Function
概述
参考:
在计算机编程中,比 Function(函数) 更官方(更早期)的称呼应该是 Subroutine(子程序) 是执行特定任务的程序指令序列,打包为一个单元。然后,该单元可用于应执行特定任务的程序中。
子程序可以在程序中定义,也可以在可以被许多程序使用的库中单独定义。在不同的编程语言中,子例程可以称为 Routine(例程)、Subprogram(子程序)、Function(函数)、Method(方法) 或 Procedure(过程)。从技术上讲,这些术语都有不同的定义。有时会使用通用的总称 Callable Unit(可调用单元)。
Function call(函数调用)
Parameter(参数)
在计算机编程中,Parameter(参数) 是函数中使用的一种特殊变量,用于在引用函数时,提供给函数的输入数据。
- actual parameter(实际参数,简称 实参) # 一般用 arguments 表示,在调用函数时使用实参
- formal parameter(形式参数,简称 形参) # 一般用 parameter 表示,在定义函数时使用形参
如何将 Arguments 的值传递给子程序的 Parameters 是由编程语言的 Evaluation strategy(评估策略) 决定的。每次调用子程序时,都会评估本次调用的 Arguments,并将评估结果分配给相应的 Parameters。这种分配机制,称为 Argument passing(参数传递)。
例如:现在定义一个名为 add 的子程序:
def add(x, y){
return x + y
}
这里的 x 和 y 是 形式参数
如果要引用这个子程序:
add(2, 3)
这里的 2 和 3 是实际参数。
所以,就跟参数的名字一样,形式参数就是形式上的,没有一个具体的数据,而实际参数之所以称为实际,就是因为这些参数有具体的数据。
注意:根据评估策略的不同,所谓的实际参数和形式参数也是相对来说的,比如在很多时候,我们传递的实际参数还可以是 另一个 Function、Pointer(指针) 等等类型的数据。
Evaluation strategy(评估策略)
| Convention | Description | Common use |
|---|---|---|
| Call by value(值调用)值传递 | 将参数的值的副本传递给子程序。(子程序内修改它们不会影响原始参数) | Default in most Algol-like languages after Algol 60, such as Pascal, Delphi, Simula, CPL, PL/M, Modula, Oberon, Ada, and many others. C, C++, Java (References to objects and arrays are also passed by value) |
| Call by reference(引用调用)引用传递 | 将参数的引用地址传递给子程序(子程序内修改它们会影响原始参数) | Selectable in most Algol-like languages after Algol 60, such as Algol 68, Pascal, Delphi, Simula, CPL, PL/M, Modula, Oberon, Ada, and many others. C++, Fortran, PL/I |
