YOLO
概述
参考:
- GitHub 组织,ultralytics
- GitHub 项目,ultralytics/ultralytics
- GitHub 项目,ultralytics/assets Ultralytics 的模型、数据集、etc. 资产
- ultralytics 官网
- YOLO 的歷史進程!YOLO 大補帖!
- https://www.bilibili.com/video/BV1sCtHewEw7 v8 与 v10 的选择,为什么不要用 v10 而是用 v8,为什么 v10 的检测效果不好
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。
2015 年 Joseph Redmon 提出的 YOLO 橫空出世,从诞生的那一刻起就标榜「高精度」、「高效率」、「高实用性」,為 One-Stage 方法在物体侦测演算法里拉开序幕。
- YOLOv1 (2016) Joseph Redmon
- YOLOv2 (2017) Joseph Redmon
- YOLOv3 (2018) Joseph Redmon
- 突发
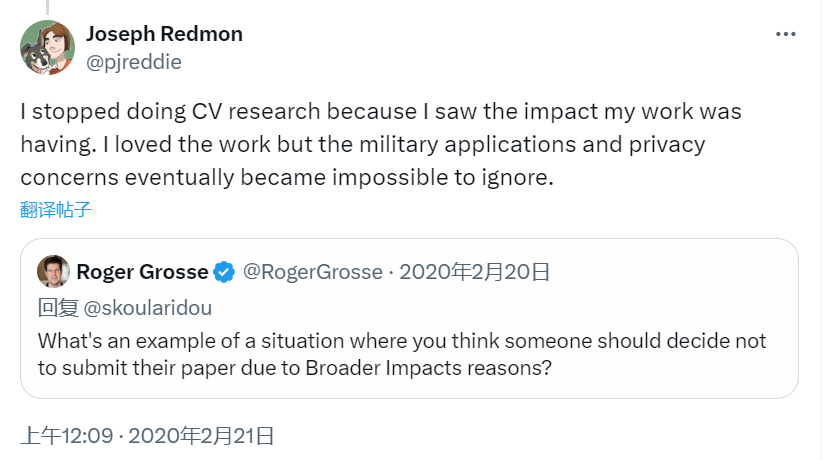
- 然而,2020 年 约瑟夫·雷德蒙 突然投下一枚重磅炸弹,他受够 YOLO 不断被运用在军事应用以及个人隐私,宣布停止电脑视觉相关的研究。
- YOLOv4 (2020) Alexey Bochkovskiy
- YOLOv5 进一步提高了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为常用导出格式等新功能。
- YOLOv6 (2022) 由美团开源,目前已用于该公司的许多自主配送机器人。
- YOLOv7 增加了额外的任务,如 COCO 关键点数据集的姿势估计
- YOLOv8 (2023-01) 由 Ultralytics 提供。YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性使用户能够在各种应用和领域中利用 YOLOv8 的功能。
- YOLOv9 (2024) 由原YOLOv7团队打造,引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
- YOLOv10 (2024) 是由清华大学的研究人员使用 Ultralytics Python 包创建的。该版本通过引入消除非极大值抑制 (NMS) 要求的端到端头,提供了实时对象检测方面的改进。
- YOLO11
训练
https://docs.ultralytics.com/modes/train/
训练前需要准备如下内容:
- data.yaml 文件
- dataset
最基本的训练代码如下:
from ultralytics import YOLO
# 加载预训练模型(建议用于训练)
model = YOLO("yolo11n.pt")
# 训练模型。指定 coco.yaml 为 data.yaml。训练周期 100,TODO: 640 是干什么的?好像是图片大小?
results = model.train(data="coco.yaml", epochs=100, imgsz=640)
数据集
参考:
Ultralytics 提供对各类 Dataset(数据集) 的支持,以便进行计算机视觉任务,如 对象检测、实例分割、姿态估计、分类、多目标跟踪、etc.
