Kubernetes 监控
概述
参考:
对于 Kubernetes 集群的监控一般我们需要考虑以下几个方面:
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 集群系统组件的状态:比如 kubelet、kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- Pod 的监控:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
Kubernetes 中,应用程序监控不依赖于单个监控解决方案,目前主要有以下几种方案:
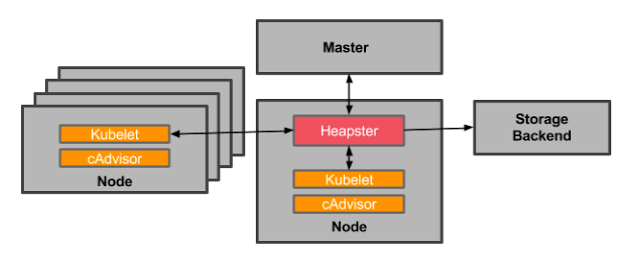
- Resource Metrics Pipeline# 通过 API Server 中的 Metrics API 暴露的一个用于显示集群指标接口,该接口在集群刚部署完成时,并不是默认自带的。需要通过其他方式来启用这个 API
- 可以通过 Resource Metrics 或 Full Metrics Pipelines 来收集监控指标数据
- cAdvisor # cAdvisor 是 Google 开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持 Docker 容器,在 Kubernetes 中,我们不需要单独去安装,cAdvisor 作为 kubelet 内置的一部分程序可以直接使用。kubelet 中的子组件 cAdvisor 来收集资源用量信息,并暴露 OpemMetrics 格式的监控指标。
- metrics-server # metrics-server 是一个集群范围内的资源数据聚合工具,其前身是 Heapster。以 Pod 的形式运行在集群中,通过查询每个节点的 kubelet 以获取 CPU 和内存使用情况。
- 项目地址:https://github.com/kubernetes-sigs/metrics-server
- Heapster # 由于 Heapster 无法通过 Metrics API 的方式提供监控指标,所以被废弃了。1.11 以后的版本中会使用 metrics-server 代替。
- kube-state-metrics 程序,用来监听 API Server 以补充 Metrics API 无法提供的集群指标,比如 Deployment、Node、Pod 等等资源的状态
- 各个系统组件暴露的
/metrics端点,可以提供组件自身的指标
Note:以上几种监控方案只是简单提供一个 metrics 数据,并不会存储这些 metrics 数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储。
Resource Metrics Pipeline(Metrics API) - 资源指标通道
参考:
Kubernetes 集群内的 Resource Metrics Pipeline(资源指标通道),指的是传输各种资源 Metrics(指标) 的 API 接口,该 API 通过 API 聚合功能添加。所以,也称之为 Metrics API,这种 API 是专门用来传输集群的 Metrics(指标) 数据
Metrics API(指标接口)
在 kuberntes 的监控体系中,Metrics API 一般分为两种
- Core Metrics(核心指标)# API 默认为
/apis/metrics.k8s.io。该 API 一般是通过 metrics-server 等程序 从 Kubelet、cAdvisor 等获取指标。- 核心指标包括 cpu 和 memory 两个
- Custom Metrics(自定义指标)# API 默认为
/apis/custom.metrics.k8s.io。该 API 一般是通过 Prometheus Adapter 从 adapter 关联的 prometheus 中查询到的数据获取度指标
Note:在 MetricsAPI 注册的每一个 metircs 也可以称为一个 kubernetes 的 resource ,只不过这些资源的 kind 会根据 MetricsAPI 的实现工具来命名(比如 prometheus-adapter 的自定义指标 kind 为 MetricValueList,metrics-server 和 prometheus-adapter 的核心指标 kind 为 NodeMetrics 和 PodMetrics)
通过 Metrics API,可以获取指定 node 或者 pod 当前使用的资源量 或者 某些自定义的资源指标值(比如某个 pod 的并发请求数等)。这些 metrics 可以直接被用户访问(比如使用 kubectl top 命令),或者由集群中的控制器(比如 Horizontal Pod Autoscaler)来使用这些指标进行决策。
此 API 不存储 metrics 的值,因此想要获取某个指定节点 10 分钟前的资源使用量是不可能的,除非将每个时刻的 metrics 的值存储在某个地方才可以(比如 prometheus)
Note:Metrics API 需要在集群中部署 Metrics 服务(比如 metrics-server、prometheus-adapter 等)。否则 Metrics API 将不可用。
实现原理
kubectl top 、 k8s dashboard 以及 HPA 等组件使用的数据是一样,对于 Core Metrics 来说,过程如下
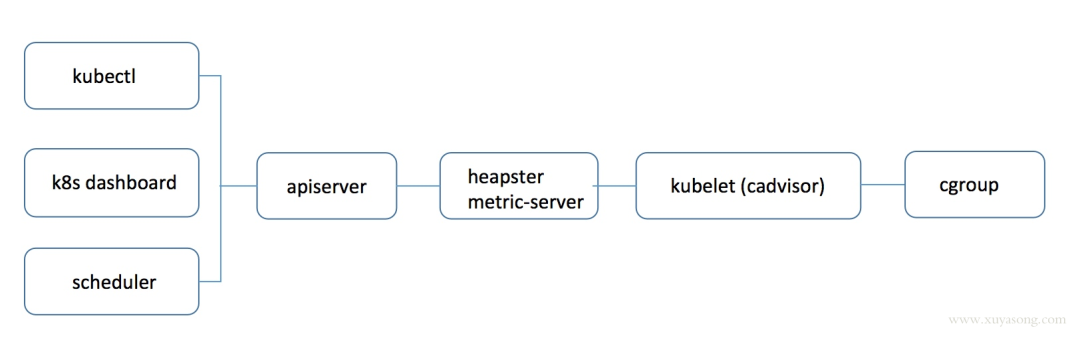
使用 heapster 时:apiserver 会直接将 metric 请求通过 proxy 的方式转发给集群内的 hepaster 服务。

