Rook+Ceph 部署与清理
Rook+Ceph 部署
官方文档:https://rook.github.io/docs/rook/master/ceph-quickstart.html
部署环境准备
kubernetes 集群准备
在集群中至少有三个节点可用,满足 ceph 高可用要求,这里已配置 master 节点使其支持运行 pod。
rook 使用存储方式
rook 默认使用所有节点的所有资源,rook operator 自动在所有节点上启动 OSD 设备,Rook 会用如下标准监控并发现可用设备:
设备没有分区
设备没有格式化的文件系统
Rook 不会使用不满足以上标准的设备。另外也可以通过修改配置文件,指定哪些节点或者设备会被使用。
添加新磁盘
这里在所有节点添加 1 块 50GB 的新磁盘:/dev/sdb,作为 OSD 盘,提供存储空间,添加完成后扫描磁盘,确保主机能够正常识别到:
#扫描 SCSI 总线并添加 SCSI 设备
for host in $(ls /sys/class/scsi_host) ; do echo “- - -” > /sys/class/scsi_host/$host/scan; done
#重新扫描 SCSI 总线
for scsi_device in $(ls /sys/class/scsi_device/); do echo 1 > /sys/class/scsi_device/$scsi_device/device/rescan; done
#查看已添加的磁盘,能够看到 sdb 说明添加成功
lsblk
本次搭建环境为 3 master 2 node,其中 master-3 去掉了污点,让其可以运行 pod
部署 Rook Operator
克隆 rook github 仓库到本地(注意:一般不使用 master 分支版本)
git clone –single-branch –branch master https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph/
创建 Rook Operator
kubectl apply -f common.yaml
kubectl apply -f operator.yaml
common.yaml 会创建如下资源:
namespace:rook-ceph,之后的所有 rook 相关的 pod 都会创建在该 namespace 下面
CRD:创建多个 CRDs
role & clusterrole:用户资源控制
serviceaccount:ServiceAccount 资源,给 Rook 创建的 Pod 使用
operator.yaml 会创建如下资源
deployment:rook-ceph-operator,部署 rook ceph 相关的组件
config # rook-ceph-operator 的配置文件
部署 rook-ceph-operator 过程中,会触发以 DaemonSet 的方式在集群部署 rook-discover
[root@master-1 ceph]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-667756ddb6-spqdw 1/1 Running 0 2m10s
rook-discover-2d8zm 1/1 Running 0 67s
rook-discover-fcg47 1/1 Running 0 67s
rook-discover-klkb6 1/1 Running 0 67s
创建 rook Cluster
等待 rook-discover 与 rook-ceph-operator 容器正常运行,就可以部署 ceph cluster 了。
- kubectl apply -f cluster.yaml
它会创建如下资源:
serviceaccount:ServiceAccount 资源,给 Ceph 集群的 Pod 使用
role & rolebinding:用户资源控制
cluster:rook-ceph,创建的 Ceph 集群
该配置文件中 dataDirHostPath 字段用来定义数据盘目录
Ceph 集群部署成功后,可以查看到的 pods 如下,其中 osd 数量取决于你的节点数量:
[root@master-1 ceph]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-8dn2w 3/3 Running 0 2m25s
csi-cephfsplugin-lm4r6 3/3 Running 0 2m25s
csi-cephfsplugin-provisioner-598854d87f-m8msp 6/6 Running 0 2m25s
csi-cephfsplugin-provisioner-598854d87f-w28b6 6/6 Running 0 2m25s
