CPU资源的调度和管理(CFS)
概述
参考:
一、前言
在使用 Kubernetes 的过程中,我们看到过这样一个告警信息:
[K8S]告警主题: CPUThrottlingHigh
告警级别: warning
告警类型: CPUThrottlingHigh
故障实例:
告警详情: 27% throttling of CPU in namespace kube-system for container kube-proxy in pod kube-proxy-9pj9j.
触发时间: 2020-05-08 17:34:17
这个告警信息说明 kube-proxy 容器被 throttling 了,然而查看该容器的资源使用历史信息,发现该容器以及容器所在的节点的 CPU 资源使用率都不高:

告警期间容器所在节点 CPU 使用率

告警期间 kube-proxy 的资源使用率
经过我们的分析,发现该告警实际上是和 Kubernetes 对于 CPU 资源的限制和管控机制有关。Kubernetes 依赖于容器的 runtime 进行 CPU 资源的调度,而容器 runtime 以 Docker 为例,是借助于 cgroup 和 CFS 调度机制进行资源管控。本文基于这个告警案例,首先分析了 CFS 的基本原理,然后对于 Kubernetes 借助 CFS 进行 CPU 资源的调度和管控方法进行了介绍,最后使用一个例子来分析 CFS 的一些调度特性来解释这个告警的 root cause 和解决方案。
二、CFS 基本原理
2.3 运行和观察
部署这样一个 yaml POD:
apiVersion: v1
kind: Pod
metadata:
name: busybox
labels:
app: busybox
spec:
containers:
- image: busybox
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
command:
- "/bin/sh"
- "-c"
- "while true; do sleep 10; done"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
可以看到该容器内部的进程对应的 CPU 调度信息变化如下:
[root@k8s-node-04 ~]# cat /proc/121133/sched
sh (121133, #threads: 1)
-------------------------------------------------------------------
se.exec_start : 20229360324.308323
se.vruntime : 0.179610
se.sum_exec_runtime : 31.190620
se.nr_migrations : 12
nr_switches : 79
nr_voluntary_switches : 78
nr_involuntary_switches : 1
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 26
mm->numa_scan_seq : 0
numa_migrations, 0
numa_faults_memory, 0, 0, 0, 0, -1
numa_faults_memory, 1, 0, 0, 0, -1
numa_faults_memory, 0, 1, 1, 0, -1
numa_faults_memory, 1, 1, 0, 0, -1
[root@k8s-node-04 ~]# cat /proc/121133/sched
sh (121133, #threads: 1)
-------------------------------------------------------------------
se.exec_start : 20229480327.896307
se.vruntime : 0.149504
se.sum_exec_runtime : 33.325310
se.nr_migrations : 17
nr_switches : 91
nr_voluntary_switches : 90
nr_involuntary_switches : 1
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 31
mm->numa_scan_seq : 0
numa_migrations, 0
numa_faults_memory, 0, 0, 1, 0, -1
numa_faults_memory, 1, 0, 0, 0, -1
numa_faults_memory, 0, 1, 0, 0, -1
numa_faults_memory, 1, 1, 0, 0, -1
[root@k8s-node-04 ~]# cat /proc/121133/sched
sh (121133, #threads: 1)
-------------------------------------------------------------------
se.exec_start : 20229520328.862396
se.vruntime : 1.531536
se.sum_exec_runtime : 34.053116
se.nr_migrations : 18
nr_switches : 95
nr_voluntary_switches : 94
nr_involuntary_switches : 1
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 34
mm->numa_scan_seq : 0
numa_migrations, 0
numa_faults_memory, 0, 0, 0, 0, -1
numa_faults_memory, 1, 0, 0, 0, -1
numa_faults_memory, 0, 1, 1, 0, -1
numa_faults_memory, 1, 1, 0, 0, -1
其中 sum_exec_runtime 表示实际运行的物理时间。
三、Kubernetes 借助 CFS 进行 CPU 管理
3.1 CFS 进行 CPU 资源限流(throtting)的原理
根据文章《Kubernetes 生产实践系列之三十:Kubernetes 基础技术之集群计算资源管理》的描述,Kubernetes 的资源定义:
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
比如里面的 CPU 需求,会被翻译成容器 runtime 的运行时参数,并最终变成 cgroups 和 CFS 的参数配置:
cat cpu.shares
256
cat cpu.cfs_quota_us
50000
cat cpu.cfs_period_us
100000
这里有一个默认的参数:
cat /proc/sys/kernel/sched_latency_ns
24000000
所以在这个节点上,正常压力下,系统的 CFS 调度周期是 24ms,CFS 重分配周期是 100ms,而该 POD 在一个重分配周期最多占用 50ms 的时间,在有压力的情况下,POD 可以占据的 CPU share 比例是 256。
下面一个例子可以说明不同资源需求的 POD 容器是如何在 CFS 的调度下占用 CPU 资源的:
 CPU 资源配置和 CFS 调度
CPU 资源配置和 CFS 调度
在这个例子中,有如下系统配置情况:
- CFS调度周期为10ms,正常负载情况下,进程ready队列里面的进程在每10ms的间隔内都会保证被执行一次
- CFS重分配周期为100ms,用于保证一个进程的limits设置会被反映在每100ms的重分配周期内可以占用的CPU时间数,在多核系统中,limit最大值可以是 CFS重分配周期*CPU核数
- 该执行进程队列只有进程A和进程B两个进程
- 进程A和B定义的CPU share占用都一样,所以在系统资源紧张的时候可以保证A和B进程都可以占用可用CPU资源的一半
- 定义的CFS重分配周期都是100ms
- 进程A在100ms内最多占用50ms,进程B在100ms内最多占用20ms
所以在一个CFS重分配周期(相当于10个CFS调度周期)内,进程队列的执行情况如下:
- 在前面的4个CFS调度周期内,进程A和B由于share值是一样的,所以每个CFS调度内(10ms),进程A和B都会占用5ms
- 在第4个CFS调度周期结束的时候,在本CFS重分配周期内,进程B已经占用了20ms,在剩下的8个CFS调度周期即80ms内,进程B都会被限流,一直到下一个CFS重分配周期内,进程B才可以继续占用CPU
- 在第5-7这3个CFS调度周期内,由于进程B被限流,所以进程A可以完全拥有这3个CFS调度的CPU资源,占用30ms的执行时间,这样在本CFS重分配周期内,进程A已经占用了50ms的CPU时间,在后面剩下的3个CFS调度周期即后面的30ms内,进程A也会被限流,一直到下一个CFS重分配周期内,进程A才可以继续占用CPU
如果进程被限流了,可以在如下的路径看到:
cat /sys/fs/cgroup/cpu/kubepods/pod5326d6f4-789d-11ea-b093-fa163e23cb69/69336c973f9f414c3f9fdfbd90200b7083b35f4d54ce302a4f5fc330f2889846/cpu.stat
nr_periods 14001693
nr_throttled 2160435
throttled_time 570069950532853
3.2 本文开头问题的原因分析
根据 3.1 描述的原理,很容易理解本文开通的告警信息的出现,是由于在某些特定的 CFS 重分配周期内,kube-proxy 的 CPU 占用率超过了给它分配的 limits,而参看 kube-proxy daemonset 的配置,确实它的 limits 配置只有 200ms,这就意味着在默认的 100ms 的 CFS 重调度周期内,它只能占用 20ms,所以在特定繁忙场景会有问题:

