ASN.1
概述
参考:
Abstract Syntax Notation One (ASN.1) 是一种标准的 interface description language(接口描述语言),用于定义以跨平台方式序列化和反序列化的数据结构。 它广泛用于电信和计算机网络,尤其是在密码学中。
Abstract Syntax Notation One(抽象语法表示法,简称 ASN.1) 是一个形式化的标准,用于定义抽象数据类型的规范。它广泛用于计算机网络中,用于描述 telecommunications protocols(电信协议) 传输数据时所使用的 formal notation(正式表示法)。
通信设备需要相互传输数据,但是设备可能是由不同厂家生产的,其硬件体系结构、程序语言的语法定义和程序功能实现一般是不相同的。例如,在一台设备中,整形数据类型是 16 位表示,而在另一台则可能用 32 位表示。这些差异导致了同一数据对象在不同的设备上被表示为不同的符号串。为了解决以上问题,ISO 组织推出了抽象语法表符号 1(ASN.1,Abstract Syntax Notation One)。ASN.1 通过定义若干简单类型和复合类型,使得各个设备对其间交换消息的数据类型有了一致的认识。系统的消息发送方采用编码规则(BER、PER)将 ASN.1 描述的消息编码成二进制字节流;消息接受方对收到的字节流进行解码,再转化为符合其自身语法的消息格式。这样,经过 ASN.1 处理的消息独立于应用环境,就不会因为系统终端的区别而产生歧义。基于 H.323 协议的视频会议系统的信令消息就是采用 ASN.1 来表示的。
80 年代初,当时的国际电报电话咨询委员会(CCITT)将应用于 E-mail MHS 协议的基本记法和解码格式进行了标准化,形成了 X.409 方案,这是 ASN.1 的前身。该标准后来被 ISO 组织采用并将其分为抽象语法记法和传输语法,形成了 ISO/IEC 8824 和 ISO/IEC 8825 两个系列标准,且版本在不断更新之中(目前是 2015 年版本)。CCITT 于 1989 年相应地发布了 X.208(ASN.1)和 X.209(BER)取代了 X.409。但后来由国际电信联盟(ITU)在 1994 年颁布的数据结构基本描述 X.680(Specification of basic notation)、信息对象描述 X.681(Information object specification)、约束描述 X.682(Constraint specification)和规范的参数化 X.683(Parameters of ASN.1 specification)等系列标准代替了 X.208;X.209 也被 ITU 在 1994 年的 X.690~ X.696 所代替。X.680 系列和 X.690 系列又分别于 1997 年、2002 年和 2015 年更新了版本。ITU-T 的 X.680 系列和 X.690 系列分别与 ISO 的 8824 系列和 8825 系列相对应;我国从 1996 年开始也陆续颁布了相应的国家标准。欲进一步了解我国关于 ASN.1 的相关标准索引的请进入。
ASN.1 这种表示法提供了一定数量的预定义的基本类型,比如:
- INTEGER(整数)
- BOOLEAN(布尔)
- IA5String(字符串)
- BIT STRING(比特字符串)
- 等等……
并且还可以定义构造类型,比如:
- SEQUENCE(序列) # 其实就是 map
- SEQUENCE OF(顺序) # 其实就是列表
- 这就好比 yaml 中使用
-符号表示列表,ASN.1 用一串字母表示。
- 这就好比 yaml 中使用
- CHOICE(选择)
- 等等……
ASN.1 是 ITU-T 第 17 研究组和 ISO/IEC 中国际电信联盟电信标准化部门(ITU-T)的联合标准,最初于 1984 年定义为 CCITT X.409:1984 的一部分。1988 年,由于广泛适用,ASN.1 移至其自己的标准 X.208。_X.680 _系列涵盖了经过实质性修订的 1995 年版本。X.680 系列建议的最新版本是 2015 年发布的 5.0 版。
ASN.1 已经融入了人们生活的方方面面,当我们使用手机、从 ATM 取款、管理网络、在线购物、接受包裹、发送邮件、通过互联网打电话看电影听音乐,都在使用 ASN.1。每天,从 RFID、VoIP、生物识别和许多其他新兴领域,ASN.1 被选为基础技术。
Encodings Rules(编码规则)
从计算机的角度看 ASN.1 是 abstract(抽象的),计算机无法理解字符串,所以需要一种 Encodings Rules(编码规则),将 ASN.1 格式的内容表示为 bits 和 bytes。这些编码规则规范了如何将 ASN.1 数据结构表示为 Bytes。ASN.1 与 Encoding Rules 的关系有点像 unicode 与 utf-8 的关系。