| Call by result | Parameter value is copied back to argument on return from the subroutine | Ada OUT parameters |
| Call by value-result | Parameter value is copied back on entry to the subroutine and again on return | Algol, Swiftin-out parameters |
| Call by name | Like a macro – replace the parameters with the unevaluated argument expressions | Algol, Scala |
| Call by constant value | Like call by value except that the parameter is treated as a constant | PL/I NONASSIGNABLE parameters, Ada IN parameters |
Call by Reference(通过引用调用) 与 Call by Value(通过值调用)
- 通过值调用(Call by value) 意味着,在函数体内修改参数值,不会影响到函数外部。
- 通过引用调用(Call by reference) 意味着,传入函数的原始值的地址,因此在函数内部修改参数,将会影响到原始值。
函数调用时底层逻辑
有读者问题函数调用是如何实现的,今天就来聊聊这个比较简单的问题。
大家都应该打包过东西吧,搬家之类的,通常都是找几个箱子一股脑装进去,为了不让箱子占地方,你通常会把它们摞好,就像这样:

注意看上面的箱子,最先被打包好的箱子被摞在最下方,刚打包好的箱子总是放在最上方,这就形成了一种 first in last out 的结构,也就是我们所说的栈,stack,上面的这些箱子就形成了栈。
如果你懂得用箱子打包东西,你就能明白函数调用是怎么一回事。
原来,在程序运行时每个被调用的函数都有自己的一个箱子,假设这段代码是这样写的:
void D() {} void C() { D(); } void B() { C(); } void A() { B(); }
函数 A 调用函数 B、B 调用 C、C 调用 D,那么当函数 D 在运行时内存中就会有四个箱子,每个函数一个:
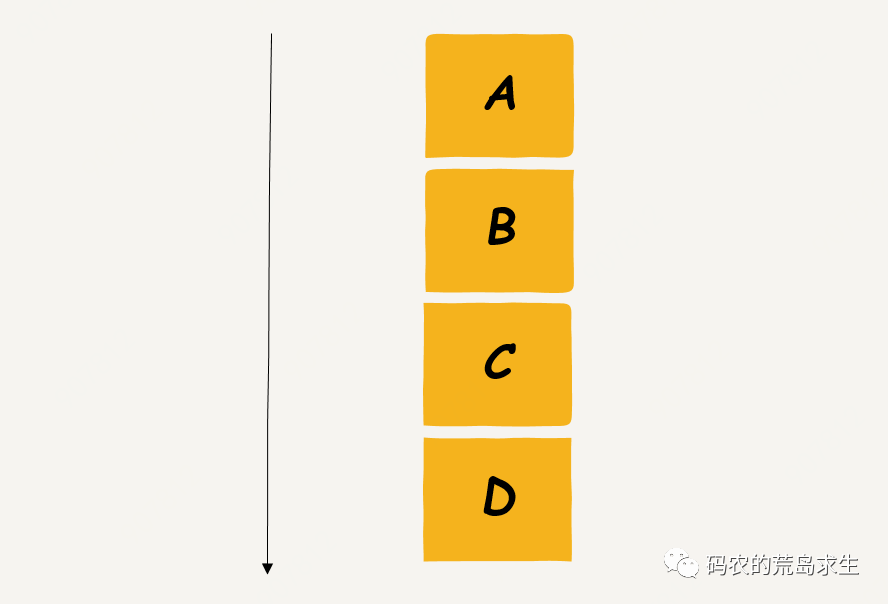
每个函数占据的这个箱子——也就是这块内存,就被称为栈帧,stack frame,只不过由于引力的作用,我们摞箱子时是从下往上增长,而出于内存布局的需要,函数调用时的栈是从高地址向低地址增长。
这些箱子中都装有什么呢?你在函数中定义的局部变量就装在这里,关于栈帧内容更详细的讲解你可以参考这里《函数调用是在内存中是什么样子》,这些不是本文的重点,这里更关心的是这些栈帧是怎样增长以及减少的。
仔细观察上面这张图,每个箱子最重要的信息有两个,你至少需要知道箱子的底部以及箱子的顶部在哪里!
