Model
概述
参考:
Model(模型),狭义上指数学模型中的统计模型,是一种数学表示,用于描述和解决特定类型的问题。这些模型可以是各种各样的,包括传统的统计学模型,如线性回归和逻辑回归,也可以是基于神经网络的深度学习模型,如卷积神经网络和循环神经网络。
模型可以根据给定的输入数据进行训练和调整,以使它们能够在未见过的数据上进行准确预测或分类(线性回归的逻辑)。因此,AI 领域中的模型,本质上是一种数学模型,通过使用数学方法来处理和分析数据,以解决各种问题,如 分类、预测、图像处理、自然语言处理 等。
在 Machine learning 领域,Model(模型) 可以代指多个不同层次的概念,可以是 数学公式、一个模型文件、一组模型文件、提供推理的模型服务、等等。
从广义角度看,模型通常由如下几个部分组成
- Architecture(架构) # 模型架构是一组代码,定义神经网络结构与计算方式。本质是数学公式的代码化表达。
- 若是没有参数,无法单独使用。用来定义如何使用 Parameters
- 简单粗暴点理解的化,最底层就是 nn.Linear。😂
- Parameters(参数) # i.e. Weight(权重),用于表示模型从数据中学习到的特征,也可以理解为模型的状态(特征/状态是一系列数值,用 Tensor(张量) 记录)。
- 若是没有架构,无法单独使用。用来为架构提供有状态的信息。
- 由于权重文件需要消耗大量空间,所以诞生多种 权重格式。
- Data processing(数据处理) # 提供 “人类可理解的信息” 与 “Tensor” 之间的相互转换逻辑。
- 由于模型保存的都是 Tensor。所以需要把 人类可读的文件、可看的图片、etc. 转为 Tensor,以便输入给模型;或者在模型输出 Tensor 之后,转换为人类可理解的信息。
- 对于 NLP 来说,Tokenization(分词器) 是典型的数据处理器;对于 CV 来说,Transform(TODO: 需要总结) 是典型的数据处理器
从狭义角度看,我们也可以把模型理解为 单一的权重文件、单一的公式,都算模型吧~ 主要看我们日常交流的语境是什么了。甚至若是从广义角度看,那些可以提供模型推理能力的 WebAPI 也可以是模型的一部分。
个人理解:架构 + 参数 = 模型。哪怕没有数据处理,模型本身依然成立,但是只有架构或者只有参数,模型本身就不成立。数据处理只是让模型可以被用起来而已。
[!Note] Hyperparameter(超参数)
Hyperparameter(超参数) 本质是是一些边界条件,用来约束 不同生态的模型架构的行为、或者训练与推理任务的行为、etc.
训练和模型架构设置中手动配置的参数,影响模型的性能和训练过程。常见的超参数包括:学习率、批量大小、神经网络层数和每层的神经元数量、激活函数类型、训练轮数、etc. 。
[!Example]
用 Hugging Face 生态的模型举例,一个完整的模型通常有这些文件。
为了减少复杂性,也有很多设计将这些文件合并成一个文件,e.g. llama.cpp 的 GGUF 格式文件、etc.
模型需要 Training(训练),训练后可以得到一系列的权重值(海量的 Tensor),这些 Tensor 以特定格式保存到文件中。Tensor 中通常是大量(上亿)个浮点数,如果进行了模型量化,也可以是整数。
训练好的模型可以进行 Inference(推理),依据输入通过计算预测输出。
[!TODO] 总结一篇专门记录神经网络的文章。用来在上面的 Architecture 描述中引用。
神经网络结构通常是描述输入层、隐藏层、输出层的,描述有多少层、每层有多少神经元、层与层之间如何连接、用什么激活函数、etc.
学习资料
B 站 - 飞天闪客,【闪客】10分钟理清3000+开源模型 # 模型是什么,量化模型是什么,微调是什么,模型怎么命名,如何将众多模型归纳为几种本质的模型。
- model_type 是抽象层次更高的,描述模型架构体系。模型仓库中的 config.json 中有这个字段
- 模型架构来源:各大厂商的模型结构来源于:Llama(实现) ——> Transformer(理论)。Llama 参考 Transformer 实现了可用的模型架构
[!TODO] ROPE 是什么?
