_PROG_LOAD cmd,会将 BPF 程序加载到内核,但 eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等,所以需要第 2 个动作。
2、绑定事件
b.attach_kprobe(event=“xxx”, fn_name=“yyy”)
以上就是将特定的事件绑定到特定的 BPF 函数,实际实现原理如下: (1)借助 bpf 系统调用,加载 BPF 程序之后,会记住返回的文件描述符; (2)通过 attach 操作知道对应函数类型的事件编号; (3)根据 attach 的返回值调用 perf_event_open 创建性能监控事件; (4)通过 ioctl 的 PERF_EVENT_IOC_SET_BPF 命令,将 BPF 程序绑定到性能监控事件。
3、映射操作
通过 MAP 相关的 cmd,控制 MAP 增删,然后用户态基于该 MAP 与内核状态进行交互。
为什么使用 eBPF
https://ebpf.io/what-is-ebpf/#why-ebpf
可编程性的力量
让我们从一个类比开始。你还记得 GeoCities 吗? 20 年前,网页几乎完全由静态标记语言(HTML)编写。网页基本上是一个文档,有一个应用程序(浏览器)可以显示它。看看今天的网页,网页已经成为成熟的应用程序,基于 web 的技术已经取代了绝大多数用需要编译的语言所编写的应用程序。是什么促成了这种演进 ?
简短的回答是通过引入 JavaScript 实现可编程性。它开启了一场巨大的革命,导致浏览器几乎演变成一个独立的操作系统。
为什么会发生这个演进 ?程序员不再受制于运行特定浏览器版本的用户。提升必要构建模块的可用性,将底层浏览器的创新速度与运行在其上的应用程序解耦开来,而不是去说服标准机构需要一个新的 HTML 标签。这当然有点过于简化这个过程中的变化了,因为 HTML 确实随着时间的推移而一直发展,并对这个演进的成功做出了贡献,但 HTML 本身的发展还不足够满足需求。
在将这个示例应用于 eBPF 之前,让我们先看一下在引入 JavaScript 过程中的几个关键方面:
- 安全:不受信任的代码在用户的浏览器中运行。这个问题通过沙箱 JavaScript 程序和抽象对浏览器数据的访问来解决。
- 持续交付:程序逻辑的演进必须能够在不需要不断发布新浏览器版本的情况下实现。通过提供适当的底层构建模块来构建任意逻辑,解决了这个问题。
- 性能:必须以最小的开销提供可编程性。这个问题通过引入即时(JIT)编译器得到了解决。由于同样的原因,上述所有方面都可以在 eBPF 中找到完全对应的内容。
eBPF 对 Linux 内核的影响
现在让我们回到 eBPF。为了理解 eBPF 对 Linux 内核的可编程性的影响,有必要对 Linux 内核的体系结构及其与应用程序和硬件的交互方式有一个高层次的了解。
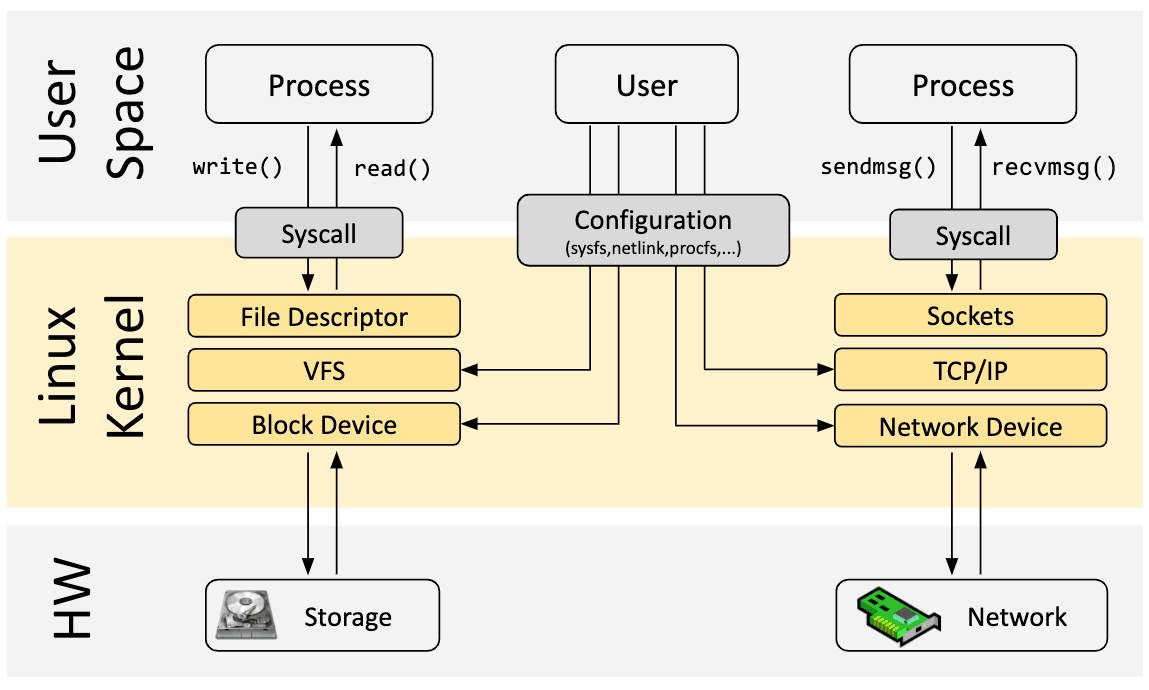
Linux 内核的主要目的是对硬件或虚拟硬件进行抽象,并提供一致的 API(系统调用),允许应用程序运行和共享资源。为了实现这一点,内核维护了一组广泛的子系统和层来分配这些职责。每个子系统通常允许某种级别的配置,以满足用户的不同需求。如果无法配置所需的行为,则需要更改内核,从历史上看,只剩下两个选项:
| 原生支持 | 内核模块 |
|---|---|
| 1. 更改内核源代码并使 Linux 内核社区相信改动是有必要的。 2. 等待几年后,新的内核才会成为一个通用版本。 | 1. 编写一个内核模块 2. 定期修复它,因为每个内核版本都可能破坏它 3. 由于缺乏安全边界,有可能损坏 Linux 内核 |
有了 eBPF,就有了一个新的选项,它允许重新编程 Linux 内核的行为,而不需要更改内核源代码或加载内核模块。在许多方面,这与 JavaScript 和其他脚本语言解锁系统演进的方式非常相像,对这些系统进行改动的原有方式已经变得困难或昂贵。