csi-cephfsplugin-sdbp5 3/3 Running 0 2m26s
csi-rbdplugin-452q7 3/3 Running 0 2m28s
csi-rbdplugin-5vnpc 3/3 Running 0 2m28s
csi-rbdplugin-bw6wl 3/3 Running 0 2m28s
csi-rbdplugin-provisioner-dbc67ffdc-678n7 6/6 Running 0 2m27s
csi-rbdplugin-provisioner-dbc67ffdc-jqltc 6/6 Running 0 2m27s
rook-ceph-crashcollector-master-3.tj-test-6989ff959-7zvhc 1/1 Running 0 52s
rook-ceph-crashcollector-node-1.tj-test-6b6c5d9647-cd876 1/1 Running 0 83s
rook-ceph-crashcollector-node-2.tj-test-679479f5b6-6rkf9 1/1 Running 0 28s
rook-ceph-mgr-a-5d985d4477-z5j82 1/1 Running 0 30s
rook-ceph-mon-a-6786946fcb-89z8w 1/1 Running 0 84s
rook-ceph-mon-b-84c758775f-n5rx2 1/1 Running 0 69s
rook-ceph-mon-c-84dd9549b6-npvkx 1/1 Running 0 52s
rook-ceph-operator-667756ddb6-spqdw 1/1 Running 0 6m45s
rook-ceph-osd-1-59554d79b9-9fbpw 0/1 Pending 0 0s
rook-ceph-osd-prepare-master-3.tj-test-pz7kx 1/1 Running 0 28s
rook-ceph-osd-prepare-node-1.tj-test-kkplm 1/1 Running 0 27s
rook-ceph-osd-prepare-node-2.tj-test-tcvfk 1/1 Running 0 26s
rook-discover-2d8zm 1/1 Running 0 5m42s
rook-discover-fcg47 1/1 Running 0 5m42s
rook-discover-klkb6 1/1 Running 0 5m42s
可以看出部署的 Ceph 集群有:
Ceph Monitors:默认启动三个 ceph-mon,可以在 cluster.yaml 里配置
Ceph Mgr:默认启动一个,可以在 cluster.yaml 里配置
Ceph OSDs:根据 cluster.yaml 里的配置启动,默认在所有的可用节点上启动
配置 ceph dashboard
- kubectl apply -f dashboard-external-https.yaml
查看一下 nodeport 暴露的端口,这里是 30004 端口:
[root@master-1 ceph]# kubectl get service -n rook-ceph | grep dashboard
rook-ceph-mgr-dashboard ClusterIP 10.108.174.177 <none> 8443/TCP 8m56s
rook-ceph-mgr-dashboard-external-https NodePort 10.110.152.30 <none> 8443:30004/TCP 12s
获取 Dashboard 的登陆账号和密码
[root@master-1 ceph]# kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
SP70Y6t"BkJ$3yGR'm_=
找到 username 和 password 字段,我这里是
admin
SP70Y6t"BkJ$3yGR’m_=
打开浏览器输入任意一个 Node 的 IP+nodeport 端口,这里使用 master 节点 ip 访问:

登录后界面如下:

查看 hosts 状态:
运行了 1 个 mgr、3 个 mon 和 3 个 osd

查看 monitors 状态:

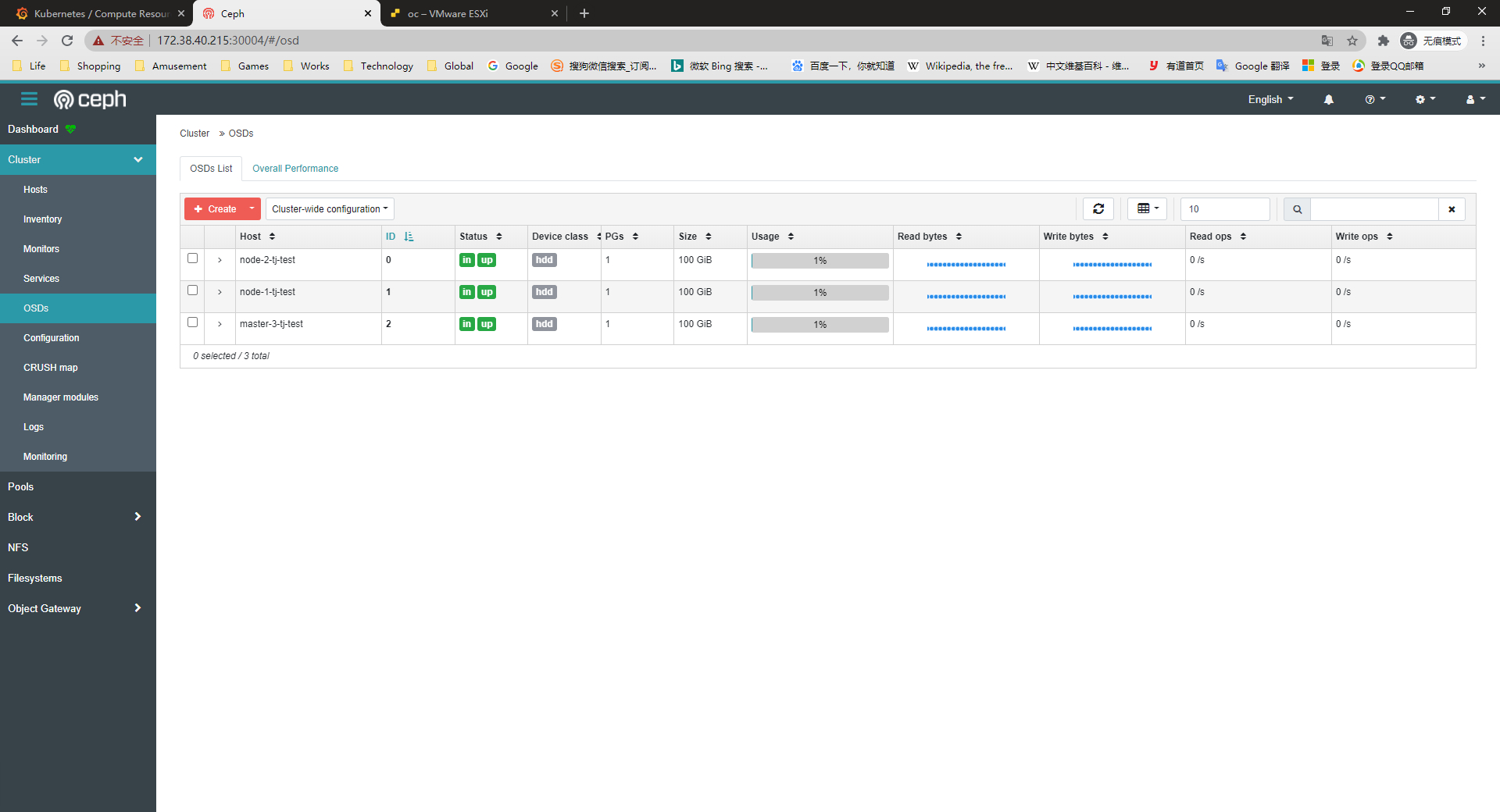
查看 OSD 状态
3 个 osd 状态正常,每个容量 100GB.
部署 Ceph toolbox
默认启动的 Ceph 集群,是开启 Ceph 认证的,这样你登陆 Ceph 组件所在的 Pod 里,是没法去获取集群状态,以及执行 CLI 命令,这时需要部署 Ceph toolbox,命令如下:
