Netfilter
概述
参考:
Netfilter 是 Linux 操作系统核心层内部的一个数据包处理模块集合的统称, 是一种流量控制系统。一种网络筛选系统,对数据包进入以及出去本机进行的一些控制与管理。

Netfilter 功能的所有模块可以通过下图所示的目录进行查找,其中还包括 ipvs 等。
~]# find /usr/lib/modules/$(uname -r)/kernel -name netfilter -exec realpath {} \;
/usr/lib/modules/5.15.0-102-generic/kernel/net/bridge/netfilter
/usr/lib/modules/5.15.0-102-generic/kernel/net/netfilter
/usr/lib/modules/5.15.0-102-generic/kernel/net/ipv6/netfilter
/usr/lib/modules/5.15.0-102-generic/kernel/net/ipv4/netfilter
Netfilter 项目支持如下功能
- 网络地址转换(Network Address Translate)
- 数据包过滤
- 数据包日志记录
- 用户空间数据包队列
- 其他数据包处理
- 等等
Netfilter Hooks 是 Linux 内核中的一个框架,它会让 Netfilter 的模块在 Linux 网络堆栈的不同位置注册回调函数。然后,为遍历 Linux 网络堆栈中相应 Hook 的每个数据包调用已注册的回调函数。
- 用白话说:内核加入了 Netfilter 模块后,每个数据包进来之后,都会经过五个 Hooks 点来处理,以便决定每个数据包的走向。
Hooks
hooks function(钩子函数) 是 Linux 网络栈中的流量检查点。所有流量通过网卡进入内核或从内核出去都会调用 Hook 函数来进行检查,并根据其规则进行过滤。Netfilter 框架中一共有 5 个 Hook,这些 Hooks 组成了下文定义的“五链”。
- 当一个数据包在其中一个 Hook 上匹配到自己的规则后,则会进入下一个 Hook 寻找匹配自身的规则,直到将 5 个 Hooks 挨个匹配一遍。
- 可以把 Hooks 想象成地铁站的闸机,通过闸机的人,就是数据流量,这个能不能从闸机过去,则看闸机对这个人身份验证的结果,是放行还是阻止
iptabeles/nftables
工作于用户空间的管理工具,对 5 个 hook 进行规则管理,iptabels/nftables 程序只是把设定好的规则写进 hook 中
Netfilter 所设置的规则是存放在内核内存中的,Iptables 是一个应用层(Ring3)的应用程序,它通过 Netfilter 放出的接口来对存放在内核内存中的 Xtables(Netfilter 的配置表)进行修改(这是一个典型的 Ring3 和 Ring0 配合的架构)
Chain(五链)
把每个 Hook 上的规则都串起来类似于一条链子,所以称为链,一共 5 个 Hook,所以有 5 个 Chain。每个规则都是由“源 IP、目标 IP、端口、目标”等信息组合起来的。(i.e 对从哪来的或者到哪去的 IP 的哪个端口,要执行什么动作或‘引用什么 Chain 来对这个数据包执行什么动作’)
- PREROUTING 链 # 路由前,处理刚到达本机并在路由转发前的数据包。它会转换数据包中的目标 IP 地址(destination ip address),通常用于 DNAT(destination NAT)。处理完成之后分成两种情况,目的 IP 为本机网口则 INPUT,目的 IP 非本机网口则 FORWARD
- INPUT 链 # 进入,处理来自外部的数据。
- FORWARD 链 # 转发,将数据转发到本机的其他网络设备上。(需要开启 linux 的 IP 转发功能 net.ipv4.ip_forward=1 才会进入该流程;就算 ping 的是本机的其余网络设备上的 IP,也是由接收该数据包的网络设备进行回应),FORWARD 的行为类似于路由器,系统中每个网络设备就是路由器上的每个端口,只有打开转发功能,才可以把数据包路由到其余端口上。
- 虚拟化或容器技术中,如果一台设备中有多个网段,一般都会打开转发功能,以实现不同网段路由互通的效果。
- 或者服务器作为 VPN 使用时,由于不同网络设备所属网段不同,也需要打开转发功能。
- 等等
- OUTPUT 链 # 出去,处理向外发送的数据。
- POSTROUTING 链 # 路由后,处理即将离开本机的数据包。它会转换数据包中的源 IP 地址(source ip address),通常用于 SNAT(source NAT)。(该路由是通过 Linux 中定义的 route 规则发送的,与内核的 ip_forward 无关)
- 自定义链 # 用户自己定义的链,不会调用系统 Hook,而是由系统默认的 5 个链在 target 中定义引用
规则(Rule)匹配(Match)
(规则的匹配条件)匹配的用法详见:Iptables
规则,需要有具体的内容才能称为规则,所以 Match 就是规则中的具体内容。
每条链上的规则,需要对流量进行匹配后才能对该流量进行相应的处理,匹配内容包括“数据包的源地址、目标地址、协议、目标等”,(e.g.这个数据使用哪个协议从哪来的到哪去的目标是什么)
]# ls -al /usr/lib/x86_64-linux-gnu/xtables
total 2184
......