备注:ASN.1 与 PEM 是完全没有关系的。但是 ASN.1 编码后是二进制的数据,这不利于复制黏贴,所以,通常都需要将二进制数据再转换为便于复制黏贴的字符串,所以通常使用 DER 编码的 ASN.1 数据还会再通过 PEM 标准进行编码。 为什么要套娃?很奇怪,莫名其妙~~~~从 文本——二进制——文本,不累么。。。。。o(╯□╰)o
ITU X.690 标准
ITU-T X.690 标准,指定了几种 ASN.1 编码格式:
- Basic Encoding Rules(基本编码规则,简称 BER)
- Canonical Encoding Rules(规范编码规则,简称 CER)
- Distinguished Encoding Rules(杰出编码规则,简称 DER)
DER 编码规则
Distinguished Encoding Rules(专用编码规则,简称 DER) 是 BER 的一种受限制变体,用于为 ASN.1 所描述的数据结构生成明确的传输语法。像 CER 一样,DER 编码是有效的 BER 编码。 DER 与 BER 相同,只是删除了一个发送者的所有选项。
用白话说: DER 是一种以二进制形式编码 ASN.1 语法的方法
DER,是对 ASN.1 这种语言进行编码的一种规则,也是最常用的一种。所谓对某种语言编码,就是类似编译器的效果。所以也可以称为 ASN.1 的 DER 规则。
编码示例
这是定义虚构Foo协议的消息(数据结构)的示例 ASN.1 模块:
FooProtocol 定义 ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER,
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER,
answer BOOLEAN
}
END
这可能是 Foo 协议的创建者发布的规范。ASN.1 中没有定义会话流、交易交换和状态,而是留给协议的其他符号和文本描述。 假设一条消息符合 Foo 协议并且将被发送到接收方,这个特定的消息(协议数据单元(PDU))是:
myQuestion FooQuestion ::= {
trackingNumber 5,
question “有人在吗?”
}
ASN.1 支持对值和大小以及可扩展性的约束。上述规格可改为
FooProtocol DEFINITIONS ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER(0..199),
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER(10..20),
answer BOOLEAN
}
FooHistory ::= SEQUENCE {
questions SEQUENCE (SIZE(0..10)) OF FooQuestion,
回答 SEQUENCE(SIZE(1..10)) OF FooAnswer,
anArray SEQUENCE(SIZE(100)) OF INTEGER(0..1000),
...
}
END
此更改将 trackingNumbers 限制为介于 0 和 199 之间的值,并将 questionNumbers 限制为介于 10 和 20 之间的值。问题数组的大小可以在 0 到 10 个元素之间,答案数组的大小可以在 1 到 10 个元素之间。anArray 字段是一个固定长度的 100 个元素的整数数组,必须在 0 到 1000 的范围内。“…”扩展性标记意味着 FooHistory 消息规范在规范的未来版本中可能会有其他字段;兼容一个版本的系统应该能够接收和传输来自更高版本的事务,但只能处理早期版本中指定的字段。好的 ASN.1 编译器将生成(在 C、C++、Java 等中)源代码,这些代码将自动检查事务是否在这些约束范围内。不应从应用程序接受或向应用程序提交违反约束的事务。这一层的约束管理显着简化了协议规范,因为应用程序将免受约束违反,降低风险和成本。 为了通过网络发送 myQuestion 消息,使用其中一个编码规则将消息序列化(编码)为一系列字节。Foo 协议规范应该明确命名要使用的一组编码规则,以便 Foo 协议的用户知道他们应该使用和期望使用哪一个。
在 DER 中编码的示例[编辑]
下面是上面显示的 FooQuestion 以DER 格式编码的数据结构(所有数字均为十六进制): 30 13 02 01 05 16 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f DER 是类型-长度-值编码,所以上面的序列可以解释,参考标准的 SEQUENCE、INTEGER 和 IA5String 类型,如下: 30 — 指示 SEQUENCE 的类型标记 13 — 以八位字节为单位的值的长度 02 — 指示整数的类型标记 01 — 以八位字节为单位的跟随值的长度 05 — 值 (5) 16 — 指示IA5String 的 类型标记 (IA5 表示完整的 7 位 ISO 646 集,包括变体, 但通常是 US-ASCII) 0e — 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f — 值(“有人吗?”)
