Linux 网络流量控制
概述
参考:
在计算机网络中,Traffic Control(流量控制,简称 TC) 系统可以让服务器,像路由器一样工作,这也是 SDN(软件定义网路) 中重要的组成部分。通过精准的流量控制,可以让服务器减少拥塞、延迟、数据包丢失;实现 NAT 功能、控制带宽、阻止入侵;等等等等。
Traffic Control(流量控制) 在不同的语境中有不同的含义,可以表示一整套完整功能的系统、也可以表示为一种处理网络数据包的行为
背景
众所周知,在互联网诞生之初都是各个高校和科研机构相互通讯,并没有网络流量控制方面的考虑和设计,TCP/IP 协议的原则是尽可能好地为所有数据流服务,不同的数据流之间是平等的。然而多年的实践表明,这种原则并不是最理想的,有些数据流应该得到特别的照顾, 比如,远程登录的交互数据流应该比数据下载有更高的优先级。
针对不同的数据流采取不同的策略,这种可能性是存在的。并且,随着研究的发展和深入, 人们已经提出了各种不同的管理模式。IETF 已经发布了几个标准, 如综合服务(Integrated Services)、区分服务(Diferentiated Services)等。其实,Linux 内核从 2 2 开始,就已经实现了相关的 Traffic Control(流量控制) 功能。
实际上,流量控制系统可以想象成 Message Queue(消息队列) 的功能。都是为了解决数据量瞬间太大导致处理不过来的问题。
Traffic Control 的实现
想要实现 Traffic Control(流量控制) 系统,通常需要以下功能中的一个或多个:
- Queuing(队列) # 每个进出服务器的数据包,都排好队逐一处理。
- Hook(钩子) # 也可以称为DataPath。用于拦截进出服务器的每个数据包,并对数据包进行处理。
- 每种实现流量控制的程序,在内核中添加的 Hook 的功能各不相同,Hook 的先后顺序也各不相同,甚至可以多个 Traffic Control 共存,然后在各自的 Hook 上处理数据包
- Connection Tracking(连接跟踪) # 每个被拦截到的数据包,都需要记录其信息以跟踪他们。
通过对数据包进行 Queuing(排队),我们可以决定数据的发送方式。我们只能对发送的数据进行整形。