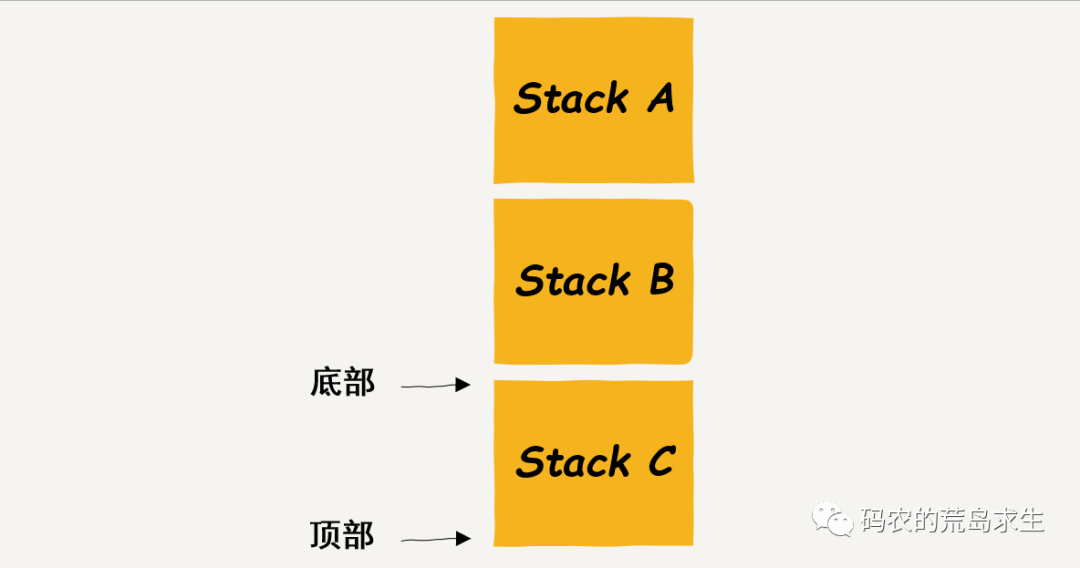
在计算机中,每个函数栈帧的“底部”和“顶部”的信息——也就是内存地址,分别存放在两个寄存器中:BasePointer(BP)寄存器以及 StackPointer(SP)寄存器,即我们熟悉的 rbp 以及 rsp,32 位下为 ebp 以及 esp,注意本文以 x86_64 为例。
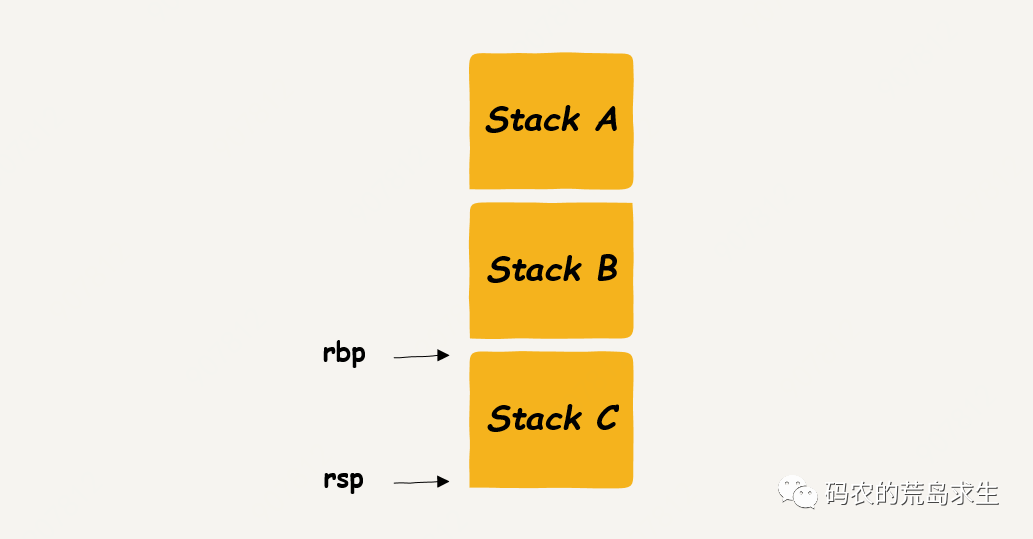
只要确定了 rbp 和 rsp 你就能得到一块栈区,在这块栈区上就可以进行函数调用:

读到这里肯定有的同学可能会问,CPU 中的寄存器不是有限的吗?从这里的讲解看每个栈帧都需要维护一个“栈顶”与“栈底”的信息,每个核心中的 rbp 以及 rsp 寄存器就一个,我们该怎样确保函数运行时相应栈帧使用的 rbp 以及 rsp 是正确的呢?