而使用 metrics-server 时:apiserver 是通过 /apis/metrics.k8s.io/ 的地址访问 metric

可以发现,heapster 使用的是 proxy 转发,而 metric-server 和普通 pod 都是使用 api/xx 的资源接口,heapster 采用的这种 proxy 方式是有问题的:
- proxy 只是代理请求,一般用于问题排查,不够稳定,且版本不可控
- heapster 的接口不能像 apiserver 一样有完整的鉴权以及 client 集成,两边都维护的话代价高,如 generic apiserver
- pod 的监控数据是核心指标(HPA 调度),应该和 pod 本身拥有同等地位,即 metric 应该作为一种资源存在,如 metrics.k8s.io 的形式,称之为 Metric Api
于是官方从 1.8 版本开始逐步废弃 heapster,并提出了上边 Metric api 的概念,而 metrics-server 就是这种概念下官方的一种实现,用于从 kubelet 获取指标,替换掉之前的 heapster
实现 Metrics API 的方式
当 Metrics API 实现后,可以通过如下命令查看是否成功注册 api,这俩命令可以获取自定义指标和核心指标的指标名。
- kubectl get –raw “/apis/custom.metrics.k8s.io/v1beta1/”
- kubectl get –raw “/apis/metrics.k8s.io/v1beta1/”
Metrics Server
Metrics Server 是资源使用情况数据的群集范围内的聚合器。使用其他方式部署的 Kubernetes(比如 kubeadm),可以使用提供的部署文件 Components.yaml 进行部署。
Metrics Server 的部署文件中,会通过 Kubernetes 的 API 聚合功能 注册一个名为 metrics.k8s.io 的新 API 作为 Metrics API。
部署成功后,会无法获取指标,报错提示 error: metrics not available yet
- 根据https://github.com/kubernetes-sigs/metrics-server/issues/143#issuecomment-477635264 这个 issue,修改 coredns 的的 configmap
- 根据https://github.com/kubernetes-sigs/metrics-server/issues/143#issuecomment-469480247,给 metrics-server 添加运行时参数,因为 metrics-server 会从 kubelet 获取数据,但是 kubelet 需要认证,所以添加参数来跳过认证。
Note:Metrics Server 只能实现核心指标的 API,想要使用自定义指标的 API,可以参考下文的 prometheus-adpter
metrics-server 的部署文件在这个网址中:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
prometheus-adapter
kube-state-metrics
系统组件指标
K8S 集群中常用的 exporter
可以在这里看到官方、非官方的 exporter。如果还是没满足你的需求,你还可以自己编写 exporter,简单方便、自由开放,这是优点。
但是过于开放就会带来选型、试错成本。之前只需要在 zabbix agent 里面几行配置就能完成的事,现在你会需要很多 exporter 搭配才能完成。还要对所有 exporter 维护、监控。尤其是升级 exporter 版本时,很痛苦。非官方 exporter 还会有不少 bug。这是使用上的不足,当然也是 Prometheus 的设计原则。
K8S 生态的组件都会提供 / metric 接口以提供自监控,这里列下我们正在使用的:
- cadvisor: 集成在 Kubelet 中。
- kubelet: 10255 为非认证端口,10250 为认证端口。
- apiserver: 6443 端口,关心请求数、延迟等。
- scheduler: 10251 端口。
- controller-manager: 10252 端口。
- etcd: 如 etcd 写入读取延迟、存储容量等。
- docker: 需要开启 experimental 实验特性,配置 metrics-addr,如容器创建耗时等指标。
- kube-proxy: 默认 127 暴露,10249 端口。外部采集时可以修改为 0.0.0.0 监听,会暴露:写入 iptables 规则的耗时等指标。
- kube-state-metrics: K8S 官方项目,采集 pod、deployment 等资源的元信息。
- Node Exporter: Prometheus 官方项目,采集机器指标如 CPU、内存、磁盘。
- blackbox_exporter: Prometheus 官方项目,网络探测,dns、ping、http 监控
- process-exporter: 采集进程指标
- nvidia exporter: 我们有 gpu 任务,需要 gpu 数据监控
- node-problem-detector: 即 npd,准确的说不是 exporter,但也会监测机器状态,上报节点异常打 taint
- 应用层 exporter: mysql、nginx、mq 等,看业务需求。
还有各种场景下的自定义 exporter,如日志提取后面会再做介绍。
Kubernetes Event Exporter
参考:
将 Kubernetes 中 Event 资源的内容导出到多个目的地
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.