- kubectl apply -f toolbox.yaml
部署成功后,pod 如下:
[root@master-1 ceph]# kubectl -n rook-ceph get pods -o wide | grep ceph-tools
rook-ceph-tools-7cc7fd5755-rz64q 1/1 Running 0 6s 10.244.4.165 node-2.tj-test <none> <none>
然后可以登陆该 pod 后,执行 Ceph CLI 命令:
[root@master-1 ceph]# kubectl exec -it -n rook-ceph rook-ceph-tools-7cc7fd5755-rz64q -- /bin/bash
# 查看ceph集群状态
[root@rook-ceph-tools-7cc7fd5755-rz64q /]# ceph status
cluster:
id: fb54f9a4-47d1-4c57-98b2-f5f7c16cd3d9
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 13m)
mgr: a(active, since 12m)
osd: 3 osds: 3 up (since 12m), 3 in (since 12m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 297 GiB / 300 GiB avail
pgs: 1 active+clean
查看 ceph 配置文件
[root@rook-ceph-tools-7cc7fd5755-rz64q /]# cd /etc/ceph
[root@rook-ceph-tools-7cc7fd5755-rz64q ceph]# ls
ceph.conf keyring
[root@rook-ceph-tools-7cc7fd5755-rz64q ceph]# cat ceph.conf
[global]
mon_host = 10.106.96.12:6789,10.100.114.27:6789,10.96.163.133:6789
[client.admin]
keyring = /etc/ceph/keyring
[root@rook-ceph-tools-7cc7fd5755-rz64q ceph]# cat keyring
[client.admin]
key = AQDKn2xfuxpvIhAAixmcxq5Y0JFSIyQWXFtE0w==
Rook 提供 RBD 服务
rook 可以提供以下 3 类型的存储:
Block: Create block storage to be consumed by a pod
Object: Create an object store that is accessible inside or outside the Kubernetes cluster
Shared File System: Create a file system to be shared across multiple pods
在提供块存储之前,需要先创建 StorageClass 和存储池。K8S 需要这两类资源,才能和 Rook 交互,进而分配持久卷(PV)。
在 kubernetes 集群里,要提供 rbd 块设备服务,需要有如下步骤:
创建 rbd-provisioner pod
创建 rbd 对应的 storageclass
创建 pvc,使用 rbd 对应的 storageclass
创建 pod 使用 rbd pvc
通过 rook 创建 Ceph Cluster 之后,rook 自身提供了 rbd-provisioner 服务,所以我们不需要再部署其 provisioner。
备注:代码位置 pkg/operator/ceph/provisioner/provisioner.go
创建 pool 和 StorageClass
创建块存储
- kubectl create -f csi/rbd/storageclass.yaml
创建了一个名为 replicapool 的存储池,和名为 rook-ceph-block 的 storageClass。
[root@master-1 ceph]# kubectl apply -f csi/rbd/storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created
查看创建的 storageclass:
[root@master-1 ceph]# kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 6s
登录 ceph dashboard 查看创建的存储池:

使用存储