方法非常简单,调用函数时会创建新的栈帧,此时需要将原有 rbp 寄存器中的值保存在新的栈帧上,就像这样:
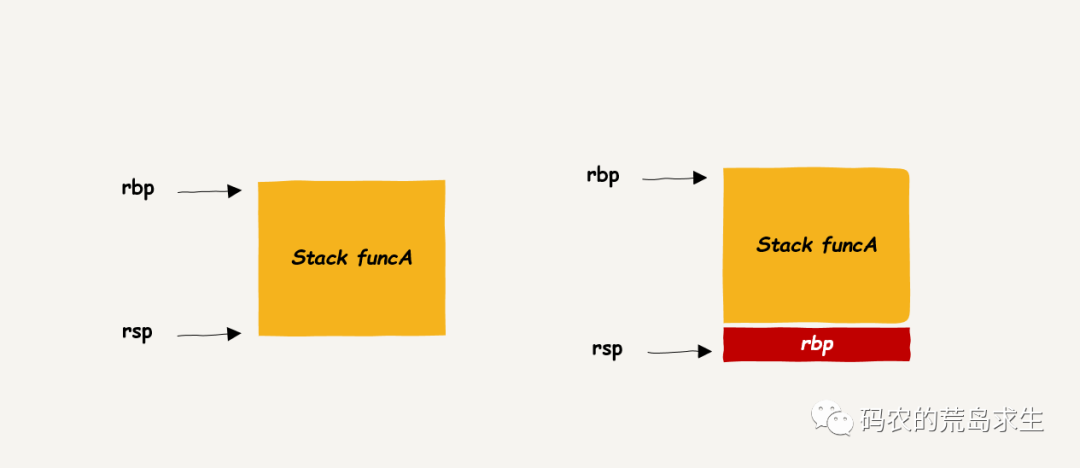
上图就是函数调用时第一件要完成的事情,把 rbp 的值 push 到栈上,rsp 下移,然后呢?然后也很简单,只需要把 rsp 指向的地址也赋值给 rbp 即可,这样就开启了一个新的栈帧:
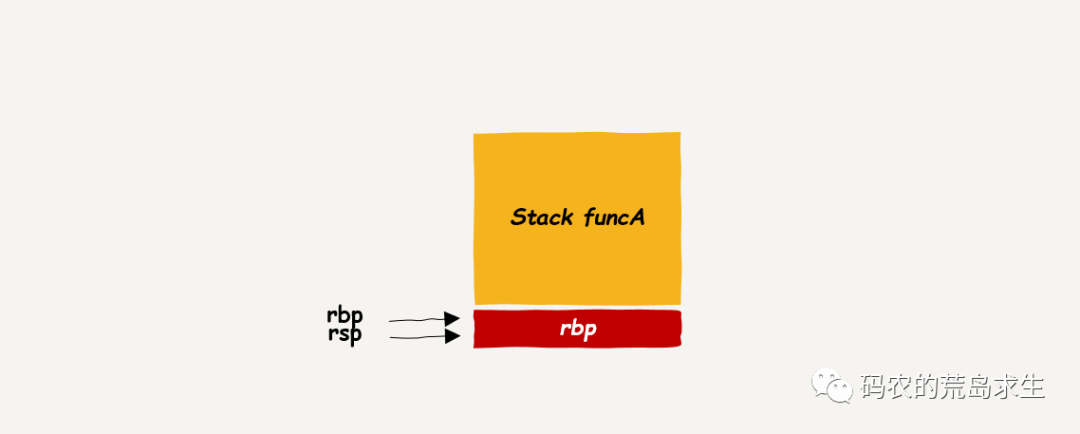
完成上述操作的有两条机器指令(gcc 编译器):
push %rbp mov %rsp,%rbp
如果你去看编译器为每个函数生成的机器指令,那么开头几乎都是这两条指令,现在你应该明白这两条指令的作用了吧。
这两条指令就把上一个栈帧的 rbp 的保存到了新的栈帧,由于此时 rsp 已经指向了新的栈帧栈顶,由于此时栈为空,因此栈顶和栈底的地址是一样的,可以直接把 rsp 赋给 rbp,这样一个全新的栈帧就创建出来了。
如果我们在被调函数内部创建一些局部变量:
void funcB() { int a = 1; int b = 2; int c = 3; … }