-rw-r--r-- 1 root root 14784 Jan 17 05:14 libebt_dnat.so
-rw-r--r-- 1 root root 22968 Jan 17 05:14 libebt_ip6.so
-rw-r--r-- 1 root root 27064 Jan 17 05:14 libebt_ip.so
......
-rw-r--r-- 1 root root 14784 Jan 17 05:14 libebt_snat.so
-rw-r--r-- 1 root root 14776 Jan 17 05:14 libebt_stp.so
-rw-r--r-- 1 root root 14776 Jan 17 05:14 libebt_vlan.so
-rw-r--r-- 1 root root 14776 Jan 17 05:14 libip6t_ah.so
-rw-r--r-- 1 root root 14984 Jan 17 05:14 libip6t_DNAT.so
......
-rw-r--r-- 1 root root 19080 Jan 17 05:14 libipt_DNAT.so
......
-rw-r--r-- 1 root root 14968 Jan 17 05:14 libxt_ipvs.so
......
Match 功能的实现依赖于模块(类似于内核的模块),比如右图,可以使用命令 rpm -ql iptables | grep ".so" 查看都有哪些模块,其中的 XXX.so 就是各个功能的模块,大写字母是 target 所用的模块,小写字母是基本匹配与扩展匹配所用的模块
- 基本匹配:源地址、目标地址、协议、入流网卡、出流网卡
- 扩展匹配:用于对基本匹配的内容扩充,包括两类,普通的扩展匹配和基于
- 通用扩展匹配,可以直接使用。
- 基于基本匹配的扩展匹配。需要有基本匹配规则才可以使用。
- e.g.需要匹配某些端口,这类匹配必须基于 tcp 匹配规则上使用,否则无效(e.g.-p tcp -m tcp -m multiport –dport22,23,24)
- 目标(target):每个规则中的目标。即在每条链上对每个进出流量匹配上之后应该执行什么动作,Target 包括以下几种
- ACCEPT # 允许流量通过
- REJECT # 拒绝流量通过
- DROP # 丢弃,不响应,发送方无法判断是被拒绝
- RETURN # 返回调用链
- MARK # 做防火墙标记
- 用于 nat 表的 target
- DNAT|SNAT #{目的|源}地址转换
- REDIRECT # 端口重定向
- MASQUERADE # 地址伪装类似于 SNAT,但是不用指明要转换的地址,而是自动选择要转换的地址,用于外部地址不固定的情况
- 用于 raw 表的 target
- NOTRACK # raw 表专用的 target,用于对匹配规则进行 notrack(不跟踪)处理
- LOG # 将数据包的相关信息记录日志,执行完该目标后,会继续匹配后面的规则
- 引用自定义链 # 直接使用“-j 自定义链的名称”即可,让基本 5 个 Chain 上匹配成功的数据包继续执行自定义链上的规则。
注意,这里面的路由指数据包在 Linux 本机内部路由
Linux 数据包路由原理、Iptables/netfilter 入门学习
数据流处理流程简介
注意:每个数据包在 CHAIN 中匹配到适用于自己的规则之后,则直接进入下一个 CHAIN,而不会遍历 CHAIN 中每条规则去挨个匹配适用于自己的规则。比如下面两种情况
INPUT 链默认 DROP,匹配第一条:目的端口是 9090 的数据 DROP,然后不再检查下一项,那么 9090 无法访问
-P INPUT DROP
-A INPUT -p tcp -m tcp --dport 9090 -j DROP
-A INPUT -p tcp -m tcp --dport 9090 -j ACCEPT
INPUT 链默认 DROP,匹配第一条目的端口是 9090 的数据 ACCEPT,然后不再检查下一条规则,则 9090 可以访问
-P INPUT DROP
