Filesystem
概述
参考:
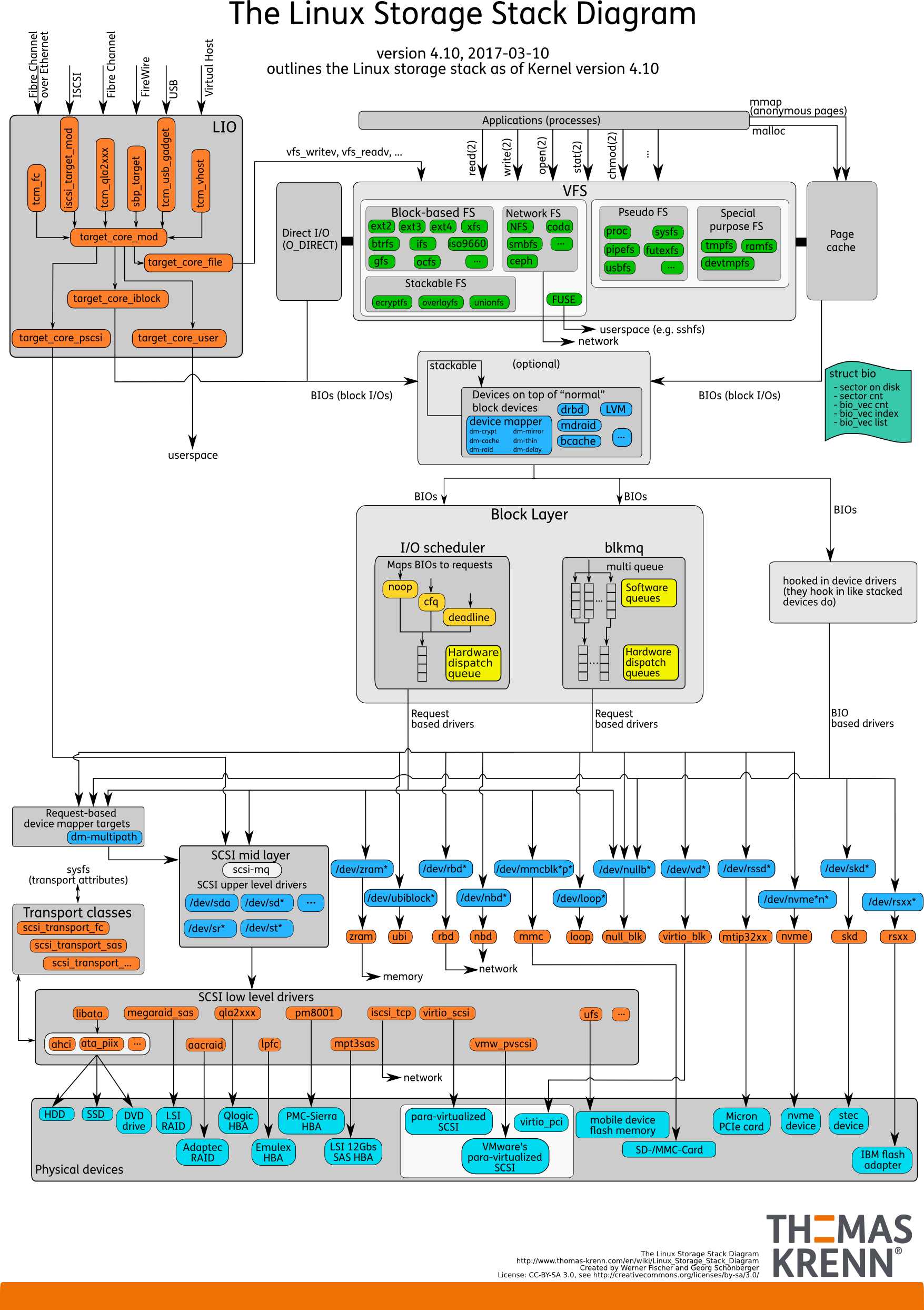
图片来源: https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
从上面的结构可以看到,文件系统的作用就是用来接收用户的操作,并将数据保存到物理硬盘的。可以想见,如果没有文件系统帮助用户操作,那么人们又怎么能将数据保存到存储设备上呢~
File System(文件系统,简称 FS) 是一种对存储设备上的数据,进行组织管理的机制。组织方式的不同,就会形成不同的文件系统。
如果没有文件系统,放置在存储介质中的数据将是一个庞大的数据主体,无法分辨一个数据在哪里停止以及下一个数据在哪里开始。通过将数据分成多个部分并给每个部分命名,可以轻松地隔离和识别数据。每组数据称为 File(文件)。所以,用于管理这些文件及其名称的结构和逻辑规则,称为 File System(文件系统)。
什么是 File(文件)
详见《文件管理》章节
文件组织结构
文件管理详解见 文件管理
为了方便管理,Linux 的文件系统为每个文件都分配了两个数据结构。
- index node(索引节点,简称 inode) # 记录文件的元数据。inode 编号、文件大小、访问权限、修改日期、数据的位置等。
- inode 和文件一一对应,它跟文件内容一样,都会被持久化到存储的磁盘中。所以inode 同样占用磁盘空间。
- inode 包含文件的元数据,具体来说有以下内容:
- 文件的字节数
- 文件拥有者的 User ID
- 文件的 Group ID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:ctime 指 inode 上一次变动的时间,mtime 指文件内容上一次变动的时间,atime 指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个 inode
- 文件数据 block 的位置
- directory entry(目录项,简称 dentry) # 记录文件的名字、inode 指针、与其他目录项的关联关系。
