Model
概述
参考:
执行机器学习涉及创建 Model(模型),这个模型狭义上指数学模型中的统计模型,是一种数学表示,用于描述和解决特定类型的问题。这些模型可以是各种各样的,包括传统的统计学模型,如线性回归和逻辑回归,也可以是基于神经网络的深度学习模型,如卷积神经网络和循环神经网络。
模型通常由 数学公式、超参数、参数 组成,可以根据给定的输入数据进行训练和调整,以使它们能够在未见过的数据上进行准确预测或分类。因此,AI 领域中的模型本质上是一种数学模型,通过使用数学方法来处理和分析数据,以解决各种问题,如分类、预测、图像处理、自然语言处理等。
- 数学公式 # 模型的结构通常用数学公式表示,e.g. 线性变换、激活函数、etc. 。e.g. 线性层的计算: $y = Wx + b$ ,其中 W 是权重矩阵,x 是输入向量,b 是偏置。
- Hyperparameter(超参数) # 训练和模型架构设置中手动配置的参数,影响模型的性能和训练过程。常见的超参数包括:学习率、批量大小、网络层数和每层的神经元数量、激活函数类型、训练轮数、etc. 。而其他参数(例如节点权重)的值是通过训练得出的。
- Parameters(参数) # 模型训练过程中学习到的一系列数值,e.g. 权重、etc. 。它们决定了输入数据如何影响模型的输出。
模型需要训练,训练后得到的模型文件是一系列的权值(权重值),通常是大量(上亿)个浮点数,如果进行了模型量化,也可以是整数。
学习资料
B 站 - 飞天闪客,【闪客】10分钟理清3000+开源模型 # 模型是什么,量化模型是什么,微调是什么,模型怎么命名,如何将众多模型归纳为几种本质的模型。
- model_type 是抽象层次更高的,描述模型架构体系。模型仓库中的 config.json 中有这个字段
- 模型架构来源:Llama ——> Transformer
创建模型
想要创建一个可用的模型,通常至少需要如下几步:
- 定义模型结构 # 选择模型类型等。比如
nn.Linear(10, 1)定义了一个简单的全连接层。 - TODO:定义损失函数和优化器 # 如交叉熵损失、均方误差,以及优化算法如 SGD、Adam。
- 激活函数 # 每个神经元应用的非线性函数,用于引入非线性,使模型能够学习复杂的模式。
- 损失函数 # 用于衡量模型输出与实际目标之间的差异。在训练过程中,模型会尝试最小化损失函数。
- 标注数据 # 标注数据以生成数据集用以训练模型
- 训练模型 # 利用数据集训练模型。通过给模型输入数据集和目标,让模型经过计算后调整自身参数(权重)。
- 保存模型 # 在训练完毕后保存模型,以便后续测试或部署。
暂时先用下面的代码尝试理解一下,随着后续深入学习逐步完善:
import torch
from torch import nn
# 一、定义模型结构
# Linear() 可以暂时理解为使用 Linear 模型,可以假设模型是 y = xA^T + b;
# 10, 1 可以理解为 超参数。也可以简单理解为是在训练模型以检查返回值 fc 是否满足预期
fc = nn.Linear(10, 1)
# 二、定义损失函数、优化器
# 略
# 三、训练模型
# 注意:fc.state_dict() 并不是真正意义上的训练模型。仅是获取模型的当前参数(e.g. 权重值、etc.)这些参数可能是刚初始化的(随机值),也可能是已经训练过的。
# 通常,在训练完成后调用 state_dict() 来保存模型的参数。这样可以在之后加载这些参数,继续训练或进行推理。
model = fc.state_dict()
# 四、保存模型
# 将训练结果 fc 保存到模型文件 hello_world.pth 中
torch.save(model, "./models/hello_world.pth")
# 从 hello_world.pth 模型文件中读取参数
weight = torch.load("./models/hello_world.pth", weights_only=True)
# 模型文件中的内容本质上是一系列权重值的集合,效果如下:
# OrderedDict({'weight': tensor([[0.0382, -0.1313, 0.2224, -0.2967, -0.2892, -0.2951, 0.0455, -0.0702,
# -0.2919, 0.2825]]), 'bias': tensor([-0.2147])})
print(weight)
