Linux 文本处理
概述
参考:
文本处理三剑客:
- grep
- sed
- awk
cat - 用于把标准输入的内容输出到屏幕上
Note: 如果标准输入的内容是一个文件,那么就把文件中的内容当作标准输入发送给 cat 命令,然后再输出到屏幕上
执行完 cat 命令后,屏幕上会等待我输入内容,当我输入完成按回车后,会在屏幕上输出同样的内容,这就是 cat 最基本的作用,效果如下图,第一行是我主动输入的,按下回车后,自动输出内容
~]$ cat
我在标准输入上输入了一些内容,按下回车后,输入的内容原样输出出来
我在标准输入上输入了一些内容,按下回车后,输入的内容原样输出出来
Syntax(语法)
cat [OPTIONS] [FILE]
OPTIONS
- -A, –show-all # 与 -vET 选项的效果相同
- -b, –number-nonblank # number nonempty output lines, overrides -n
- -e # 与 -vE 选项的效果相同
- -E, –show-ends # 在每行末尾显示
$。 - -n, –number # 显示行号。
- -s, –squeeze-blank # suppress repeated empty output lines
- -t # 等价于 -vT
- -T, –show-tabs # 将 TAB 字符显示为
^|。TAB 字符就是按下键盘 TAB 键产生的内容,是一个制表符。也就是说将空白的制表符以^|形式显示 - -u (ignored)
- -v, –show-nonprinting # 常用于查看该文件的换行符是否是 windows 下的
^M。use ^ and M- notation, except for LFD and TAB
EXAMPLE
- cat -T tab
~]# cat tab
123 123
~]# cat -T tab
123^I123
- 将多个文件的内容合并到一个文件
cat /data/users_* > users.sql
- cat 命令可以与输入输出重定向配合向文件中写入内容,效果如下
~]# cat test
123
~]# cat >> test << EOF
> 234
> $456
> \${456}
> EOF
~]# cat test
123
234
56
${456}
Note:如果想要写入变量,则需要加上转义符号\,否则会出现引用变量效果,而如果变量没定义,则引用位置为空
tail - 输出文件的最后一部分内容
属于 Coreutils 包中的工具
Syntax(语法)
tail [OPTIONS]
OPTIONS
EXAMPLE
- tail -f # 实时查看文件尾部的行,有新增的也显示出来,用于监控日志的新增内容
column - 将标准输出格式化为多个列
column 工具将其输入格式化为多个列。 行在列之前填充。 输入来自文件,或者默认情况下来自标准输入。 空行将被忽略。
Syntax(语法)
column [OPTIONS] FILE…
OPTIONS
- -c, –columns width # Output is formatted to a width specified as number of characters.
- -t, –table # Determine the number of columns the input contains and create a table. Columns are delimited with whitespace, by default, or with the characters supplied using the separator. Table output is useful pretty-printing.
- -s, –separator separators # Specify possible table delimiters (default is whitespace).
- -o, –output-separator separators # Specify table output delimiter (default is two whitespaces).
- -x, –fillrows # Fill columns before filling rows.