创建模型
想要创建一个可用的模型,通常至少需要如下几步:
- 定义模型结构 # 选择模型类型等。比如
nn.Linear(10, 1)定义了一个简单的全连接层。 - TODO:定义损失函数和优化器 # 如交叉熵损失、均方误差,以及优化算法如 SGD、Adam。
- 激活函数 # 每个神经元应用的非线性函数,用于引入非线性,使模型能够学习复杂的模式。
- 损失函数 # 用于衡量模型输出与实际目标之间的差异。在训练过程中,模型会尝试最小化损失函数。
- 标注数据 # 标注数据以生成数据集用以训练模型
- 训练模型 # 利用数据集训练模型。通过给模型输入数据集和目标,让模型经过计算后调整自身参数(权重)。
- 保存模型 # 在训练完毕后保存模型,以便后续测试或部署。
暂时先用下面的代码尝试理解一下,随着后续深入学习逐步完善:
import torch
from torch import nn
# 一、定义模型结构
# Linear() 可以暂时理解为使用 Linear 模型,可以假设模型是 y = xA^T + b;
# 10, 1 可以理解为 超参数。也可以简单理解为是在训练模型以检查返回值 fc 是否满足预期
fc = nn.Linear(10, 1)
# 二、定义损失函数、优化器
# 略
# 三、训练模型
# 注意:fc.state_dict() 并不是真正意义上的训练模型。仅是获取模型的当前参数(e.g. 权重值、etc.)这些参数可能是刚初始化的(随机值),也可能是已经训练过的。
# 通常,在训练完成后调用 state_dict() 来保存模型的参数。这样可以在之后加载这些参数,继续训练或进行推理。
model = fc.state_dict()
# 四、保存模型权重
# 将训练结果 fc 保存到模型文件 hello_world.pth 中
torch.save(model, "./models/hello_world.pth")
# 从 hello_world.pth 模型文件中读取权重
weight = torch.load("./models/hello_world.pth", weights_only=True)
# 模型文件中的内容本质上是一系列权重值的集合,效果如下:
# OrderedDict({'weight': tensor([[0.0382, -0.1313, 0.2224, -0.2967, -0.2892, -0.2951, 0.0455, -0.0702,
# -0.2919, 0.2825]]), 'bias': tensor([-0.2147])})
print(weight)
[!Note] 个人理解 nn.Linear() 就像编程体系中的汇编,是所有高级模型的基础。只不过还有很多不同点,比如 汇编没有训练的概念、etc. 。
似乎,从这种底层逻辑看,所有模型其实都是一样的,底层只有像 Linear() 之类的简单线性层,不同点在于高级模型会用到 非常多的层数、训练方式、训练数据。
更复杂的模型架构,本质就是无数 Linear() 的堆叠。甚至不同的堆叠方式可以组成一层新的网络,然后这些网络层再组成新的更大的网络层。这就是层层连接的神经网络。像什么 MOE(混合专家模型),就是用一种新的堆叠方式,替代了 FFN(前馈网络) 层。
模型架构
模型架构是控制 Tensor 的方式。
- CNN
- RNN
- GAN
- Transformer
TODO: e.g. 线性变换、激活函数、etc. 。e.g. 线性层的计算: $y = Wx + b$ ,其中 W 是权重矩阵,x 是输入向量,b 是偏置
模型架构体系与分类
[!TODO] 可能的
- Sparse(稀疏) #
- MOE(混合专家) # Transformer 下,训练参数多,推理参数少。不方便微调。
- Dense(稠密)
权重格式
权重格式指储存了权重信息的文件的格式(数据排布、压缩方法、etc.),由于权重数字过于庞大(亿为单位),通常需要压缩储存。另一方面,随着模型的迭代,老的储存格式可能不适应新模型的使用方式
.pt/.pth # PyTorch 原生的格式
ONNX # 是 计算机视觉 业界通用的格式,还有很多特定于项目的格式
- GitHub 项目,onnx/onnx
- 绝大部分模型,都支持导出成 .onnx 格式。e.g. Yolo 可以导出成 .onnx,也支持导出成用于 PyTorch 的 torchscript 格式,etc.