eBPF 项目路线图
基于 eBPF 的实现
参考:
- tcpdump # 网络抓包工具
- TC eBPF # 作用在传统 TC 模块的 eBPF
- XDP eBPF # 各种 eBPF 程序新增加的 DataPath 通常都称为 XDP。
- Cilium #
eBPF 库
参考:
C/C++ 库
- github.com/libpf/libbpf # 作为上游 Linux 内核的一部分进行维护。
Go 库
- github.com/cilium/ebpf # Cilium 维护的纯 Go 语言的 eBPF 库
- github.com/aquasecurity/libbpfgo # Aqua 维护的围绕 libbpf 的 Go 语言 eBPF 库。支持 CO-RE。使用 CGo 调用 libbpf 的链接版本。
Rust 库
BPF 程序示例
BCC 版 HelloWrold
#!/usr/bin/env python3
from bcc import BPF
# This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
prog = """
int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
b = BPF(text=prog, debug=0x04)
b.trace_print()
运行程序前需要安装过 bcc 相关工具包,正常运行后,每当系统中发生 sys_clone() 系统调用时,运行的控制台上就会打印 “Hello, World!”,在打印文字前面还包含了调用程序的进程名称,进程 ID 等信息;
如果运行报错,可能是缺少头文件,一般安装 kernel-devel 包即可。
Go 语言示例
https://ebpf-go.dev/guides/getting-started/
公众号 - 幻想发生器,使用 Golang 开发 eBPF 的应用
BPF 项目介绍
GitHub 项目,danger-dream/ebpf-firewall
- 使用 Go 语言调用 Cilium 的 eBPF 库实现的防火墙程序。具有实时入站流量监控、规则过滤和黑名单管理等功能。主要用于在资源有限的 VPS 中进行入站流量监控和过滤。
其他
其实,eBPF 是一种设计思想,eBPF 是一个 General purpose execution Engine(通用目的执行引擎)。换句话说,eBPF 是一个最小指令集架构(a minimal instruction set architecture),在设计时两个主要考虑:
- 将 eBPF 指令映射到平台原生指令时开销尽可能小 —— 尤其是 x86-64 和 arm64 平台,因此我们针对这两种架构进行了很多优化,使程序运行地尽可能快。
- 内核在加载 eBPF 代码时要能验证代码的安全性 —— 这也是为什么我们一 直将其限制为一个最小指令集,因为这样才能确保它是可验证的(进而是安全的)。很多人像我一样,在过去很长时间都在开发内核模块(kernel module)。 但内核模块中引入 bug 是一件极度危险的事情 —— 它会导致内核 crash。 此时 BPF 的优势就体现出来了:校验器(verifier)会检查是否有越界内存访问 、无限循环等问题,一旦发现就会拒绝加载,而非将这些问题留到运行时(导致 内核 crash 等破坏系统稳定性的行为)。所以出于安全方面的原因,很多内核开发者开始用 eBPF 编写程序,而不再使用传统的内核模块方式。
eBPF 提供的是 基本功能模块(building blocks) 和 attachment points(程序附着点)。 我们可以编写 eBPF 程序来 attach 到这些 points 点完成某些高级功能。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.