以官方 wordpress 示例为例,创建一个经典的 wordpress 和 mysql 应用程序来使用 Rook 提供的块存储,这两个应用程序都将使用 Rook 提供的 block volumes。
启动 mysql 和 wordpress :
kubectl apply -f rook/cluster/examples/kubernetes/mysql.yaml
kubectl apply -f rook/cluster/examples/kubernetes/wordpress.yaml
这 2 个应用都会创建一个块存储卷,并且挂载到各自的 pod 中,查看声明的 pvc 和 pv:
[root@master-1 ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-6946e476-b03f-45ce-b482-f4313c4d50b3 20Gi RWO rook-ceph-block 18s
wp-pv-claim Bound pvc-29627c5c-7a45-460f-a2ab-ce9d8887bed6 20Gi RWO rook-ceph-block 16s
[root@master-1 ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-29627c5c-7a45-460f-a2ab-ce9d8887bed6 20Gi RWO Delete Bound default/wp-pv-claim rook-ceph-block 26s
pvc-6946e476-b03f-45ce-b482-f4313c4d50b3 20Gi RWO Delete Bound default/mysql-pv-claim rook-ceph-block 26s
注意:这里的 pv 会自动创建,当提交了包含 StorageClass 字段的 PVC 之后,Kubernetes 就会根据这个 StorageClass 创建出对应的 PV,这是用到的是 Dynamic Provisioning 机制来动态创建 pv,PV 支持 Static 静态请求,和动态创建两种方式。
登录 ceph dashboard 查看创建的 images

在 Ceph 集群端检查:
[root@master-1 ~]# kubectl -n rook-ceph exec -it rook-ceph-tools-7cc7fd5755-rz64q bash -- /bin/bash
[root@rook-ceph-tools-7cc7fd5755-rz64q /]# rbd info -p replicapool csi-vol-32fc614e-fe70-11ea-a2af-76b93ba918d2
rbd image 'csi-vol-32fc614e-fe70-11ea-a2af-76b93ba918d2':
size 20 GiB in 5120 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 639b799e1bd
block_name_prefix: rbd_data.639b799e1bd
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Sep 24 14:14:06 2020
access_timestamp: Thu Sep 24 14:14:06 2020
modify_timestamp: Thu Sep 24 14:14:06 2020e
登陆 pod 检查 rbd 设备:
[root@master-1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wordpress-7bfc545758-d88nx 1/1 Running 0 2m46s 10.244.4.166 node-2.tj-test <none> <none>
wordpress-mysql-764fc64f97-khcgl 1/1 Running 0 2m48s 10.244.2.52 master-3.tj-test <none> <none>
[root@master-1 ~]# kubectl exec -it wordpress-7bfc545758-d88nx -- /bin/bash
root@wordpress-7bfc545758-d88nx:/var/www/html# mount | grep rbd
/dev/rbd0 on /var/www/html type ext4 (rw,relatime,stripe=1024,data=ordered)
root@wordpress-7bfc545758-d88nx:/var/www/html# df -h
Filesystem Size Used Avail Use% Mounted on
.....