- Open Neural Network Exchange (开放神经网络交换,简称:ONNX) 是一个开放的生态系统,使人工智能开发人员能够随着项目的发展选择正确的工具。 ONNX 为人工智能模型(深度学习和传统机器学习)提供开源格式。它定义了可扩展的计算图模型,以及内置运算符和标准数据类型的定义。目前我们重点关注推理(评分)所需的能力。
- 人话:机器学习互操作性的开放标准,就是协议,也就是定义了模型应该用什么的方式 读/写,用什么格式存储。
- TODO: ONNX 对大语言模型支持不太好,因为 LLM 的动态性(可变长度、KV cache 等)超出了它最初的设计范围。它更多用在传统视觉模型、分类、检测这类任务上。
Safetensors # Hugging Face 生态的模型格式。实现了一种新的简单格式,用于安全地存储张量(与 pickle 不同),而且速度仍然很快(零拷贝)。
etc. # 太多了。。有重点再记
最佳实践
模型可视化
参考:
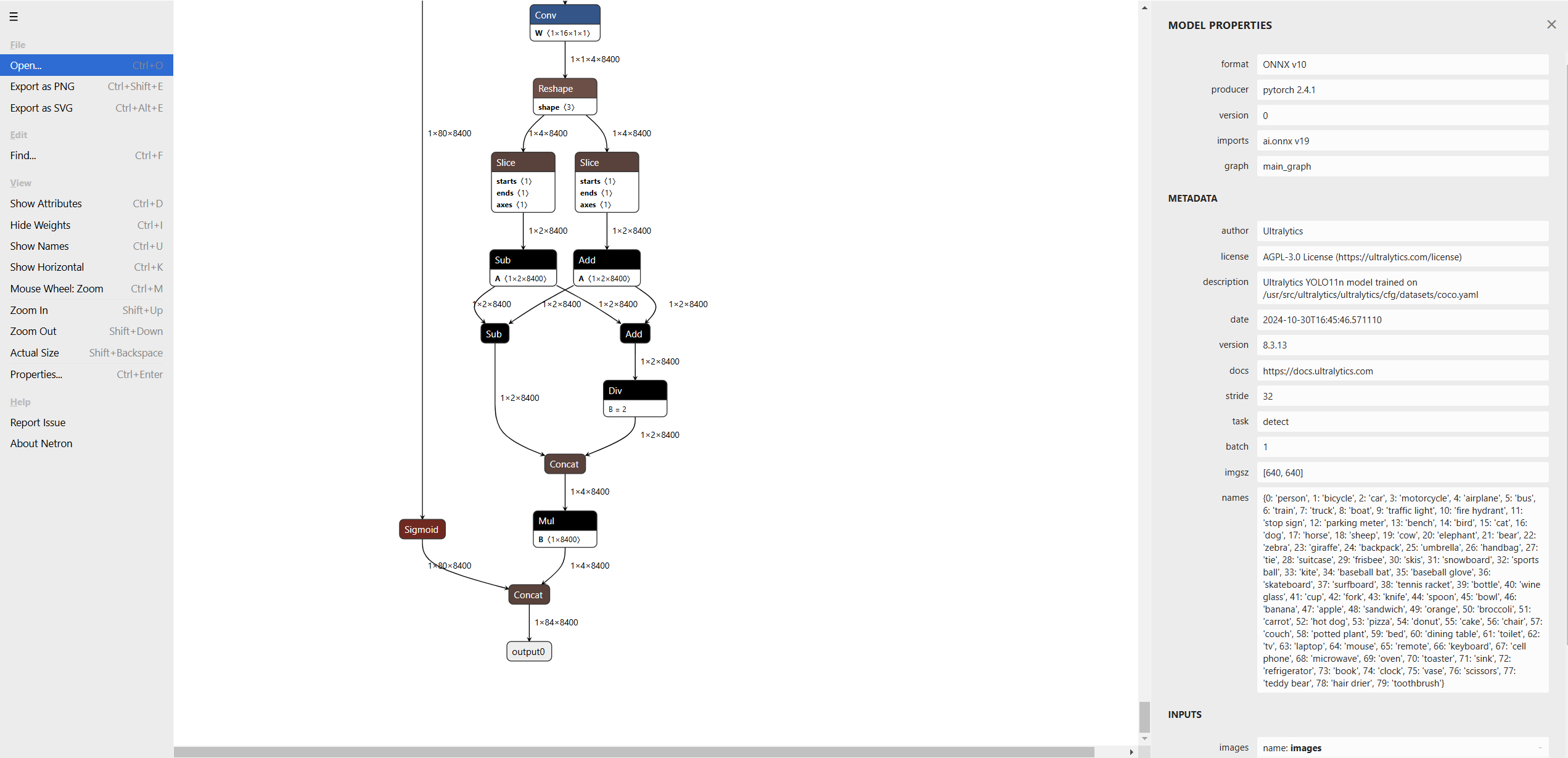
Netron 是用于神经网络、深度学习和机器学习模型的可视化工具
下面是 https://netron.app/ 可视化模型的效果,可以显示模型的神经结构以及参数,每个小方框都可以点击查看具体数据
模型文件命名
Base 结尾的是没有经过微调的模型。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.