Context Switch(上下文切换)
概述
参考:
我们都知道,Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文
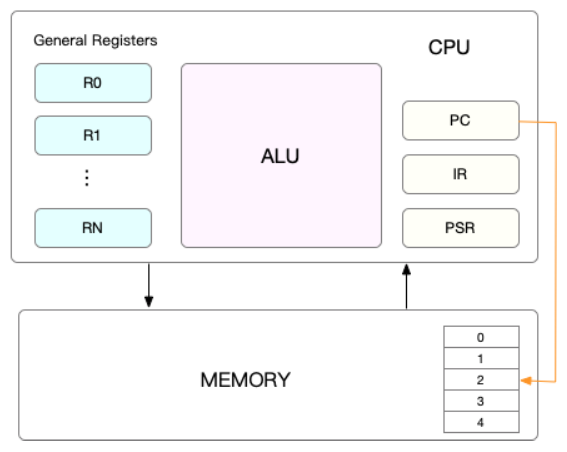
知道了什么是 CPU 上下文,我想你也很容易理解 CPU 上下文切换。CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
我猜肯定会有人说,CPU 上下文切换无非就是更新了 CPU 寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?
在回答这个问题前,不知道你有没有想过,操作系统管理的这些“任务”到底是什么呢?也许你会说,任务就是进程,或者说任务就是线程。是的,进程和线程正是最常见的任务。但是除此之外,还有没有其他的任务呢?
不要忘了,硬件通过触发信号,会导致中断处理程序的调用,也是一种常见的任务。
所以,根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景:
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。

换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
那么,系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
那么,进程上下文切换跟系统调用又有什么区别呢?
首先,你需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。

根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
知道了进程上下文切换潜在的性能问题后,我们再来看,究竟什么时候会切换进程上下文。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
那么,进程在什么时候才会被调度到 CPU 上运行呢?
最容易想到的一个时机,就是进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。其实还有很多其他场景,也会触发进程调度,在这里我给你逐个梳理下。
其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
了解这几个场景是非常有必要的,因为一旦出现上下文切换的性能问题,它们就是幕后凶手。
自愿切换与非自愿切换
进程与线程的上下文切换分为两类
- voluntary context switches(自愿上下文切换) # 是指进程无法获取所需资源,导致的上下文切换。比如说,I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- non voluntary context switches(非自愿上下文切换)、有的地方也叫 involuntary(强制上下文切换) # 指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
从进程的角度看,CPU 是共享资源,由所有的进程按特定的策略轮番使用。一个进程离开 CPU、另一个进程占据 CPU 的过程,称为进程切换(process switch)。进程切换是在内核中通过调用 schedule()完成的。
发生进程切换的场景有以下三种:
- 进程运行不下去了:
- 比如因为要等待 IO 完成,或者等待某个资源、某个事件,典型的内核代码如下:
//把进程放进等待队列,把进程状态置为TASK_UNINTERRUPTIBLE
prepare_to_wait(waitq, wait, TASK_UNINTERRUPTIBLE);
//切换进程
schedule();
- 所以,很多时候当 IO wait 过高时,其自愿上下文切换也会随之增长,因为默认时间片很短,而 IO 耗时很长,所以进程必然会被挂起等待 IO 完成,这个挂起操作,也就是一个上下文切换。
- 进程还在运行,但内核不让它继续使用 CPU 了:
- 比如进程的时间片用完了,或者优先级更高的进程来了,所以该进程必须把 CPU 的使用权交出来;
- 进程还可以运行,但它自己的算法决定主动交出 CPU 给别的进程:
- 用户程序可以通过系统调用 sched_yield()来交出 CPU,内核则可以通过函数 cond_resched()或者 yield()来做到。
以上场景 1 属于自愿切换,场景 2 和 3 属于非自愿切换。如何分辨自愿切换和强制切换呢?