EXAMPLE
~]# docker ps --format {{.Image}}\\t{{.Names}}
goharbor/harbor-jobservice:v1.9.3 harbor-jobservice
goharbor/nginx-photon:v1.9.3 nginx
goharbor/harbor-core:v1.9.3 harbor-core
goharbor/harbor-registryctl:v1.9.3 registryctl
goharbor/registry-photon:v2.7.1-patch-2819-2553-v1.9.3 registry
~]# docker ps --format {{.Image}}\\t{{.Names}} | column -t
goharbor/harbor-jobservice:v1.9.3 harbor-jobservice
goharbor/nginx-photon:v1.9.3 nginx
goharbor/harbor-core:v1.9.3 harbor-core
goharbor/harbor-registryctl:v1.9.3 registryctl
goharbor/registry-photon:v2.7.1-patch-2819-2553-v1.9.3 registry
wc - 行数统计
wc[OPTIONS] FILE OPTIONS
- -l # 统计行数
- -L # 统计字符数
- -w # 统计单词数
- -c # 统计字节
tr - 转换或删除字符
转换,压缩和/或删除标准输入中的字符,写入标准输出。
Syntax(语法)
tr [OPTION]… SET1 [SET2]
默认情况,不加任何参数的话,tr 命令会把 SET1 转换为 SET2
OPTIONS
- -d,–delete # 删除 SET1 中的字符,不转换他们
EXAMPLE
把 echo 输出内容的所有大写字母转换成小写字母
echo "HELLO WORLD" | tr 'A-Z' 'a-z'
删除 JoinNodeCMD 变量中的 \r 的换行符。
echo ${JoinNodeCMD} | tr -d "\r"
删除结果中的
"双引号docker inspect snmp-exporter | jq .[0].GraphDriver.Data.MergedDir | tr -d """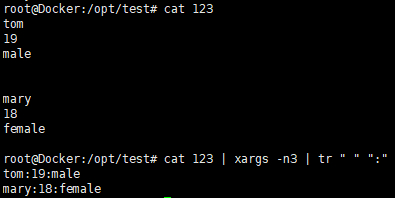
以默认分隔符展示每 3 个 ARGS 为一行,替换空格符为冒号
cut - 根据制定的分隔符切片,并显示出需要显示的片
Syntax(语法)
OPTIONS
- -d<分隔符> # 指定分隔符是什么
- -f<数字> # 指定要显示的字段是分隔符分割成的第几个字段
- 单个数字 # 一个字段
- 多个离散字段 # 逗号分隔
- 多个连续字段 # -分隔
EXAMPLE
- 显示 passwd 文件中,以冒号为分隔符的第一个字段的内容
- cut -d: -f1 /etc/passwd
sort - 按字符进行比较
参考:
Syntax(语法)
sort[OPTIONS] FILE OPTIONS:
- -f, –ignore-case # 忽略大小写
- -h, –human-numeric-sort # 带单位进行比较,比如 2K、1G 等等
- -n, –numeric-sort # 对数字进行排序(如果没有数字则需要后面的选项指定出来数字,按照以分隔符分割的行中的第几个字段比较)
- -r, –reverse # 以相反的顺序排序
- -t, –field-separator <SEQ> # 指定分隔符为 SEQ。
默认值:空白字符 - -k, –key <开始字段数[.该段第几字符,结束字段数,该段第几字符]> # 指定分隔后进行比较的第几字段,默认根据第一个字段的第一个字符(即行首)进行排序
- 用法如下图,蓝色框是第一字段,红色框是第一字段的第二个字符,以:作为分隔符
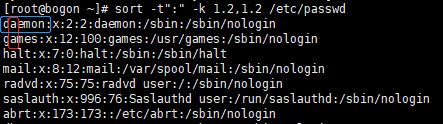
- -u, –unique # 重复的行,只显示一行
uniq - 移除重复的行
OPTIONS
- -c # 统计每一行出现的次数(靠着的行)
- -d # 仅显示出现最少两次的行
- -u # 仅显示不重复的行
split - 文件切割
Syntax(语法)
split [-a] [-d] [-l <行数>] [-b <字节>] [-C <字节>] [要切割的文件] [输出文件名]
OPTIONS
- -a# 指定输出文件名的后缀长度(默认为 2 个:aa,ab…)
- -d # 指定输出文件名的后缀用数字代替
- -l # 行数分割模式(指定每多少行切成一个小文件;默认行数是 1000 行)
- -b # 二进制分割模式(支持单位:k/m)
- -C# 文件大小分割模式(切割时尽量维持每行的完整性)
EXAMPLE
- 行切割文件
- split -l 300000 users.sql /data/users_
- 使用数字后缀
- split -d -l 300000 users.sql /data/users_
- 按字节大小分割
- split -d -b 100m users.sql /data/users_
如果你有一个很大的文件,你想把其分割成一些小的文件,那么这个命令就是干这件事的了。
~]# ls -l largefile.tar.gz