- Object detection(对象检测) 数据集 # 通过在每个对象周围绘制边界框来检测和定位图像中的对象。
- Instance segmentation(实例分割) 数据集 # 在像素级别识别和定位图像中的对象。Object detection 在识别到对象后是用矩形框框起来的,而 Instance segmentation 则是在识别到对象的基础上,在像素级别对物体进行染色
- Pose estimation(姿态估计) 数据集 # 在识别到对象后,识别对象的姿态。
- etc.
Ultralytics YOLO 的 检测、分段、姿势 模型在 COCO 数据集上预训练,而 分类 模型在 ImageNet 数据集上预训练。
创建自己的数据集
https://docs.ultralytics.com/datasets/#contribute-new-datasets
- Collect Images(收集图像) # 收集用于训练的图像。
- Annotate Images(注释图像) # 根据想要训练的任务,使用 边界框、片段、关键点 为图像添加注释。人话:数据标注
- Export Annotations(导出注释) # 将这些注释转换为 Ultralytics 支持的 YOLO
*.txt文件格式。 - Organize Dataset(组织数据集) # 将图像、注释以如下目录结构存放。应该有 images/ 和 labels/ 顶级目录,并在每个目录中都有一个 train/ 和 val/ 子目录。 images 存放收集到的图像,labels 存放导出的注释。images/ 下的如果有 000000000009.jpg 文件,那对应的 labels/ 下应该有个同名不同后缀的 000000000009.txt 文件。
- Notes: 这个目录结构在由于实际情况可能有的类型的数据集并不完全相同,基于数据组织的便利性,可能会把 train/ 和 val/ 放在顶级目录,下级目录可能是以对象类型命名。
datasets/
└── coco8
├── images
│ ├── train
│ │ ├── 000000000009.jpg
│ │ └── 000000000034.jpg
│ └── val
│ ├── 000000000036.jpg
│ └── 000000000061.jpg
└── labels
├── train
│ ├── 000000000009.txt
│ └── 000000000034.txt
└── val
├── 000000000036.txt
└── 000000000061.txt
- 创建
data.yaml文件 # 创建一个描述数据集、类和其他必要信息的 data.yaml 文件。 - Optimize Images(优化图像)(可选的) # 如果您想减小数据集的大小以提高处理效率,可以使用以下代码优化图像。这不是必需的,但建议用于较小的数据集大小和更快的下载速度。
- 压缩数据集 # 将整个数据集文件夹压缩为 zip 文件。
- Document and PR # 创建一个文档页面来描述数据集以及它如何适应现有框架。之后,提交 Pull Request (PR)。有关如何提交 PR 的更多详细信息,请参阅 Ultralytics 贡献指南。
第 6 和 7 步,ultralytics 提供了函数可以直接使用代码处理。通过遵循这些步骤,可以提供一个与 Ultralytics 现有结构良好集成的新数据集
from pathlib import Path
from ultralytics.data.utils import compress_one_image
from ultralytics.utils.downloads import zip_directory
# Define dataset directory
path = Path("path/to/dataset")
# Optimize images in dataset (optional)
for f in path.rglob("*.jpg"):
compress_one_image(f)
# Zip dataset into 'path/to/dataset.zip'
zip_directory(path)
data.yaml
data.yaml 时 Ultralytics YOLO 数据集使用的 YAML 格式文件,可以定义数据集所在目录、训练、验证、测试 图像目录、数据集中对象分类的字典。在 这里 找到各类数据集的 data.yaml。
Notes: data.yaml 是一种抽象的叫法,本质就是配置文件。各种数据集使用 data.yaml 时,可以指定任意名称但只要符合文件内容格式的 YAML 文件。
e.g. 对象检测 类型的数据集配置通常是下面这样的:
path: ../datasets/coco8 # 数据集根目录
train: images/train # 相对于 path 的训练目录
val: images/val # 相对于 path 的验证目录
test: # (可选的)相对于 path 的测试目录
# 类型
names:
0: person
# ......略
5: bus
# ......略
79: toothbrush
下图是使用上面示例的 data.yaml 训练后模型识别的结果,可以看到有 person 和 bus,并不是单纯的数字了,在右边官网示例图片中,识别出的对象都是数字注释的。