cat cpu.shares
204
cat cpu.cfs_period_us
100000
cat cpu.cfs_quota_us
20000
注:这里 cpu.shares 的计算方法如下:200x1024/1000~=204
而这个问题的解决方案就是将 CPU limits 提高。
Zalando 公司有一个分享《Optimizing Kubernetes Resource Requests/Limits for Cost-Efficiency and Latency / Henning Jacobs》很好的讲述了 CPU 资源管理的问题,可以参考,这个演讲的 PPT 在这里可以找到。
更具体问题分析和讨论还可以参考如下文章:
- CPUThrottlingHigh false positives #108
- CFS quotas can lead to unnecessary throttling #67577
- CFS Bandwidth Control
- Overly aggressive CFS
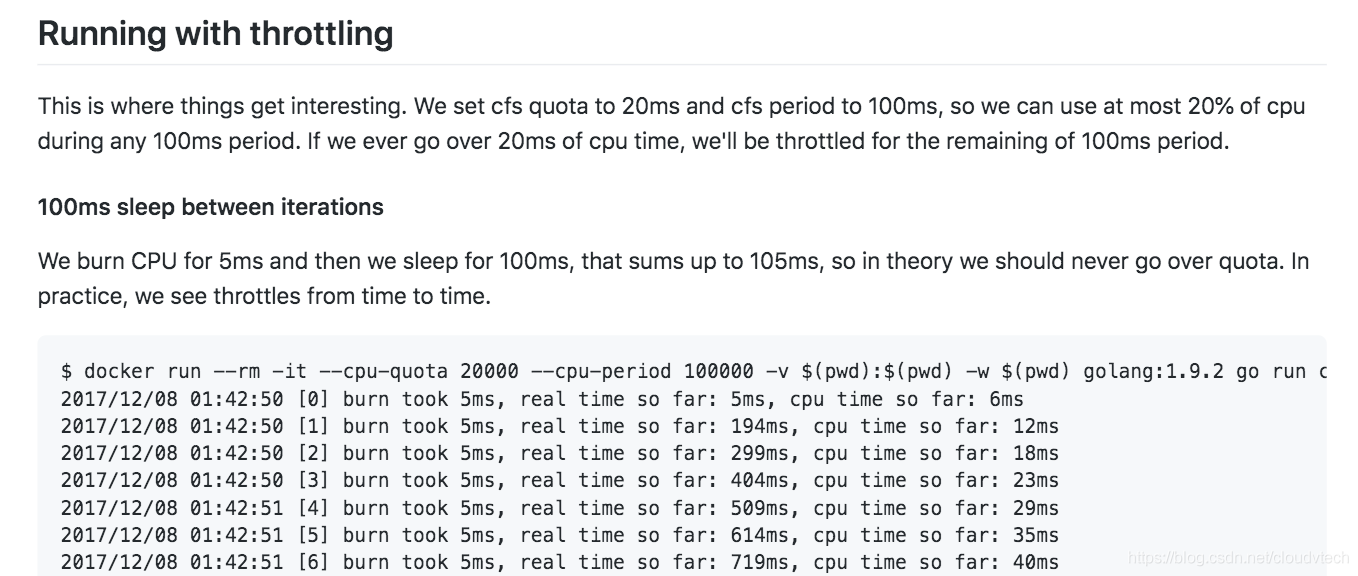
其中《Overly aggressive CFS》里面还有几个小实验可以帮助大家更好的认识到 CFS 进行 CPU 资源管控的特点:
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.