- 自愿切换发生的时候,进程不再处于运行状态,比如由于等待 IO 而阻塞(TASK_UNINTERRUPTIBLE),或者因等待资源和特定事件而休眠(TASK_INTERRUPTIBLE),又或者被 debug/trace 设置为 TASK_STOPPED/TASK_TRACED 状态;
- 强制切换发生的时候,进程仍然处于运行状态(TASK_RUNNING),通常是由于被优先级更高的进程抢占(preempt),或者进程的时间片用完了。
注:实际情况更复杂一些,由于 Linux 内核支持抢占,kernel preemption 有可能发生在自愿切换的过程之中,比如进程正进入休眠,本来如果顺利完成的话就属于自愿切换,但休眠的过程并不是原子操作,进程状态先被置成 TASK_INTERRUPTIBLE,然后进程切换,如果 Kernel Preemption 恰好发生在两者之间,那就打断了休眠过程,自愿切换尚未完成,转而进入了强制切换的过程(虽然是强制切换,但此时的进程状态已经不是运行状态了),下一次进程恢复运行之后会继续完成休眠的过程。所以判断进程切换属于自愿还是强制的算法要考虑进程在切换时是否正处于被 抢占(preempt) 的过程中,参见以下内核代码:
staticvoid__sched __schedule(void)
{
...
switch_count=&prev->nivcsw;//强制切换的次数
if(prev->state&&!(preempt_count()&PREEMPT_ACTIVE)){//进程处于非运行状态并且允许抢占
...
switch_count=&prev->nvcsw;//自愿切换的次数
}
...
if(likely(prev!=next)){
rq->nr_switches++;
rq->curr=next;
++*switch_count;//进程切换次数累加
context_switch(rq,prev,next);/* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu=smp_processor_id();
rq=cpu_rq(cpu);
}else
raw_spin_unlock_irq(&rq->lock);
...
}
not_running&&preemptive:voluntary
最后,澄清几个容易产生误解的场景:
- 进程可以通过调用 sched_yield()主动交出 CPU,这不是自愿切换,而是属于强制切换,因为进程仍然处于运行状态。
- 有时候内核代码会在耗时较长的循环体内通过调用 cond_resched()或 yield() ,主动让出 CPU,以免 CPU 被内核代码占据太久,给其它进程运行机会。这也属于强制切换,因为进程仍然处于运行状态。
进程自愿切换(Voluntary)和强制切换(Involuntary)的次数被统计在 /proc/<pid>/status 中,其中 voluntary_ctxt_switches 表示自愿切换的次数,nonvoluntary_ctxt_switches 表示强制切换的次数,两者都是自进程启动以来的累计值。
# grep ctxt /proc/26995/status
voluntary_ctxt_switches: 79
nonvoluntary_ctxt_switches: 4
也可以用 pidstat -w 命令查看进程切换的每秒统计值:
# pidstat -w 1
Linux3.10.0-229.14.1.el7.x86_64(bj71s060) 02/01/2018 _x86_64_ (2CPU)
12:05:20PM UID PID cswch/snvcswch/s Command
12:05:21PM 0 1299 0.94 0.00 httpd
12:05:21PM 0 27687 0.94 0.00 pidstat
自愿切换和强制切换的统计值在实践中有什么意义呢? 大致而言,如果一个进程的自愿切换占多数,意味着它对 CPU 资源的需求不高。如果一个进程的强制切换占多数,意味着对它来说 CPU 资源可能是个瓶颈,这里需要排除进程频繁调用 sched_yield()导致强制切换的情况。
线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位
说完了进程的上下文切换,我们再来看看线程相关的问题。
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
除了前面两种上下文切换,还有一个场景也会切换 CPU 上下文,那就是中断。
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
发生上下文切换的原因
工作线程数量高于 CPU 核数
上下文切换的消耗
进程是操作系统的伟大发明之一,对应用程序屏蔽了 CPU 调度、内存管理等硬件细节,而抽象出一个进程的概念,让应用程序专心于实现自己的业务逻辑既可,而且在有限的 CPU 上可以“同时”进行许多个任务。但是它为用户带来方便的同时,也引入了一些额外的开销。如下图,在进程运行中间的时间里,虽然 CPU 也在忙于干活,但是却没有完成任何的用户工作,这就是进程机制带来的额外开销。