以 XER 编码的示例[编辑]
或者,可以使用XML 编码规则(XER) 对相同的 ASN.1 数据结构进行编码,以实现更高的“在线”可读性。然后它将显示为以下 108 个八位字节,(空格数包括用于缩进的空格):
**
以 PER 编码的示例(未对齐)[编辑]
或者,如果采用打包编码规则,将产生以下 122 位(16 个八位字节等于 128 位,但这里只有 122 位携带信息,最后 6 位只是填充): 01 05 0e 83 bb ce 2d f9 3c a0 e9 a3 2f 2c af c0 在这种格式中,所需元素的类型标记未编码,因此在不知道用于编码的预期模式的情况下无法对其进行解析。此外,IA5String 值的字节使用 7 位单元而不是 8 位单元进行打包,因为编码器知道编码 IA5String 字节值只需要 7 位。然而,长度字节仍然在此处编码,即使对于第一个整数标记 01(但 PER 打包器也可以省略它,如果它知道允许的值范围适合 8 位,它甚至可以用更少的值压缩单个值字节 05 比 8 位,如果它知道允许的值只能适合更小的范围)。 编码的 PER 中的最后 6 位在最后一个字节 c0 的 6 个最低有效位中用空位填充:如果此序列作为较长未对齐的一部分插入,则这些额外位可能不会被传输或用于编码其他内容 PER 序列。 这意味着未对齐的 PER 数据本质上是一个有序的位流,而不是像对齐的 PER 那样的有序字节流,并且在普通处理器上通过软件解码会更复杂一些,因为它需要额外的上下文位 -移位和掩码,而不是直接字节寻址(但对于现代处理器和最小可寻址单元大于 1 个八位字节的内存/存储单元,同样的评论也是正确的)。然而,现代处理器和信号处理器包括对比特流的快速内部解码的硬件支持,自动处理跨越可寻址存储单元边界的计算单元(这是在数据编解码器中进行有效处理以进行压缩/解压缩或某些加密/解密算法)。 如果需要在八位字节边界上对齐,对齐的 PER 编码器将产生: 01 05 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f (在这种情况下,每个八位字节在其未使用的最高有效位上单独填充空位)。
以一个证书分析 ASN.1 语法
以下是一个PEM格式的证书。
-----BEGIN CERTIFICATE-----
MIIFwTCCA6mgAwIBAgIUNQk34EiXUjqgxnfhOZtv6zxIiekwDQYJKoZIhvcNAQEN
BQAwcDELMAkGA1UEBhMCQ04xEDAOBgNVBAgMB0JlaWppbmcxEDAOBgNVBAcMB0Jl
aWppbmcxEDAOBgNVBAoMB2V4YW1wbGUxETAPBgNVBAsMCFBlcnNvbmFsMRgwFgYD
VQQDDA9yZXBvLmVubmlvdC5uZXQwHhcNMjAwODExMDMwMzE0WhcNMzAwODA5MDMw
MzE0WjBwMQswCQYDVQQGEwJDTjEQMA4GA1UECAwHQmVpamluZzEQMA4GA1UEBwwH
QmVpamluZzEQMA4GA1UECgwHZXhhbXBsZTERMA8GA1UECwwIUGVyc29uYWwxGDAW