互联网的工作机制决定了接收端无法直接控制发送端的行为。这就像你家的邮箱一样:除非能联系到所有人(告诉他们未经同意不要寄信给你),否则 你无法控制别人寄多少东西过来。
但与实际生活不同的是,互联网基于 TCP/IP 协议栈,这多少会带来一些帮助。TCP/IP 无法提前知道两台主机之间的网络带宽,因此开始时它会以越来越快的速度发送数据,直到开始出现丢包,这时它知道已经没有可用空间来存储这些待发送的包了,因此就会 降低发送速度。TCP/IP 的实际工作过程比这个更智能一点,后面会再讨论。
这就好比你留下一半的信件在实体邮箱里不取,期望别人知道这个状况后会停止给你寄新的信件。 但不幸的是,这种方式只对互联网管用,对你的实体邮箱无效 :-)
如果内网有一台路由器,你希望限制某几台主机的下载速度,那你应该找到发送数据到这些主机的路由器内部的接口,然后在这些 路由器内部接口上做 整流(traffic shaping,流量整形)。
此外,还要确保链路瓶颈(bottleneck of the link)也在你的控制范围内。例如,如果网卡是 100Mbps,但路由器的链路带宽是 256Kbps,那首先应该确保不要发送过多数据给路由 器,因为它扛不住。否则,链路控制和带宽整形的决定权就不在主机侧而到路由器侧了。要达到限速目的,需要对 “发送队列” 有完全的把控(”own the queue”),这里的 “发送队列” 也就是 slowest link in the chain(整条链路上最慢的一段)。 幸运的是,大多数情况下这个条件都是能满足的。
再用白话一点的描述:其实所谓的控制发送端行为,这种描述中的 发送端 是一个相对概念,在 Linux 每个 Hook 发给下一个 Hook 的时候,前一个 Hook 就是下一个 Hook 的发送端,所以,控制发送端行为,就是在第一个 Hook 收到数据包时,控制他发給下一个 Hook 或应用程序的数据包的行为。
实现流量控制系统的具体方式
流量控制系统的行为通常都是在内核中完成的,所有一般都是将将官代码直接写进内核,或者使用模块加载进内核,还有新时代的以 BPF 模式加在进内核。
- Netfilter