-A INPUT -p tcp -m tcp --dport 9090 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 9090 -j DROP
匹配条件:根据协议报文特征指定
- 基本匹配条件
- 扩展匹配条件
处理动作:
- 内建处理机制
- 自定义处理机制
- 注意:自定义的链不会有流量经过,而是在主要的 5 链中引用自定义链上的规则,来实现对流量的处理
下图是从服务器外部进入网卡,再进入网络栈的数据流走向,如果直接是服务器内部服务生成的数据包进入网络栈,则不适用于该图
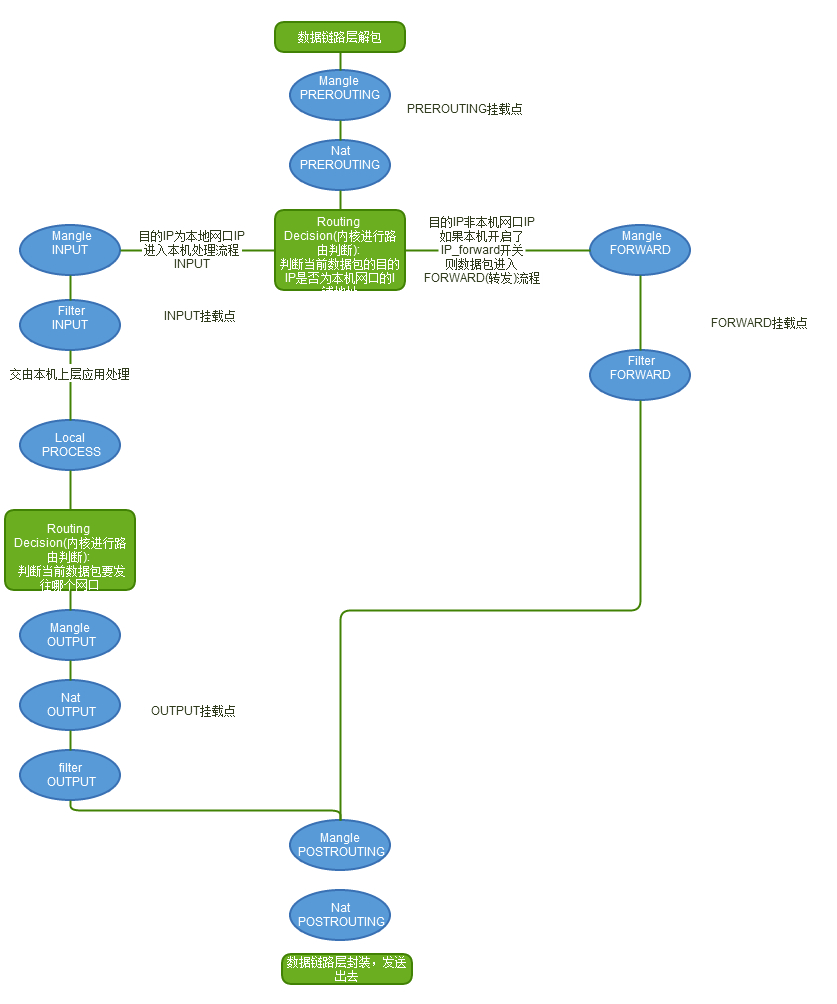
- 当一个数据包进入网卡时,数据包首先进入 PREROUTING 链,在 PREROUTING 链中我们有机会修改数据包的 DestIP(目的 IP),然后内核的"路由模块"根据"数据包目的 IP"以及"内核中的路由表"判断是否需要转送出去(注意,这个时候数据包的 DestIP 有可能已经被我们修改过了)
- 如果数据包就是进入本机的(即数据包的目的 IP 是本机的网口 IP),数据包就会沿着图向下移动,到达 INPUT 链。数据包到达 INPUT 链后,任何进程都会收到它
- 本机上运行的程序也可以发送数据包,这些数据包经过 OUTPUT 链,然后到达 POSTROTING 链输出(注意,这个时候数据包的 SrcIP 有可能已经被我们修改过了)
- 如果数据包是要转发出去的(即目的 IP 地址不再当前子网中),且内核允许转发,数据包就会向右移动,经过 FORWARD 链,然后到达 POSTROUTING 链输出(选择对应子网的网口发送出去)
出于安全考虑,Linux 系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的 ip 地址将包发往本机另一网卡,该网卡根据路由表继续发送数据包。这通常就是路由器所要实现的功能。
配置 Linux 系统的 ip 转发功能,首先保证硬件连通,然后打开系统的转发功能,less /proc/sys/net/ipv4/ip_forward,该文件内容为 0,表示禁止数据包转发,1 表示允许,将其修改为 1。可使用命令 echo "1" > /proc/sys/net/ipv4/ip_forward 修改文件内容。
NAT(Network Address Translation)网络地址转换
NAT 为了安全性而产生的,主要用来隐藏本地主机的 IP 地址
SNAT - Source 源地址转换,针对请求报文的源地址而言
当想访问外网的时候,把源地址转换,作用于 POSTROUTING 链
常用于内网私网地址转换成公网地址,比如家用路由器
DNAT - Destination 目的地址转换,针对请求报文的目标地址而言
当从外部访问某 IP 时,把目的 IP 转换,作用于 PREROUTING、FORWARD 链
把内网中的服务器发布到外网中去,
常用于公网访问一个公司的公网 IP,但是由私网 IP 来提供服务,比如 LVS 的 nat 模型
比如在公司内网中提供一个 web 服务,但是由于是私网地址,来自互联网的任何请求无法送达这台 web 服务器,这时候我们可以对外宣称公司的 web 服务在一个公网的 IP 地址上,但是公网的 IP 地址所在服务器上又没有提供 web 服务,这时候,来自外网访问的请求,全部 DNAT 成私网 IP,即可对外提供请求。
注意
由于 SNAT 与 DNAT 在描述的时候主要是都是针对请求报文而言的,那么当地址转换以后,响应报文响应的是转换后的地址,这时候就无法把响应请求送还给发起请求的设备了,这怎么办呢?这时候,同样需要一个地址转换,只不过通过 NAT 机制自行完成的,如何自动完成呢?这里面会有一个连接追踪机制,跟踪每一个数据连接(详见:Connnection Tracking(连接跟踪)),当响应报文到来的时候,根据连接追踪表中的信息记录的请求报文是怎么转换的相关信息,来对响应报文进行 NAT 转换。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.