那么此时栈会进一步扩大,并把局部变量存放在该函数的栈帧中:
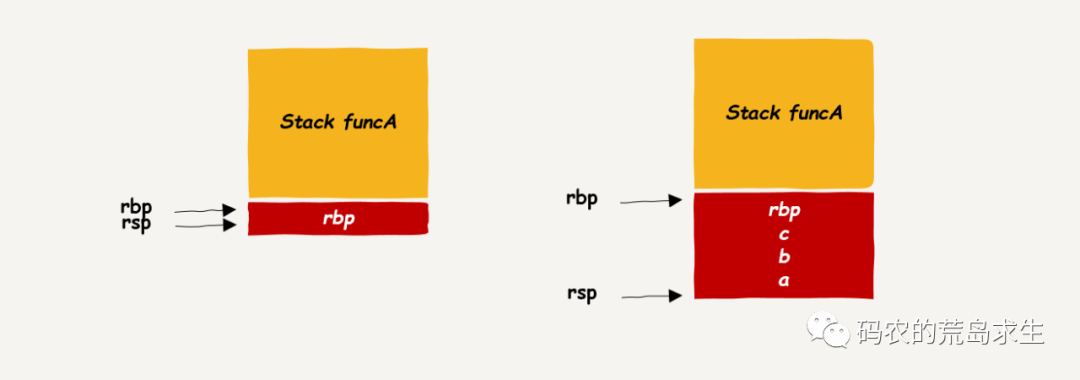
现在我们的栈可以随着函数调用而增长,可以看到,栈帧和你搬家时用的纸箱子还是不太一样的,函数栈帧不会一开始就大小固定好,而是随着指令的执行动态增加,也就是如果你往栈上 push 一些数据,栈帧就会相应的增大一点。
那么函数调用完成时该怎么办呢?这也非常简单,只需要一条机器指令:
leave
我们在上一篇《栈区分配内存快还是堆区分配内存快》中讲解了一部分,leave 指令的作用是将栈基址赋值给 rsp,这样栈指针指向上一个栈帧的栈顶,然后 pop 出 rbp,这样 rbp 就指向上一个栈帧的栈底:
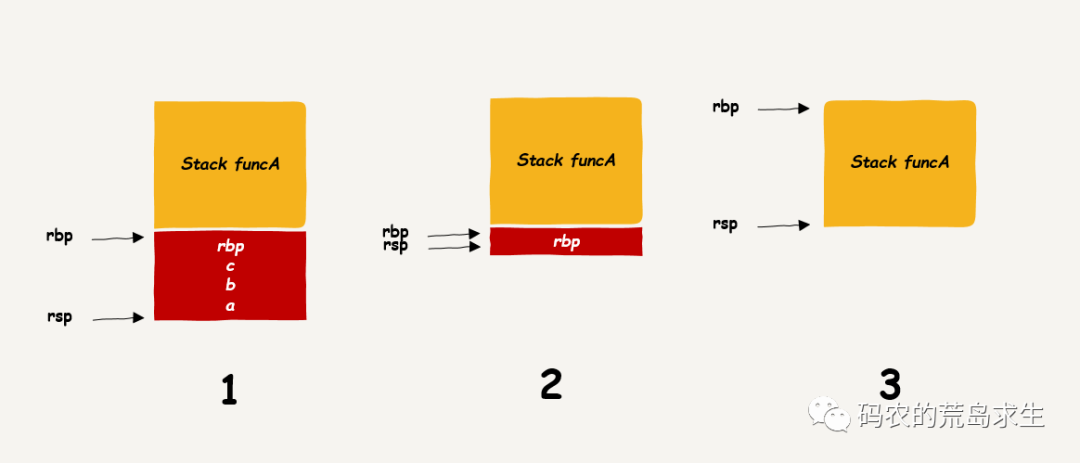
看到了吧,执行完 leave 指令后 rbp 以及 rsp 就指向了上一个栈帧,这就相当于栈帧的弹出,这样 stack 1 占用的内存就无效了,没有任何用处了,显然这就是我们常说的内存回收,因此简单的一条 leave 指令即可把栈区中的内存回收掉。
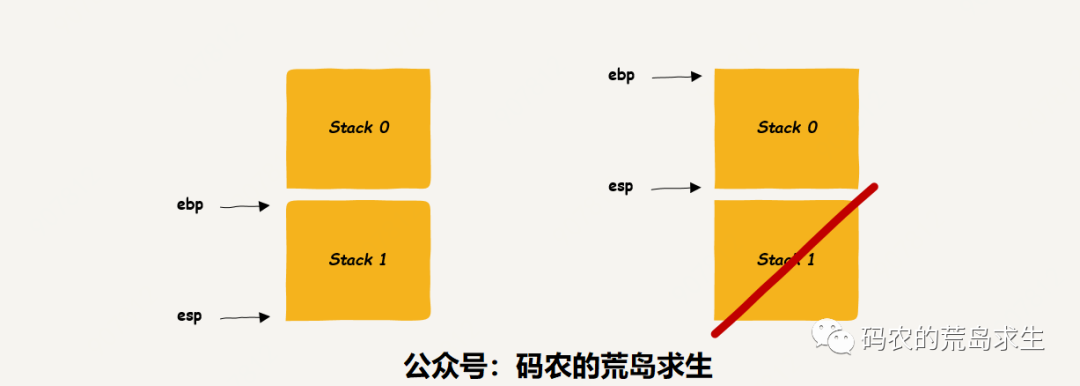