- 通过 iptables、nftables 控制 Netfilter 框架中的 Hook 行为
- TC 模块
- 通过 tc 二进制程序控制 Hook 行为
- BPF 流量控制机制
- 待整理,暂时不知道 Linux 中有什么会基于 BPF 的应用程序。
- 但是有一个 Cilium 程序,是基于 BPF 做的,只不过只能部署在 Kubernetes 集群中。
- 待整理,暂时不知道 Linux 中有什么会基于 BPF 的应用程序。
如下图所示,每种实现方式,都具有不同的 Hook:
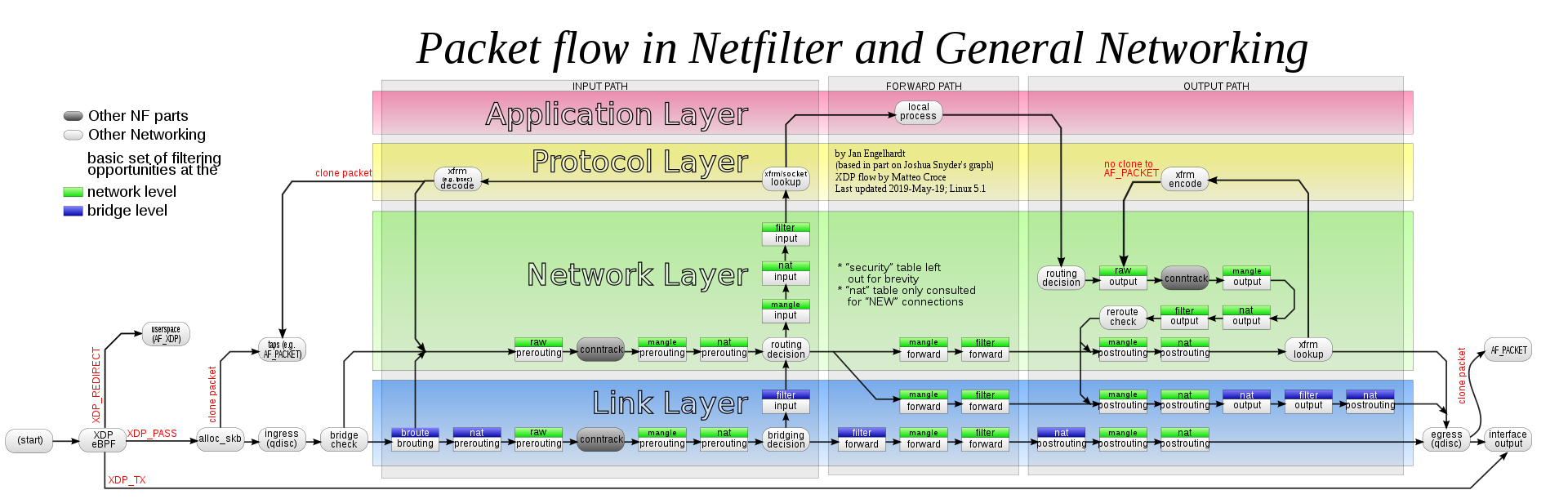
- 其中 Netfilter 框架具有最庞大的 Hook 以及 DataPath,上图中间带颜色的部分,基本都是 Netfilter 框架可以处理流量的地方
- 包括 prerouting、input、forward、output、postrouting 这几个默认的 Hook
- ingress(qdisc)、egress(qdisc) 属于 TC 模块的 Hook
- 其他的则是 eBPF 添加的新 Hook
当然,随着 eBPF 的兴起,Netfilter 这冗长的流量处理过程,被历史淘汰也是必然的趋势~~~~
各种流量控制方法的区别
kube-proxy 包转发路径
从网络角度看,使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图所示:
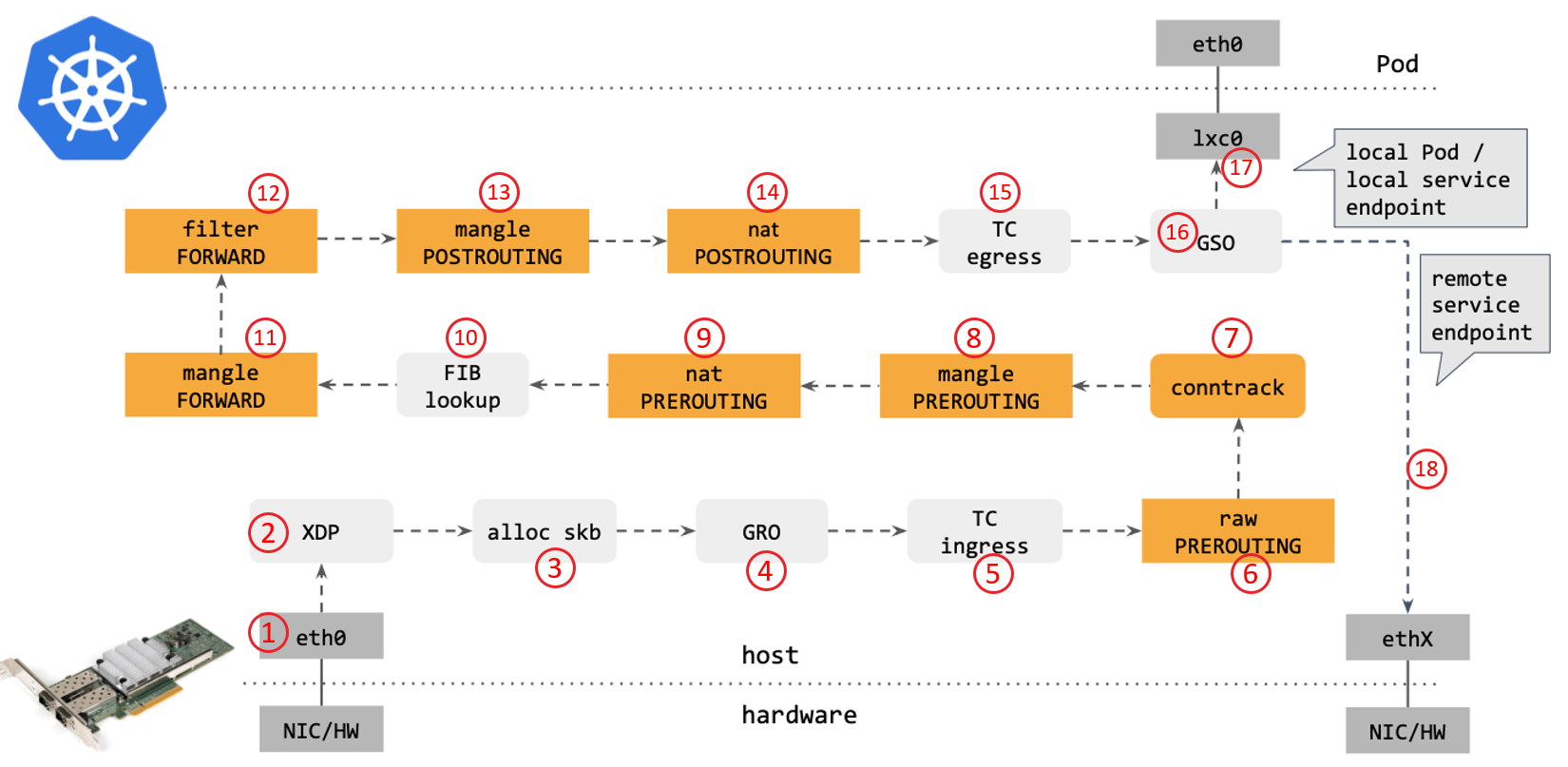
步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的
skb(包的内核结构体表示),然后 送到内核协议栈。 - 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在
PREROUTINGhook 点处理rawtable 里的 iptables 规则。 - 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在
PREROUTINGhook 点处理mangletable 的 iptables 规则。 - Netfilter:在