- 多个关联的目录项,就构成了文件系统的目录结构(一个层次化的树形结构)。不过,不同于 inode,目录项是由内核维护的一个内存数据结构,所以通常也被叫做 dentries(目录项缓存)。
这个层次化的树形结构就像下图一样:
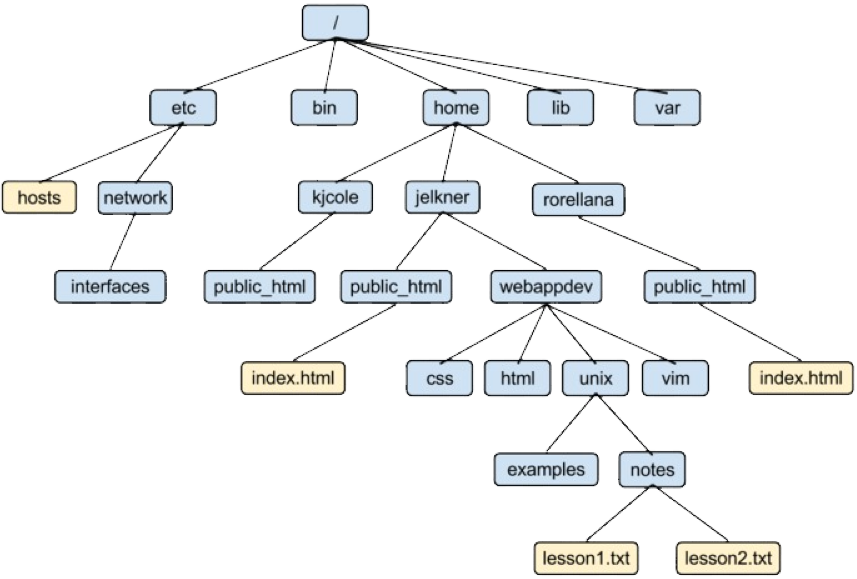
注意:目录项缓存记录在 slab 中,当我们使用 find 命令时,slab 中的 dentry 缓存就会增大;打开文件过多,slab 中的 dentry 缓存也会增大。
inode 是每个文件的唯一标志,而 dentry 维护的正是文件系统的树状结构。dentry 与 inode 的关系是多对一(可以简单理解为一个文件可以有多个别名)
下面用一个形象点的白话来描述这些概念,假如现在系统中有如下目录结构
~]# tree --inodes
.
├── [ 2218] dir_1 # 这是目录类型的文件
│ ├── [ 2235] file_1 # 这是普通类型的文件
│ └── [ 2236] file_2
├── [269167463] dir_2
│ └── [269167464] file_3
└── [537384536] dir_3
├── [ 2235] fie_1_ln
└── [537384537] file_4
3 directories, 5 files
可以这么描述上述看到的内容:dir_1、file_1、dir_2 这些名称都是 dentry 中的文件名,[] 中的数字是 inode 号,每个 dentry 都会与 inode 关联。其中 file_1 和 file_1_ln 的 inode 相同,但是 dentry 不同,这就对应了 dentry 与 inode 是多对一的关系。而哪些文件在哪个目录中,则是由每个文件的 dentry 中的关联关系来决定。比如 dir_1 目录中,包含了 file_1 和 file_2 文件。
索引节点和目录项记录了文件的元数据,以及文件间的目录关系,那么具体来说,文件数据到底是怎么存储的呢?是不是直接写到磁盘中就好了呢?