BgNVBAMMD3JlcG8uZW5uaW90Lm5ldDCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCC
AgoCggIBAN6xDFkixeboRBjaVLi1/IjCfHvGS2xGihWrx2dN9jXIZWQqU2Lw8rLy
yzrnzSEJDRcUFGaXpRagHTYJPhcr31Sa4OkCsoorwElagcOOPQXAc1A87vBk1+r/
3eQu+IPGjr+3DU/yqNNuaq0CZgDDww9ttbyTb8JxZweXdAMjK0D7LiNCkpvwM1l6
ylVl9o5+ACA34qb81IyVAsGFSHP/ukcFIaC79Zf/7p3Tjm4uRkAdtQYJGwA0Oafk
HbPaPLOHPJdi+3+a/OmmBJamxyWXF9pJ/BRrxFrqtssnAhIyPsNqKsPDCknJOzwS
6vdTVsuMkLMUbc0OK1dSIulXxZaea+jXcZMYWUA4ZDNdo1SrMg3Vvj/CrLWgm7b0
T1Wb8tXsr2NUNoacMzDgN41Kz7Ht57LQURaFf9rzjqACHVYfj/Ad8/PmgA6V3Dc3
gvMvqOoyp2iic1xQ2GcIItHvqD4YwBSdtyxJc1N5llNBF7A6+JWVc0kJpOQCDKVb
U+0Py6ugnbb/pQ89/4zXXWyuTQO0BGULoHCo0++eF+pLcW6LstQNSUYxYRr4tmLr
sbUJFPoFcHXdQ9F8I2rBXdKCePHDBPQ2HexhANUWnRQdjtnYG9UQRQaDVKiCXUMj
9f6ixjN9DAz+SqndPksE0Ux0cgfkTEfi9N+5c7rCxzZYgH8UlFiDAgMBAAGjUzBR
MB0GA1UdDgQWBBRaOW9HUg7eACHGDuPMcc/k7nPmbjAfBgNVHSMEGDAWgBRaOW9H
Ug7eACHGDuPMcc/k7nPmbjAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUA
A4ICAQCu1kx2rnRp9oiPw3Y2WuJ2hnzkMTUGPv4rpX0hgVSLNAEiDEvujz/pnHaJ
83+JZuMHebAQnWHXVaUdmzn7Yw9WsZoXu15st0WMOAC8cUZ4uD0t1osPJTSuc3hA
F0ZG3tHzuJBpX4T6pVrZ3jJvuY5vGJGCMwRdS4V7e6wQmLjzqf3oq05y9JlvKBYX
JdU69BynZ1vEtUuC91WJTTvlqLtbAS6LTSmnSYWscNpP4KOTXNfdf8HlKFRKGR2e
cVyAXu9bA89HeEeG8ztceyD2GO+S7xBNuZRV11Oi2xO59rJJAzzrIO1W8oda5lac
JVRI+n8w+hLG+bbq+24s9tVB0MBZj3/honpYRLOYMAT507YlOvDPjreudYHWJSLG
cTjRH0dtIgqbi8uTH3iJ2yWTq92OfGSSERofVdSOPrlzH5GpkpeIoRcYlP1KLnIy
wxlI4E7W50PX5rMKMIp4/p6ALgA7psuC7ZTzk3f7R/tmHBSNb5JiSbp7MjI+iVRE
