Controller
概述
参考:
Controller(控制器) 是 Kubernetes 的大脑
在机器人和自动化技术中,控制环是一个控制系统状态不终止的循环。
比如:房间里的温度自动调节器,当我设置了温度,告诉温度调节器我的期望状态。房间的实际温度是当前状态。温度自动调节器就会让当前状态一直去接近期望状态。
kubernetes 的 Controller 就是这样一种东西,通过 apiserver 监控集群的期望状态,并致力于将当前状态转变为期望状态。而 controller 是一个更高层次的抽象概念,指代多种具有 controller 功能的资源,比如 deployment、statefulset 等等。
可以用一段 Go 语言风格的伪代码,来描述这个控制循环:
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
在具体实现中,实际状态一般来自于 kubernetes 集群本身,e.g.kubelet 收集所在节点上容器状态和节点状态。而期望状态,一般来自于用户提交的 YAMl 文件。
以 Deployment 这种控制器为例,简单描述一下它对控制器模型的实现:
- 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- 用户提交的 yaml 文件中 Replicas 字段的值就是期望状态(提交的 yaml 也会保存到 etcd 中);
- 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod 。
这个对比的操作通常被叫作 Reconcile(调和)。这个调谐的过程,则被称作 Reconcile Loop(调和循环) 或者 Sync Loop(同步循环)。这些词其实都代表一个东西:控制循环。
Reconcile 这词儿用的还挺有意思,Reconcile 是调和、使协调一致的概念,就是让具有矛盾的两方和解~这就好比控制器和被控制者,当被控制者不符合控制者预期状态时,这就相当于两者有矛盾了。。。Reconcile 就会让矛盾消失 Reconcile 是一个动词,表示一个过程,在 k8s 中还有一个对应的名词 Reconciliation,用以表示“确保系统的实际状态与期望状态一致”
也可以这么说:控制器,使用一种 API 对象管理另一种 API 对象的工具。控制器这个对象本身负责定义被管理对象的期望状态(e.g.deployment 里的 replicas: 2 这个字段);而被控制对象的定义,则来自于一个“模板”(e.g.deployment 里的 template 字段)。
可以看到,deployment 资源中 template 字段里的内容跟一个标准的 pod 对象的定义丝毫不差。而所有被这个 deployment 管理的 pod 对象,都是根据 template 字段的内容创建出来的。
像 Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate(Pod 模板)。更有意思的是,我们还会看到其他类型的对象模板,比如 Volume 的模板。
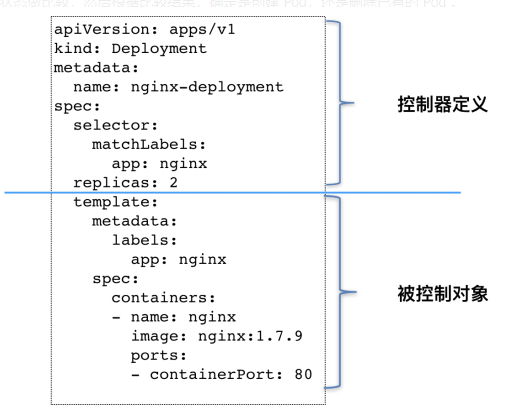
如上图所示,类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。
这就是为什么,在所有 API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。
各种 Controller 是 kubernetes 的大脑,通过 apiserver 监控整个集群的状态,作为集群内部的管理控制中心,负责集群内的 Node、Pod 副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)等资源的管理。比如,当某个 Node 意外宕机时,Controller 会及时发现并执行自动化修复流程,comtroller 会确保集群始终处于预期的工作状态。
Note:严格来说 Pod 并不是由 controller 直接管理的,而是通过 deployment 之类的 controller 来管理 Pod 或者由 kubelet 来管理 pod。kubelet 自身也具备控制循环的功能。
用白话来说
kubernetes 有各种各样的资源,每个资源都有其自己的各种定义(比如一个 pod 资源里有 image、name、volumemount 等等),那么这些定义所能实现的功能,又是谁来决定的呢?答案就是 controller
资源的定义只是提供了 JSON 格式的数据,至于如何执行这些数据,则是 controller 这个程序的作用。
例如 deployment 中定义了一个 replicas,该 replicas 有一个值,那么系统是怎么知道 replicas:VALUE 这一串字符串是干什么用的呢,这就是 controller 的作用,controller 会告诉 k8s 集群,这一段字符串的含义是该 deployment 下的 pod 应该具有多少个副本。除了描述该字段的含义以外,还会控制 deployment 下的 pod 向着期望的值来转变,当 pod 的副本数量多余或者少于设定的值时,controller 都会删除或者创建相应的 pod 来满足指定的值。
而各种 controller 内各个字段的含义,则是靠 kube-controller-manager 这个程序来管理并定义其中各个字段的含义。
总结: 这就是 kubernetes 的核心思想,编排也是依靠 controller 来实现的。
控制器的实现
kube-controller-manager 是实现 Kubernetes 控制器功能的程序。
可以在 Controller 代码中,找到所有可用的控制器。所以,从逻辑上来说,每个控制器都应该是一个单独的进程,但是为了降低复杂性,这些控制器都被编译到同一个执行文件中,并在同一个进程中运行。所以,这些控制器的集合体,就称为 Controller Manager(控制器管理器),所以实现控制器功能的组件的名称就叫 kube-controller-manager。
[!Example] Controller Manager 管理 Deployment 资源,连接到 API Server 监听到了 Depoyment 资源的变化,开始根据 Deployment 的定义创建 Replication,Replication 又创建 Pod
各种控制器介绍
参考:
Controller 包括以下这些:不同的 controller 管理不同的资源。
- Replication Controller # 副本控制器,主要用于保障 pod 的副本数量(副本就是复制)
- Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。
- Node Controller # 节点控制器,用于控制节点相关信息,比如该节点的 cidr 信息等。
- CronJob Controller
- Daemon Controller