-rw-r--r-- 1 hchen hchen 436774774 04-17 02:00 largefile.tar.gz
~]# split -b 50m largefile.tar.gz LF_
~]# ls -l LF_*
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:34 LF_aa
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:34 LF_ab
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:34 LF_ac
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:34 LF_ad
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:34 LF_ae
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:35 LF_af
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:35 LF_ag
-rw-r--r-- 1 hchen hchen 52428800 05-10 18:35 LF_ah
-rw-r--r-- 1 hchen hchen 17344374 05-10 18:35 LF_ai
文件合并只需要使用简单的合并就行了,如:
~]# cat LF_* >largefile.tar.gz
Windows 文件换行符转换为 Linux 换行符
由于 Windows 的换行符和 Linux 换行符不一样,导致程序编译不通过。
首先介绍下,在 ASCII 中存在这样两个字符 CR(编码为 13)和 LF(编码为 10),在编程中我们一般称其分别为 \r 和 \n。他们被用来作为换行标志,但在不同系统中换行标志又不一样。下面是不同操作系统采用不同的换行符:
- Unix 和类 Unix(如 Linux):换行符采用
\n - Windows 和 MS-DOS:换行符采用
\r\n - Mac OS X 之前的系统:换行符采用
\r - Mac OS X:换行符采用
\n
Linux 中查看换行符
第一种使用 cat -A FILE 查看,如下图所示,看到的为一个 Windows 形式的换行符,\r 对应符号 ^M,\n对应符号 $
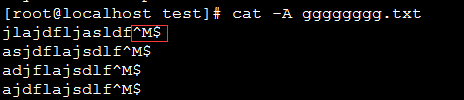
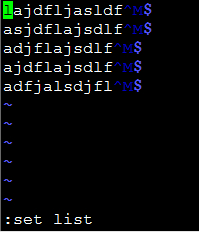
第二种使用vi编辑器查看,然后使用 set list 命令显示特殊字符
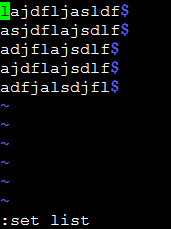
怎么^M还是没显示出来,用VI的二进制模式 vi -b FILE 打开,才能够显示出 ^M:
替换方法
方法一:使用 VI 普通模式打开文件,然后运行命令"set ff=unix" 则可以将 Windows 换行符转换为 Linux 换行符,简单吧!命令中 ff 的全称为 file encoding。
方法二:使用命令"dos2unix",如下所示
dos2unix 123.txt
方法三:使用 sed 命令删除\r 字符:
sed -i 's/\r//g' gggggggg.txt
方法四:使用 windows 版 git 里提供的命令来进行替换,在 git 命令行中进入到要替换文件的目录,执行下面的命令。Node:一定要进入指定目录再执行命令
find . -type f -exec dos2unix {} ;
多文件处理换行符转换
通常我们都会有一批文件需要替换,比如一个目录的都要替换,我自己写了一个简单的脚本去遍历目录和子目录下的所有文件,并且将其转换为Linux换行格式。代码如下:
#!/bin/sh
#CheckInput
#Check Whether the input is valid
#0 means not valid
CheckInput()
{
ret=1;
#Check the number of parameter
# And Check whether the argument is a folder
if [ $# -lt 1 ]
then
echo "Please use the command like ./dos2u.sh [Folder]";
ret=0
elif [ ! -d $1 ]
then
echo "Please use an invalid Folder as the shell argument";
ret=0
fi
return $ret;
}
#TraverseFolder
#Traser all the files under the folder
TraverseFolder()
{
oldPath=`pwd`
cd $1;
for file in `ls`
do
if [ -d $file ]
then
TraverseFolder $file;
else
#echo $file;
#sed -i 's/\r//g' $file
dos2unix $file
fi
done
cd $oldPath;
}
CheckInput $*
if [ $ret -ne 1 ]
then
exit -1
fi
TraverseFolder $1
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.