[!Note] 个人理解 nn.Linear() 就像编程体系中的汇编,是所有高级模型的基础。只不过还有很多不同点,比如 汇编没有训练的概念、etc. 。
似乎,从这种底层逻辑看,所有模型其实都是一样的,底层只有像 Linear() 之类的简单线性层,不同点在于高级模型会用到 非常多的层数、训练方式、训练数据。
Training
参考:
- Wiki, Machine_learning - Training_models
- Wiki, raining, validation, and test data sets
- https://en.wikipedia.org/wiki/Training#Artificial-intelligence_feedback
- https://easyaitech.medium.com/%E4%B8%80%E6%96%87%E7%9C%8B%E6%87%82-ai-%E6%95%B0%E6%8D%AE%E9%9B%86-%E8%AE%AD%E7%BB%83%E9%9B%86-%E9%AA%8C%E8%AF%81%E9%9B%86-%E6%B5%8B%E8%AF%95%E9%9B%86-%E9%99%84-%E5%88%86%E5%89%B2%E6%96%B9%E6%B3%95-%E4%BA%A4%E5%8F%89%E9%AA%8C%E8%AF%81-9b3afd37fd58
Training(训练) 模型最基本需要如下几样东西
- 原始模型
- Hyperparameter(超参数)
- Dataset(数据集)
加载原始模型,设置超参数,将数据集的数据转为模型可以识别的数值,一遍一遍训练,最后得出一组参数。
在开始训练之前,通常需要准备三个数据集,分别用于 训练、验证、测试:
- Training datasets(训练数据集)
- Validation datasets(验证数据集)
- Test datasets(测试数据集)
先使用训练数据集对模型进行最初的训练生成参数;然后使用验证数据集对训练后的模型进行评估打分,调整参数纠正训练中的偏差;最后使用测试数据集对模型评估打分。
一个模型的权重在没有训练之前通常都有一个默认值(0 - 1 的正态分布)。训练模型一般是指将数据集提供给模型后,数据将会转为一组数值,模型根据这组数值调整权重,随着一次一次的训练,模型会不断更新这些权重,直到满足最终目标。
通过模型配套的程序,将数据集交给原始模型并训练 N epoch(周期),最终得到可以执行特定任务的模型(识别对象、沟通、etc.)
[!Tip] 不同的模型(计算机视觉、自然语言处理、etc.)训练时,可能需要一些特定于该种类模型的东西。
TODO:
注意日常口语化的名词 调参,调的是什么参?超参?权重?还是什么?
写好模型后,向模型中传入参数用结果与历史真实结果对比,差值越小,模型越精准?若是差值大就修改参数,直到最后差值无限接近 0 ?
训练场景
https://www.baeldung.com/cs/neural-network-pre-training
- Pre-training(预训练)
- Fine-tuning(微调)
- Instruct-tuning(指令调整) TODO: 是个较新得概念
假设我们想要对一个包含猫和狗的数据集进行分类。我们开发了一个机器学习模型来完成这个分类任务。一旦训练完成,我们就将模型及其所有参数保存下来。现在假设我们有另一个任务要完成: 物体检测。我们不是从头开始训练新模型,而是在物体检测数据集上使用这个已有的模型。我们把这种方法称为预训练。
微调是指给模型一些新的数据,比如使用标注得更精准得数据集让模型效果更好;或者使用一些新的数据集让模型认识少量新的目标。
虽然将训练方式分成了三类,但是本质上,这三种说法其实都是训练模型
模型文件格式
ONNX 是业界通用的格式,还有很多特定于项目的格式。
绝大部分模型,都支持导出成 .onnx 格式。e.g. Yolo 可以导出成 .onnx,也支持导出成用于 PyTorch 的 torchscript 格式,etc.