当我们训练模型时,下面代码就会指定要使用的 data.yaml 文件(这示例的 data.yaml 名为 coco.yaml)
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco.yaml", epochs=100, imgsz=640)
然后根据 data.yaml 中的 path、train、val 定义的路径,从目录中读取 图像文件 及 图像注释文件。这些文件组织结构像这样:
datasets/
└── coco8
├── images
│ ├── train
│ │ ├── 000000000009.jpg
│ │ └── 000000000034.jpg
│ └── val
│ ├── 000000000036.jpg
│ └── 000000000061.jpg
└── labels
├── train
│ ├── 000000000009.txt
│ └── 000000000034.txt
└── val
├── 000000000036.txt
└── 000000000061.txt
数据集种类
Object detection
https://docs.ultralytics.com/datasets/detect/
Object detection(对象检测)
images 是图片,labels 图片的标签
datasets/
└── coco8
├── LICENSE
├── README.md
├── images
│ ├── train
│ │ ├── 000000000009.jpg
│ │ ├── 000000000025.jpg
│ │ ├── 000000000030.jpg
│ │ └── 000000000034.jpg
│ └── val
│ ├── 000000000036.jpg
│ ├── 000000000042.jpg
│ ├── 000000000049.jpg
│ └── 000000000061.jpg
└── labels
├── train
│ ├── 000000000009.txt
│ ├── 000000000025.txt
│ ├── 000000000030.txt
│ └── 000000000034.txt
├── train.cache
├── val
│ ├── 000000000036.txt
│ ├── 000000000042.txt
│ ├── 000000000049.txt
│ └── 000000000061.txt
└── val.cache
label 是对应相同文件名的图片中的 ROI,共 5 个数字
- ROI 类型
- ROI 左上角 x 轴坐标
- ROI 左上角 y 轴坐标
- ROI 右下角 x 轴坐标
- ROI 右下角 y 轴坐标
~]# cat datasets/coco8/labels/train/000000000025.txt
23 0.770336 0.489695 0.335891 0.697559
23 0.185977 0.901608 0.206297 0.129554
Instance segmentation
https://docs.ultralytics.com/datasets/segment/
Pose estimation
https://docs.ultralytics.com/datasets/pose/
Pose estimation(姿态估计)
YAML 格式 https://docs.ultralytics.com/datasets/pose/#dataset-yaml-format
模型
参考:
https://docs.ultralytics.com/models/yolov10/#model-variants
Ultralytics 的 YOLO 有多种模型规模,以满足不同的应用需求:
- YOLO-N # Nano 适用于资源极其有限的环境的。适合移动设备和快速测试
- YOLO-S # Small 平衡速度和准确性的小型版本。适合嵌入式设备和一般性测试
- YOLO-M # Medium 用于通用用途。
- YOLO-B # Balanced 增加宽度以提高精度。
- YOLO-L # Large 增加计算资源为代价获得更高的精度。
- YOLO-X # Extra-large 可实现最大精度和性能。适合服务器处理高精度任务
关联文件与配置
%APPDATA%/Ultralytics/ # Ultralytics 出的 YOLO 模型在使用时保存的 字体、配置 所在目录
- ./settings.json # 有一些保存文件的目录配置。
CLI
https://docs.ultralytics.com/usage/cli/
Syntax(语法)
SubCommand
- train # Train(训练) 模型
- predict # 使用经过训练的 YOLO11n 模型对图像进行 predictions(预测)。
- val # 在 COCO8 数据集上 Validate(验证) 经过训练的 YOLO11n 模型的准确性。不需要参数,因为模型保留其训练数据和参数作为模型属性。
- export # 将 YOLO11n 模型导出为不同的格式,例如 ONNX、CoreML、etc. 。
最佳实践
https://www.youtube.com/watch?v=7YRJIAIhMpw
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.