实际上,磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。

注意:
- dentry 本身只是一个存储在内存中的缓存,而 inode 则是存储在磁盘中的数据。由于内存的 Buffer 和 Cache 原理,所以 inode 也会缓存到内存中,以便加速文件的访问。
- 磁盘在执行文件系统格式化时,会被分成三个存储区域,超级快、索引节点区、数据区块
- 超级块 # 存储整个文件系统的状态
- 索引节点区 # 存储 inode
- 数据区块 # 存储文件数据
- 我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块 # 当文件系统挂载时进入内存;
- 索引节点区 # 当文件被访问时进入内存
dentry、inode、逻辑块以及超级块构成了 Linux 文件系统的四大基本要素。
小结
通过上面的描述,文件在文件系统中,也就可以归纳为两个部分
- 指针部分 # 指针位于文件系统的元数据中,在将数据删除后,这个指针就从元数据中清除了(元数据其实就是上文的 inode 与 dentry)。
- 数据部分 # 文件的具体内容,存储在磁盘中。
平时我们在删除数据时,其实仅仅从元数据中删除了数据对应的指针。当指针被删除时,其原本占用的空间就可以被覆盖并写入新内容。
常见问题
- 这也是为什么我们可以恢复数据的原因,只要旧数据还没被覆盖,就依然可以获取到。
- 有时候在删除文件时,会发现并没有释放空间,也是同样的道理,当某个进程持续写入内容时,如果强制删除了文件,由于进程锁定文件对应的指针部分并不会从元数据中清除,而由于指针并未删除,系统内核就默认文件并未删除,因此查询文件系统空间时,显示空间并未释放。可以通过 lsof 命令筛选 deleted 查找这些有问题的文件。
Virtual File System(虚拟文件系统)
参考:
Virtual File System(虚拟文件系统,简称 VFS) 是 Linux 为了支持多种多样的文件系统,在用户空间进程和文件系统中间,引入的一个抽象层。VFS 的目的是运行客户端应用程序以统一的方式访问不同类型的文件系统。VFS 定义了一组所有文件系统都支持的数据结构和标准 API。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互即可,而不需要关系底层各种文件系统的实现细节。
比如不同文件系统的调用函数不一样,如果没有 VFS ,那么在使用的时候,就需要为特定的文件系统,编写不同的调用方式,非常繁琐复杂。
比如 VFS 可以用来弥合 Windows、MacOS、Unix 文件系统中的差异,以便应用程序可以访问那些类型的本地文件系统上的文件,而不必知道它们正在访问哪种文件系统。

举个例子,Linux 用户程序可以通过read() 来读取ext4、NFS、XFS等文件系统的文件,也可以读取存储在SSD、HDD等不同存储介质的文件,无须考虑不同文件系统或者不同存储介质的差异。
通过 VFS 系统,Linux 提供了通用的系统调用,可以跨越不同文件系统和介质之间执行,极大简化了用户访问不同文件系统的过程。另一方面,新的文件系统、新类型的存储介质,可以无须编译的情况下,动态加载到 Linux 中。
“一切皆文件"是 Linux 的基本哲学之一,不仅是普通的文件,包括目录、字符设备、块设备、套接字等,都可以以文件的方式被对待。实现这一行为的基础,正是 Linux 的虚拟文件系统机制。
VFS 之所以能够衔接各种各样的文件系统,是因为它抽象了一个通用的文件系统模型,定义了通用文件系统都支持的、概念上的接口。新的文件系统只要支持并实现这些接口,并注册到 Linux 内核中,即可安装和使用。
再举个例子,比如 Linux 写一个文件:
int ret = write(fd, buf, len);
调用了 write() 系统调用,它的过程简要如下:
- 首先,勾起 VFS 通用系统调用
sys_write()处理。 - 接着,
sys_write()根据fd找到所在的文件系统提供的写操作函数,比如op_write()。 - 最后,调用
op_write()实际的把数据写入到文件中。
操作示意图如下:

文件系统类型
参考:
可以通过 /proc/filesystems 文件查看当前内核所支持的文件系统类型
~]# cat /proc/filesystems
nodev sysfs
nodev tmpfs
nodev proc
...
nodev cgroup2
nodev tmpfs
nodev devtmpfs
nodev configfs
...
xfs
...
ext4
...