ONNX
参考:
Open Neural Network Exchange (开放神经网络交换,简称:ONNX) 是一个开放的生态系统,使人工智能开发人员能够随着项目的发展选择正确的工具。 ONNX 为人工智能模型(深度学习和传统机器学习)提供开源格式。它定义了可扩展的计算图模型,以及内置运算符和标准数据类型的定义。目前我们重点关注推理(评分)所需的能力。
人话:机器学习互操作性的开放标准,就是协议,也就是定义了模型应该用什么的方式 读/写,用什么格式存储。
模型可视化
参考:
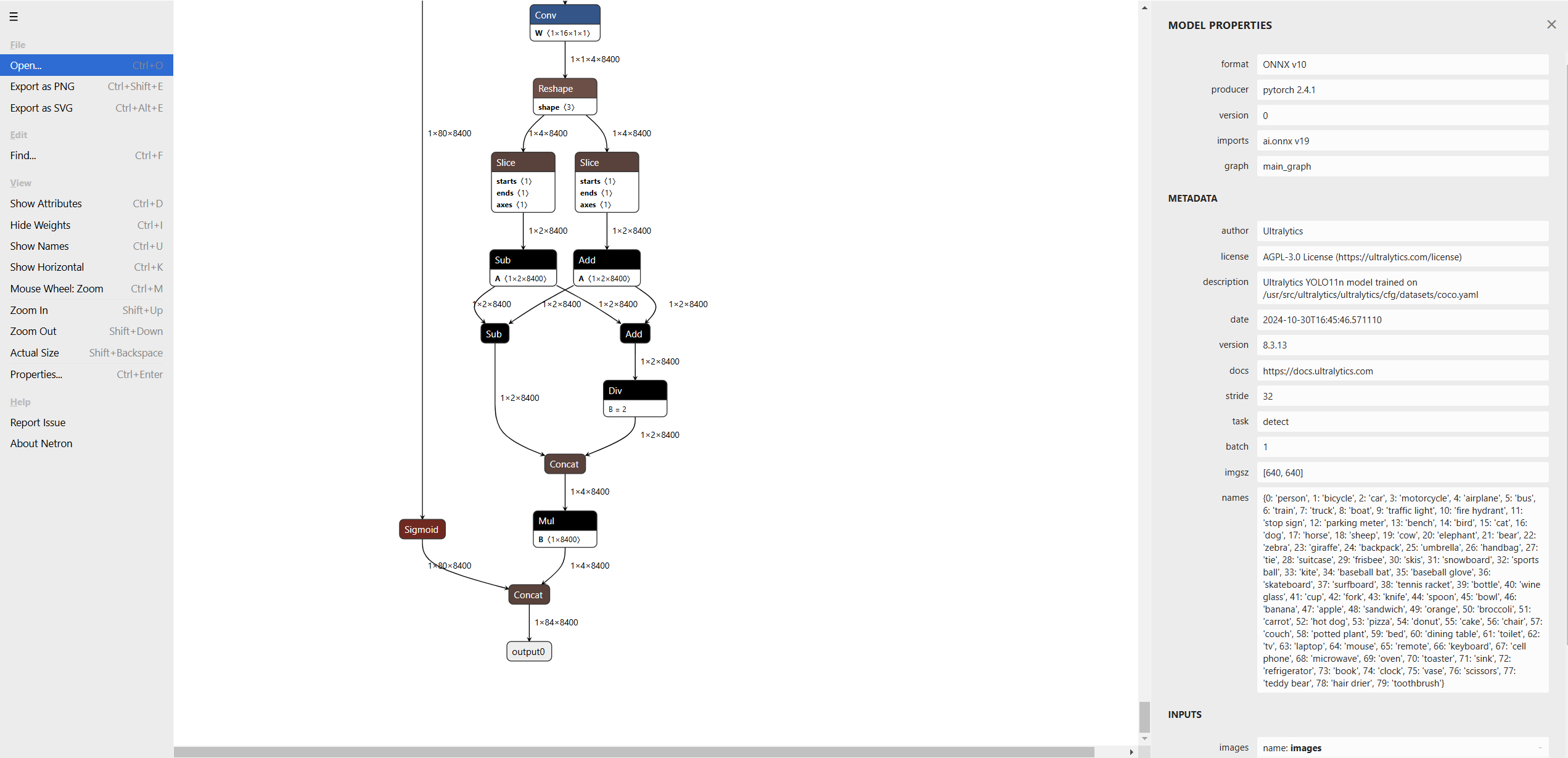
Netron 是用于神经网络、深度学习和机器学习模型的可视化工具
下面是 https://netron.app/ 可视化模型的效果,可以显示模型的神经结构以及参数,每个小方框都可以惦记查看具体数据
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.