PREROUTINGhook 点处理nattable 的 iptables 规则。 - 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在
FORWARDhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
FORWARDhook 点处理filtertable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理nattable 里的 iptables 规则。 - 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去。
相关阅读,有助于理解以上过程:
译者注。
Cilium eBPF 包转发路径
作为对比,再来看下 Cilium eBPF 中的包转发路径:
建议和 (译) 深入理解 Cilium 的 eBPF 收发包路径(datapath) 对照看。 译者注。
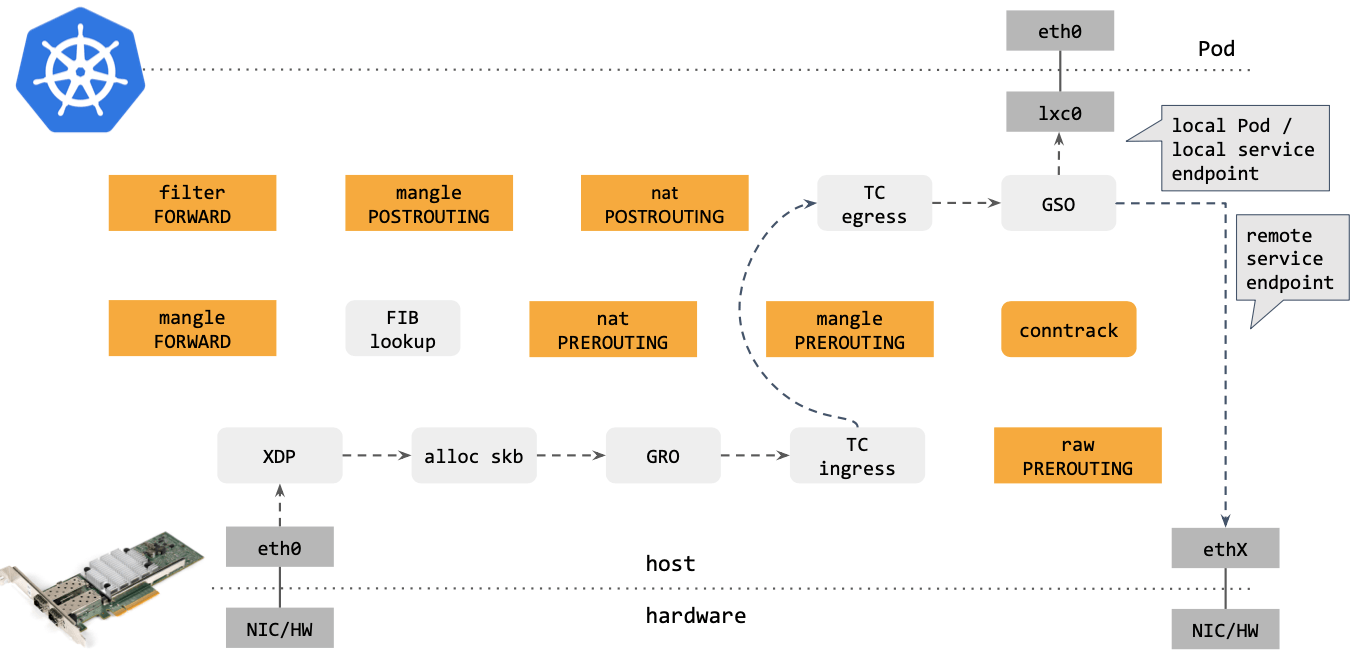
对比可以看出,Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
去掉那些不用的框之后,Cilium eBPF datapath 长这样:
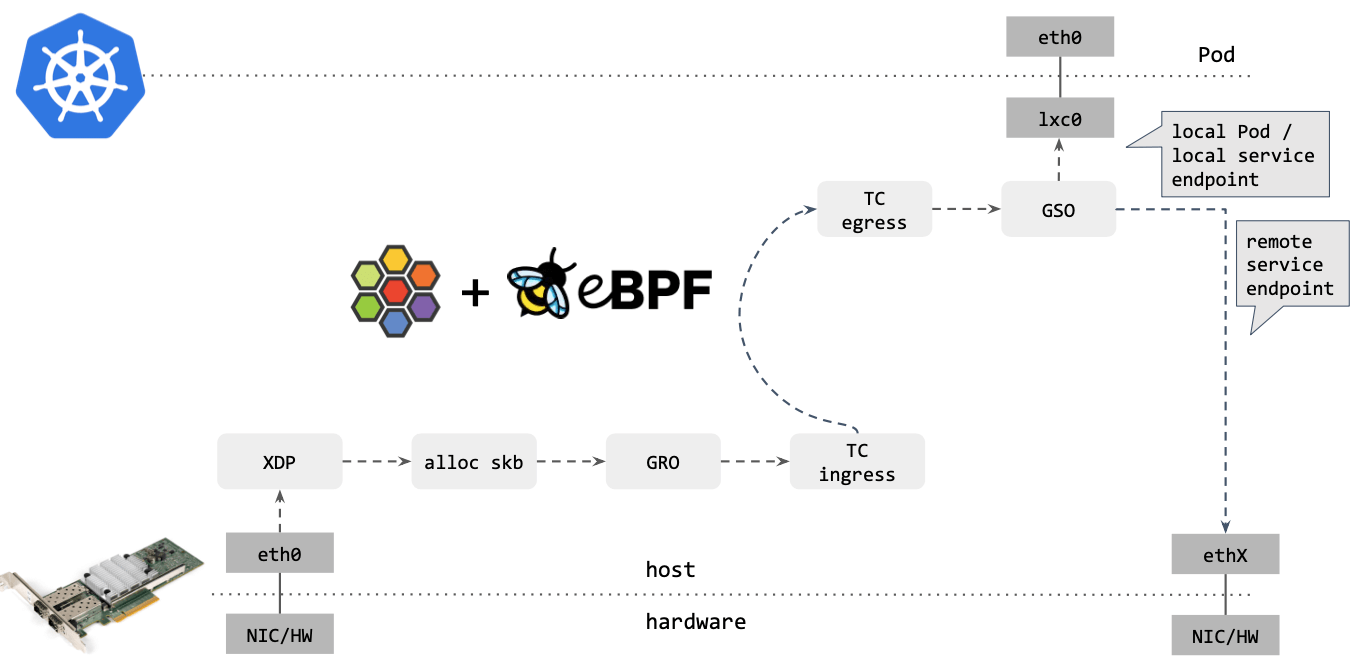
Cilium/eBPF 还能走的更远。例如,如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP 框中完成包的重定向(收包 1->2,在步骤 2 中对包 进行修改,再通过 2->1 发送出去),将其发送出去,如下图所示:

可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb) 就被转 发出去了,性能可想而知。
XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,而无需将包送 到复杂的协议栈进行处理,因此处理代价很小,速度极快。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.