- 第一列说明文件系统是否需要挂载在一个块设备上
- nodev 表明本行的文件系统类型不需要挂接在块设备上。凡是没有 nodev 的类型,通常来说都是磁盘文件系统。
- 第二列是内核支持的文件系统类型。
当系统中安装了某个文件系统的驱动,则该文件内容也会有增加,比如我安装了 nfs-utils 包,则该文件还会增加 nfs 行。
按照存储位置分类
- Disk file systems(磁盘文件系统)
- 基于磁盘的文件系统,也就是把数据直接存储到计算机本地挂载磁盘中。常见的 ext4、xfs 等,都是这类文件系统
- Network File Systems(网络文件系统)
- 网络文件系统是充当远程文件访问协议的客户端的文件系统,提供对服务器上文件的访问。 使用本地接口的程序可以透明地创建,管理和访问远程网络连接计算机中的分层目录和文件。 网络文件系统的示例包括 NFS,AFS,SMB 协议的客户端,以及 FTP 和 WebDAV 的类似于文件系统的客户端。
- Distributed File System(分布式文件系统) # 使用网络协议的分布式文件系统也属于网络文件系统的一种。
- Special-purpose File Systems(特殊目的文件系统) # 特殊的文件系统将操作系统的非文件元素显示为文件,以便可以使用文件系统 API 对其进行操作。 这种文件系统一般都是基于内存的,不需要任何磁盘为其分配存储空间,但会占用内存。
文件系统的使用
和 DOS 等操作系统不同,Linux 操作系统中文件系统并不是由驱动器号或驱动器名称(如 A: 或 C: 等)来标识的。Linux 操作系统将独立的文件系统组合成了一个层次化的树形结构,并且由一个单独的实体代表这一文件系统。
Linux 将新的文件系统通过 Mount(挂载) 操作将其挂载到某个目录上,从而让不同的文件系统结合成为一个整体。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录/,在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
文件系统 I/O
把文件系统挂载到挂载点后,就可以通过挂载点访问它管理的文件了。 VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
就比如 cat 命令,首先调用 openat() 打开一个文件,然后调用 read() 读取文件内容,最后调用 write() 将内容输出到控制台的标准输出中
~]# strace -e openat,read,write cat /root/test
......
openat(AT_FDCWD, "/root/test", O_RDONLY) = 3
read(3, "Test I/O for File System", 131072) = 24
write(1, "Test I/O for File System", 24Test I/O for File System) = 24
......
# 代码中的方法如下:open() 与 openat() 这两个调用效果一样。
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
文件读写方式的各种差异,导致 I/O 的分类多种多样。最常见的有,缓冲与非缓冲 I/O、直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O 等。
缓冲与非缓冲 I/O
根据是否利用标准库缓存
- 缓冲 I/O # 利用标准库缓存来加速文件的访问,而标准库内部再通过系统调用访问文件
- 非缓冲 I/O # 直接通过系统调用来访问文件,不再经过标准库缓存。
注意,这里所说的“缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。 无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
直接与非直接 I/O
根据是否利用操作系统的页缓存
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接 I/O。 不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
阻塞与非阻塞 I/O
根据应用程序是否阻塞自身运行
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
同步与异步 I/O
根据是否等待响应结果
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
举个例子,在操作文件时,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。 再比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。 你可能发现了,这里的好多概念也经常出现在网络编程中。比如非阻塞 I/O,通常会跟 select/poll 配合,用在网络套接字的 I/O 中。 你也应该可以理解,“Linux 一切皆文件”的深刻含义。无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的 VFS 接口来访问。
总结

在前面我们知道了,I/O 是分为两个过程的:
- 数据准备的过程
- 数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。 异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
用故事去理解这几种 I/O 模型
举个你去饭堂吃饭的例子,你好比用户程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
基于非阻塞的 I/O 多路复用好比,你去饭堂吃饭,发现有一排窗口,饭堂阿姨告诉你这些窗口都还没做好菜,等做好了再通知你,于是等啊等(select 调用中),过了一会阿姨通知你菜做好了,但是不知道哪个窗口的菜做好了,你自己看吧。于是你只能一个一个窗口去确认,后面发现 5 号窗口菜做好了,于是你让 5 号窗口的阿姨帮你打菜到饭盒里,这个打菜的过程你是要等待的,虽然时间不长。打完菜后,你自然就可以离开了。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.