- Deployment Controller # 部署控制器,管理 Deployment 资源
- Endpoint Controller # 端点控制器
- Garbage Collector
- Namespace Controller # 管理 Namespace 资源。
- Job Controller
- Pod AutoScaler # i.e.HPA,用于 pod 自动伸缩
- RelicaSet
- Service Controller
- ServiceAccount Controller # 服务账户控制器
- StatefulSet Controller
- Volume Controller # 卷控制器
- Resource quota Controller
Deployment - 管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行
官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
比 ReplicaSet 还多了几个功能支持滚动更新和回滚,支持声明式配置的功能
- ReplicaSet 实现了 Pod 的多副本管理,一般情况 ReplicaSet 管理无状态的 Pod。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,我们通常不需要直接使用 ReplicaSet。 ReplicaSet 一般由下面三个组件组成,当启动 Pod 时,按照如下顺序进行创建 Pod
- 用户期望的副本数,即希望创建多少个与该 Pod 一样的副本,进行统一管理,创建在不同 Node 上以实现负载均衡以及高可用,这些 Pod 的功能与服务一模一样
- 标签选择器,以便选定由自己管理和控制的 Pod,如果标签选择器选择的 pod 数量少于用户期望的副本数,则使用 Pod 资源模板
- Pod 资源模板,新建 Pod 资源
- Deployment 的滚动更新可以进行定制化配置,比如仅更新一个 pod 到新版,观察其稳定情况几天后决定是否更新现网其余 pod,使用的方式详见 kubectl set image 命令的内容
StatefulSet - StatefulSet 表示对 Pod 设定一致性身份(consistent identities)
官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
Identities 的定义:
- Network:单一稳定的主机名和 DNS
- Storage: 具有同样的一些 VolumeClaims. StatefulSet 保证给定的网络标识将始终映射到相同的存储标识。
StatefulSet 能够保证 Pod 的每个副本在整个生命周期中名称是不变的,一般情况 StatefulSet 管理有状态的 Pod。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefulSet 会保证副本按照固定的顺序启动、更新或者删除。
- 当需要保持 Pod 不变,比如数据库类型的服务,则使用该类型
- 当一个有状态的应用失败需要重启的时候,比如主从结构的数据库,其中需要进行的操作时非常复杂的,这时候需要通过一个脚本来定义 statefulset 的功能,如果以后的研发人员可以基于 kubernetes 来开发有状态的应用(比如数据库等),让新的应用在开发的时候就想着要放在云上运行,这种云原生的应用,则可以让 statefulset 更好的支持他
DaemonSet - 用于每个 Node 最多只运行一个 Pod 副本的场景。正如其名称所揭示的,DaemonSet 通常用于运行 daemon
官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
当一个服务可以想象成守护进程的时候,使用该类型
CronJob 与 Job - 用于运行结束就删除的应用。而其他 Controller 中的 Pod 通常是长期持续运行
官方文档:
Job 对象用来创建一个或多个 pod,并确保指定数量的 pod 成功终止。pod 成功完成后,job 将跟踪完成的情况。当达到指定的成功完成次数时,Job 就完成了。删除 job 将清除其创建的 pod 。
job 对象可以 通过 cronjob 对象来创建。cronjob 可以按照重复计划创建 job。cronjob 与 linux 中 crontab 的用法一样。可以根据指定的时间间隔定时运行任务。
其实,cronjob 与 job 的关系,有点像 deployment 之类的控制器与 pod 之间的关系。在编写 yaml 时,deployment 需要指定 pod 的 template,而 cronjob 则需要指定 jobTemplate。
CronJob 的行为可以通过其 yaml 中的 spec 字段中的相关字段来指定
官方文档:https://kubernetes.io/docs/tasks/job/automated-tasks-with-cron-jobs/#writing-a-cron-job-spec
- concurrencyPolicy <string> # 指定如何处理作业的并发执行。有效值为:-“允许”(默认):允许 CronJobs 同时运行; -“禁止”:禁止并行运行,如果前一个运行尚未完成,则跳过下一个运行; -“替换”:取消当前正在运行的作业,并将其替换为新作业
- failedJobsHistoryLimit <INTEGER> # 执行失败的 job(Completed 状态的 pod) 的保留数为 INTEGER。默认为 1
- jobTemplate <Object> # -required- 指定在执行 CronJob 时将创建的作业。类似于 deployment 下的。
- schedule <string> # -required- Cron 格式的日程表,请参阅https://en.wikipedia.org/wiki/Cron。
- startingDeadlineSeconds <integer> # 如果由于任何原因错过了计划的时间,则以秒为单位的可选截止日期,用于启动作业。错过的工作执行将被视为失败的工作。
- successfulJobsHistoryLimit <INTEGER> # 执行成功的 job(Completed 状态的 pod) 的保留数为 INTEGER。默认为 3
- suspend <boolean> # 此标志告诉控制器暂停随后的执行,不适用于已经开始的执行。默认为 false。
Garbage Collection(垃圾收集器)
官方文档:https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/
Kubernetes 垃圾收集器的作用是删除某些对象。曾经有一个所有者,但不再有一个所有者。
HPA - Horizontal Pod Autoscaler
官方文档:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.