在进程 A 切换到进程 B 的过程中,先保存 A 进程的上下文,以便于等 A 恢复运行的时候,能够知道 A 进程的下一条指令是啥。然后将要运行的 B 进程的上下文恢复到寄存器中。这个过程被称为上下文切换。上下文切换开销在进程不多、切换不频繁的应用场景下问题不大。但是现在 Linux 操作系统被用到了高并发的网络程序后端服务器。在单机支持成千上万个用户请求的时候,这个开销就得拿出来说道说道了。因为用户进程在请求 Redis、Mysql 数据等网络 IO 阻塞掉的时候,或者在进程时间片到了,都会引发上下文切换。

一个简单的进程上下文切换开销测试实验
废话不多说,我们先用个实验测试一下,到底一次上下文切换需要多长的 CPU 时间!实验方法是创建两个进程并在它们之间传送一个令牌。其中一个进程在读取令牌时就会引起阻塞。另一个进程发送令牌后等待其返回时也处于阻塞状态。如此往返传送一定的次数,然后统计他们的平均单次切换时间开销。 具体的实验代码参见test04
Before Context Switch Time1565352257 s, 774767 us
After Context SWitch Time1565352257 s, 842852 us
每次执行的时间会有差异,多次运行后平均每次上下文切换耗时 3.5us 左右。当然了这个数字因机器而异,而且建议在实机上测试。
前面我们测试系统调用的时候,最低值是 200ns。可见,上下文切换开销要比系统调用的开销要大。系统调用只是在进程内将用户态切换到内核态,然后再切回来,而上下文切换可是直接从进程 A 切换到了进程 B。显然这个上下文切换需要完成的工作量更大。
进程上下文切换开销都有哪些
那么上下文切换的时候,CPU 的开销都具体有哪些呢?开销分成两种,一种是直接开销、一种是间接开销。
直接开销就是在切换时,cpu 必须做的事情,包括:
- 1、切换页表全局目录
- 2、切换内核态堆栈
- 3、切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- ip(instruction pointer):指向当前执行指令的下一条指令
- bp(base pointer): 用于存放执行中的函数对应的栈帧的栈底地址
- sp(stack poinger): 用于存放执行中的函数对应的栈帧的栈顶地址
- cr3:页目录基址寄存器,保存页目录表的物理地址
- ……
- 4、刷新 TLB
- 5、系统调度器的代码执行
间接开销主要指的是虽然切换到一个新进程后,由于各种缓存并不热,速度运行会慢一些。如果进程始终都在一个 CPU 上调度还好一些,如果跨 CPU 的话,之前热起来的 TLB、L1、L2、L3 因为运行的进程已经变了,所以以局部性原理 cache 起来的代码、数据也都没有用了,导致新进程穿透到内存的 IO 会变多。 其实我们上面的实验并没有很好地测量到这种情况,所以实际的上下文切换开销可能比 3.5us 要大。
想了解更详细操作过程的同学请参考《深入理解 Linux 内核》中的第三章和第九章。
一个更为专业的测试工具-lmbench
lmbench 用于评价系统综合性能的多平台开源 benchmark,能够测试包括文档读写、内存操作、进程创建销毁开销、网络等性能。使用方法简单,但就是跑有点慢,感兴趣的同学可以自己试一试。 这个工具的优势是是进行了多组实验,每组 2 个进程、8 个、16 个。每个进程使用的数据大小也在变,充分模拟 cache miss 造成的影响。我用他测了一下结果如下:
-------------------------------------------------------------------------
Host OS 2p/0K 2p/16K 2p/64K 8p/16K 8p/64K 16p/16K 16p/64K
ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw
--------- ------------- ------ ------ ------ ------ ------ ------- -------
bjzw_46_7 Linux 2.6.32- 2.7800 2.7800 2.7000 4.3800 4.0400 4.75000 5.48000
lmbench 显示的进程上下文切换耗时从 2.7us 到 5.48 之间。
线程上下文切换耗时
前面我们测试了进程上下文切换的开销,我们再继续在 Linux 测试一下线程。看看究竟比进程能不能快一些,快的话能快多少。
在 Linux 下其实本并没有线程,只是为了迎合开发者口味,搞了个轻量级进程出来就叫做了线程。轻量级进程和进程一样,都有自己独立的 task_struct 进程描述符,也都有自己独立的 pid。从操作系统视角看,调度上和进程没有什么区别,都是在等待队列的双向链表里选择一个 task_struct 切到运行态而已。只不过轻量级进程和普通进程的区别是可以共享同一内存地址空间、代码段、全局变量、同一打开文件集合而已。