而在 x86 平台,leave 指令后往往跟上一条 ret 指令:
leave ret
我们已经了解了 leave 指令的作用,这条指令让 rbp 以及 rsp 指向上一个栈帧,然后呢?显然 CPU 应该从 funcA 调用函数 funcB 之后的一行代码处继续运行,那么这行代码的地址在哪里呢?显然就在 funcA 栈帧的栈顶:
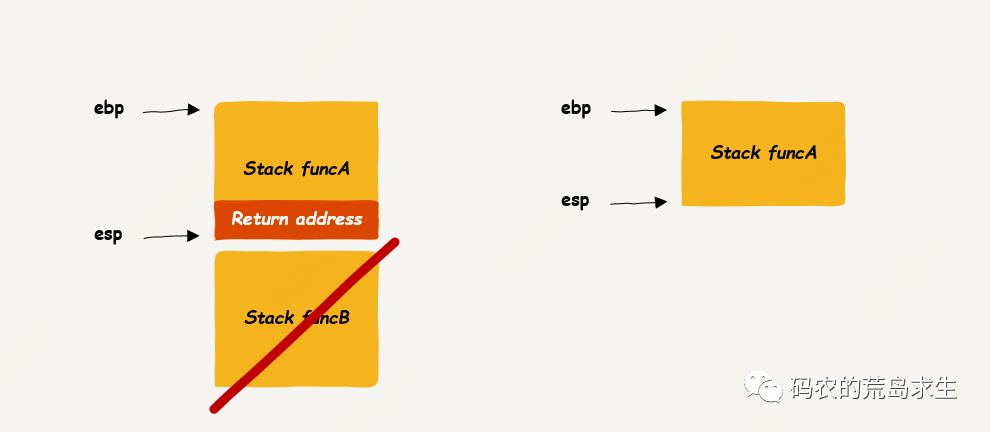
当 CPU 执行 call 指令时会把该函数的返回地址 push 到栈中,而 ret 指令的作用正是将栈顶弹出(pop)到 rip 寄存器,rip 寄存器告诉 CPU 接下来该从哪里执行机器指令,这个返回地址是 funcA 调用 funcB 时 push 到栈上的,这样当从函数 funcB()返回后我们就知道该从哪里继续执行机器指令了,这就是 ret 指令的作用,当然这里也是函数调用实现的基本原理。
关于栈帧更详细的讲解可以参考我写的这篇《函数调用在内存中是什么样子》。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.