zZX73VW1nLf4YaSS+MYNudAQl0ZoUvK3f0QEj4NwzRjDkdsUKI+X7Q2p03foBMCU
4ijSDMvjyn3JEvT878Fxh7KB4IbZKh3kj9RetGaGEljjgv/Pg3h2gu+GNPgk30xJ
TfK5QkRaYenm9aWKpHHf4hpUQlMKawxdS1k+3gVGwWu8YM/a0A==
-----END CERTIFICATE-----
对这个证书进行解析的方法是用一个在线的工具 http://lapo.it/asn1js/。
可以把上面 base64 编码的证书复制到网站解码之后,可以看到类似如下的结果。
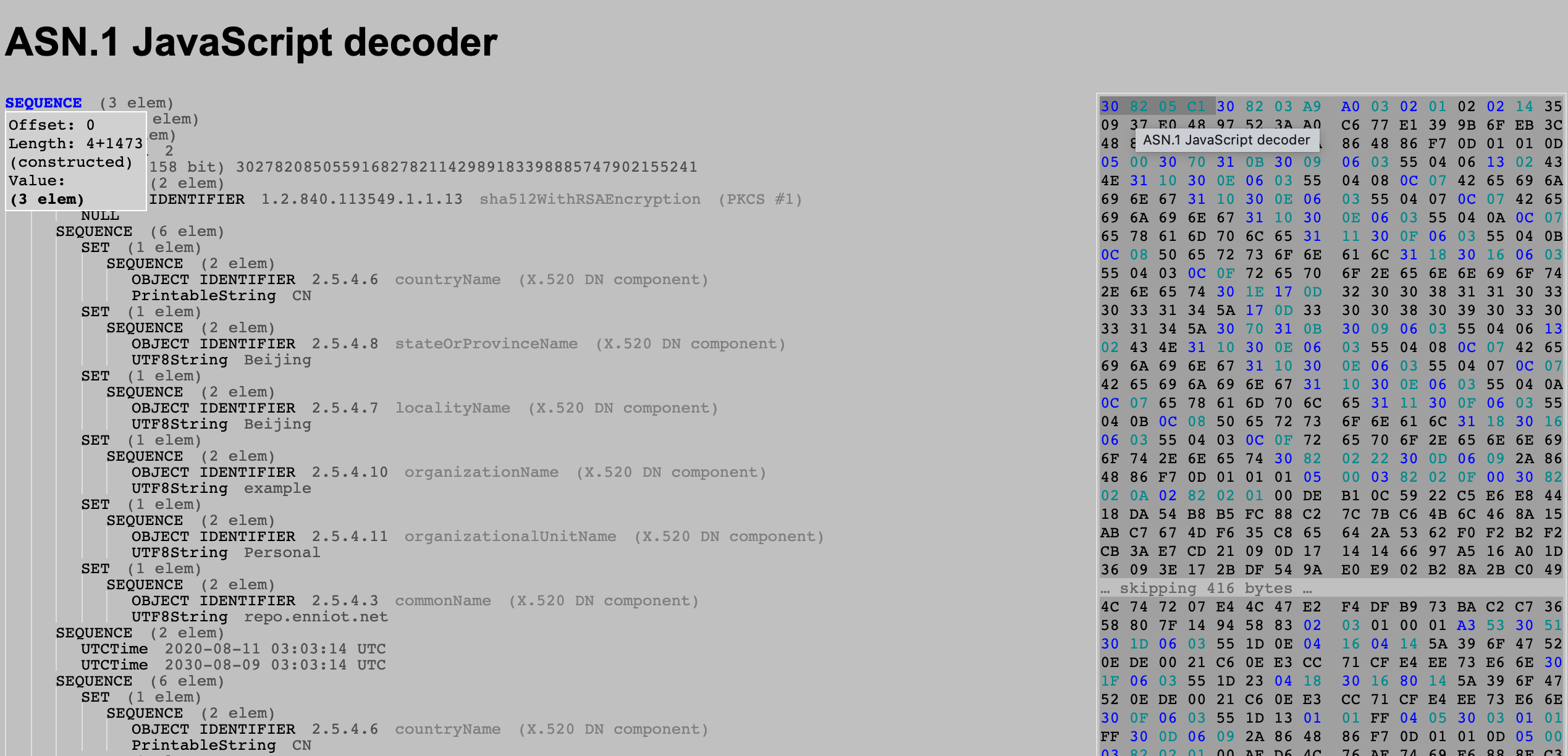 ASN.1 的编码基本上遵循的是
ASN.1 的编码基本上遵循的是type+length+value的方式。
ASN.1 的数据 tag 大概有以下几种,
| type | tagNumber |
|---|---|
| Boolean | 0x01 |
| Integer | 0x02 |
| BitString | 0x03 |
| OctetString | 0x04 |
| Null | 0x05 |
| ObjectIdentifier | 0x06 |
| Enumerated | 0x0a |
| UTF8String | 0x0c |
| Sequence | 0x10 |
| Set | 0x11 |
| PrintableString | 0x13 |
| IA5String | 0x16 |
| UTCTime | 0x17 |
| UnicodeString | 0x1e |
那么具体看一下以上 ca 证书的前四个字节是什么含义。
30 82 05 C1
- 首先看是什么 type。第一个字节
0x30描述了 type 信息。tagClass = 0x30 » 6 = 0 ,表示universal isConstructed = 0x30 & 0x20 = True,对于sequence基本都是 true,tagNumber = 0x30 & 0x1F = 0x10,因此对应的Sequence - 接下来计算长度。 第二个字节为
0x82, 分两种情况,判断表达式,byte & 0x7F == byte如果为 true 就是小于 127。否则就是大于 127。
- 长度是小于 127(short form) 那么该该字节就是 length,之后就是 value 的内容。
- 长度大于 127(long form), byte & 0x7F 表示 length 的编码长度。
对于以上的例子,0x82是 long form 因为
( 0x82 == (0x82 & 0x7F) = False
那么表示长度的字节数量是
0x82 & 0x7F = 0x2
因此’0x82’之后的两个字节’0x05’和’0xC1’组成长度。
0x05C1 = 1473
两个字节表示 value 的长度 1473。
因此,
30 82 05 C1
这个头四个字节的含义是,这个是Sequence类型, 长度是 1473,这四节之后的 1473 个字节就是Sequence类型的值。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.