同一进程下的线程之所有 getpid()看到的 pid 是一样的,其实 task_struct 里还有一个 tgid 字段。 对于多线程程序来说,getpid()系统调用获取的实际上是这个 tgid,因此隶属同一进程的多线程看起来 PID 相同。
我们用一个实验来测试一下test06。其原理和进程测试差不多,创建了 20 个线程,在线程之间通过管道来传递信号。接到信号就唤醒,然后再传递信号给下一个线程,自己睡眠。 这个实验里单独考虑了给管道传递信号的额外开销,并在第一步就统计了出来。
# gcc -lpthread main.c -o main
0.508250
4.363495
每次实验结果会有一些差异,上面的结果是取了多次的结果之后然后平均的,大约每次线程切换开销大约是 3.8us 左右。从上下文切换的耗时上来看,Linux 线程(轻量级进程)其实和进程差别不太大。
Linux 相关命令
既然我们知道了上下文切换比较的消耗 CPU 时间,那么我们通过什么工具可以查看一下 Linux 里究竟在发生多少切换呢?如果上下文切换已经影响到了系统整体性能,我们有没有办法把有问题的进程揪出来,并把它优化掉呢?
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 595504 5724 190884 0 0 295 297 0 0 14 6 75 0 4
5 0 0 593016 5732 193288 0 0 0 92 19889 29104 20 6 67 0 7
3 0 0 591292 5732 195476 0 0 0 0 20151 28487 20 6 66 0 8
4 0 0 589296 5732 196800 0 0 116 384 19326 27693 20 7 67 0 7
4 0 0 586956 5740 199496 0 0 216 24 18321 24018 22 8 62 0 8
或者是
# sar -w 1
proc/s
Total number of tasks created per second.
cswch/s
Total number of context switches per second.
11:19:20 AM proc/s cswch/s
11:19:21 AM 110.28 23468.22
11:19:22 AM 128.85 33910.58
11:19:23 AM 47.52 40733.66
11:19:24 AM 35.85 30972.64
11:19:25 AM 47.62 24951.43
11:19:26 AM 47.52 42950.50
......
上图的环境是一台生产环境机器,配置是 8 核 8G 的 KVM 虚机,环境是在 nginx+fpm 的,fpm 数量为 1000,平均每秒处理的用户接口请求大约 100 左右。其中cs 列表示的就是在 1s 内系统发生的上下文切换次数,大约 1s 切换次数都达到 4W 次了。粗略估算一下,每核大约每秒需要切换 5K 次,则 1s 内需要花将近 20ms 在上下文切换上。要知道这是虚机,本身在虚拟化上还会有一些额外开销,而且还要真正消耗 CPU 在用户接口逻辑处理、系统调用内核逻辑处理、以及网络连接的处理以及软中断,所以 20ms 的开销实际上不低了。
那么进一步,我们看下到底是哪些进程导致了频繁的上下文切换?
# pidstat -w 1
11:07:56 AM PID cswch/s nvcswch/s Command
11:07:56 AM 32316 4.00 0.00 php-fpm
11:07:56 AM 32508 160.00 34.00 php-fpm
11:07:56 AM 32726 131.00 8.00 php-fpm
......
由于 fpm 是同步阻塞的模式,每当请求 Redis、Memcache、Mysql 的时候就会阻塞导致 cswch/s 自愿上下文切换,而只有时间片到了之后才会触发 nvcswch/s 非自愿切换。可见 fpm 进程大部分的切换都是自愿的、非自愿的比较少。
如果想查看具体某个进程的上下文切换总情况,可以在/proc 接口下直接看,不过这个是总值。
grep ctxt /proc/32583/status
voluntary_ctxt_switches: 573066
nonvoluntary_ctxt_switches: 89260
本节结论
上下文切换具体做哪些事情我们没有必要记,只需要记住一个结论既可,测得作者开发机上下文切换的开销大约是 2.7-5.48us 左右,你自己的机器可以用我提供的代码或工具进行一番测试。 lmbench 相对更准确一些,因为考虑了切换后 Cache miss 导致的额外开销。
参考文献
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.