/dev/rbd0 20G 70M 20G 1% /var/www/html
.....
一旦 wordpress 和 mysql pods 处于运行状态,获取 wordpress 应用程序的集群 IP 并使用浏览器访问:
[centos@k8s-master ~]$ kubectl get svc wordpress
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress LoadBalancer 10.98.178.189 <pending> 80:30001/TCP 136m
访问 wordpress:

清理 Ceph 集群
官方文档:https://rook.github.io/docs/rook/master/ceph-teardown.html
清理 Ceph 集群先,需要先清楚 Ceph 上的所有数据(PV、PVC、volumes 等等)。清理这些资源是非常重要的,如果不删除,可能会导致 Ceph 集群无法正确清理
清理完成后,开始删除已创建的 Ceph 集群
删除 CephCluster 这个 CRD
在清除了上述这些块和文件资源之后,就可以删除 Rook 群集。
kubectl -n rook-ceph delete cephcluster rook-ceph
在继续下一步之前,请验证是否已删除群集 CRD。
kubectl -n rook-ceph get cephcluster
删除 Rook Operator 及其相关资源
kubectl delete -f operator.yaml
kubectl delete -f common.yaml
删除设备上的数据 Delete the data on hosts
重要说明:最后的清理步骤要求删除群集中每个主机上的文件。群集 CRD 中指定的 dataDirHostPath 属性下的所有文件都需要删除。否则,启动新群集时将保持不一致状态。
连接到每台计算机,然后删除 /var/lib/rook 或 dataDirHostPath 指定的路径。
In the future this step will not be necessary when we build on the K8s local storage feature.
If you modified the demo settings, additional cleanup is up to you for devices, host paths, etc.
Zapping Devices
被 Rook 创建的 osds 所使用的节点上的磁盘,可以通过以下方法重置为可用状态:
#!/usr/bin/env bash
DISK="/dev/sdb"
# 将磁盘转换为新的可用状态(全部压缩非常重要,b/c MBR必须干净)
# 您必须对所有磁盘运行此步骤。
sgdisk --zap-all $DISK
# 用 dd 命令清理硬盘
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
# 使用 blkdiscard 而不是 dd 清理 ssd 等磁盘
blkdiscard $DISK
# These steps only have to be run once on each node
# 如果rook使用ceph-volume设置了osds,则拆除会留下一些映射的设备来锁定磁盘。
ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove %
# eph-volume 安装程序可以将 ceph-<UUID> 目录保留在 /dev 中(不必要的混乱)
rm -rf /dev/ceph-*
删除 Ceph 集群后,在之前部署 Ceph 组件节点的/var/lib/rook/目录,会遗留下 Ceph 集群的配置信息。
若之后再部署新的 Ceph 集群,先把之前 Ceph 集群的这些信息删除,不然启动 monitor 会失败;
# cat clean-rook-dir.sh
hosts=(
master0
master1
master2
)
for host in ${hosts[@]} ; do
ssh $host "rm -rf /var/lib/rook/*"
done
# kubectl delete -f cluster.yaml
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.