ORM
概述
参考:
Object Relational Mapping(对象关系映射,简称 ORM) 是一种用于在关系数据库和面向对象变成语言之间转换数据的编程技术。解决了代码和关系型数据库之间的数据交互问题。这实际上创建了一个可以在编程语言中使用的虚拟对象数据库。
为什么需要 ORM
直接使用 database/sql 的痛点:
首先看看用 database/sql 如何查询数据库。
我们用 user 表来做例子,一般的工作流程是先做技术方案,其中排在比较前面的是数据库表的设计,大部分公司应该有严格的数据库权限控制,不会给线上程序使用比较危险的操作权限,比如创建删除数据库,表,删除数据等。
表结构如下:
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(100) NOT NULL COMMENT '名称',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`ctime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`mtime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
首先我们要写出和表结构对应的结构体 User,如果你足够勤奋和努力,相应的 json tag 和注释都可以写上,这个过程无聊且重复,因为在设计表结构的时候你已经写过一遍了。
type User struct {
Id int64 `json:"id"`
Name string `json:"name"`
Age int64
Ctime time.Time
Mtime time.Time
}
定义好结构体,我们写一个查询年龄在 20 以下且按照 id 字段顺序排序的前 20 名用户的 go 代码
func FindUsers(ctx context.Context) ([]*User, error) {
rows, err := db.QueryContext(ctx, "SELECT `id`,`name`,`age`,`ctime`,`mtime` FROM user WHERE `age`<? ORDER BY `id` LIMIT 20 ", 20)
if err != nil {
return nil, err
}
defer rows.Close()
result := []*User{}
for rows.Next() {
a := &User{}
if err := rows.Scan(&a.Id, &a.Name, &a.Age, &a.Ctime, &a.Mtime); err != nil {
return nil, err
}
result = append(result, a)
}
if rows.Err() != nil {
return nil, rows.Err()
}
return result, nil
}
当我们写少量这样的代码的时候我们可能还觉得轻松,但是当你业务工期排的很紧,并且要写大量的定制化查询的时候,这样的重复代码会越来越多。 上面的的代码我们发现有这么几个问题:
- SQL 语句是硬编码在程序里面的,当我需要增加查询条件的时候我需要另外再写一个方法,整个方法需要拷贝一份,很不灵活。
- 在查询表所有字段的情况下,第 2 行下面的代码都是一样重复的,不管 sql 语句后面的条件是怎么样的。
- 我们发现第 1 行 SQL 语句编写和 rows.Scan()那行,写的枯燥层度是和表字段的数量成正比的,如果一个表有 50 个字段或者 100 个字段,手写是非常乏味的。
- 在开发过程中 rows.Close() 和 rows.Err()忘记写是常见的错误。
我们总结出来用 database/sql 标准库开发的痛点:
- 开发效率很低
- 很显然写上面的那种代码是很耗费时间的,因为手误容易写错,无可避免要增加自测的时间。如果上面的结构体 User、 查询方法 FindUsers() 代码能够自动生成,那么那将会极大的提高开发效率并且减少 human error 的发生从而提高开发质量。
- 心智负担很重
- 如果一个开发人员把大量的时间花在这些代码上,那么他其实是在浪费自己的时间,不管在工作中还是在个人项目中,应该把重点花在架构设计,业务逻辑设计,困难点攻坚上面,去探索和开拓自己没有经验的领域,这块 Dao 层的代码最好在 10 分钟内完成。
ORM 实例教程
参考:
一、概述
面向对象编程和关系型数据库,都是目前最流行的技术,但是它们的模型是不一样的。
面向对象编程把所有实体看成对象(object),关系型数据库则是采用实体之间的关系(relation)连接数据。很早就有人提出,关系也可以用对象表达,这样的话,就能使用面向对象编程,来操作关系型数据库。
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,是"对象-关系映射"(Object/Relational Mapping) 的缩写。
ORM 把数据库映射成对象:
- 数据库的表(table) –> 类(class)
- 记录(record,行数据)–> 对象(object)
- 字段(field)–> 对象的属性(attribute)

举例来说,下面是一行 SQL 语句。
SELECT id, first_name, last_name, phone, birth_date, sex
FROM persons
WHERE id = 10
程序直接运行 SQL,操作数据库的写法如下。
res = db.execSql(sql)
name = res[0]["FIRST_NAME"]
改成 ORM 的写法如下。
p = Person.get(10)
name = p.first_name
一比较就可以发现,ORM 使用对象,封装了数据库操作,因此可以不碰 SQL 语言。开发者只使用面向对象编程,与数据对象直接交互,不用关心底层数据库。
总结起来,ORM 有下面这些优点。
- 数据模型都在一个地方定义,更容易更新和维护,也利于重用代码。
- ORM 有现成的工具,很多功能都可以自动完成,比如数据消毒、预处理、事务等等。
- 它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
- 基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
- 你不必编写性能不佳的 SQL。
但是,ORM 也有很突出的缺点。
- ORM 库不是轻量级工具,需要花很多精力学习和设置。
- 对于复杂的查询,ORM 要么是无法表达,要么是性能不如原生的 SQL。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。
二、命名规定
许多语言都有自己的 ORM 库,最典型、最规范的实现公认是 Ruby 语言的 Active Record。Active Record 对于对象和数据库表的映射,有一些命名限制。
(1)一个类对应一张表。类名是单数,且首字母大写;表名是复数,且全部是小写。比如,表books对应类Book。
(2)如果名字是不规则复数,则类名依照英语习惯命名,比如,表mice对应类Mouse,表people对应类Person。
(3)如果名字包含多个单词,那么类名使用首字母全部大写的骆驼拼写法,而表名使用下划线分隔的小写单词。比如,表book_clubs对应类BookClub,表line_items对应类LineItem。
(4)每个表都必须有一个主键字段,通常是叫做id的整数字段。外键字段名约定为单数的表名 + 下划线 + id,比如item_id表示该字段对应items表的id字段。
三、示例库
下面使用 OpenRecord 这个库,演示如何使用 ORM。
OpenRecord 是仿 Active Record 的,将其移植到了 JavaScript,而且实现得很轻量级,学习成本较低。我写了一个示例库,请将它克隆到本地。
git clone https://github.com/ruanyf/openrecord-demos.git
然后,安装依赖。
cd openrecord-demos npm install
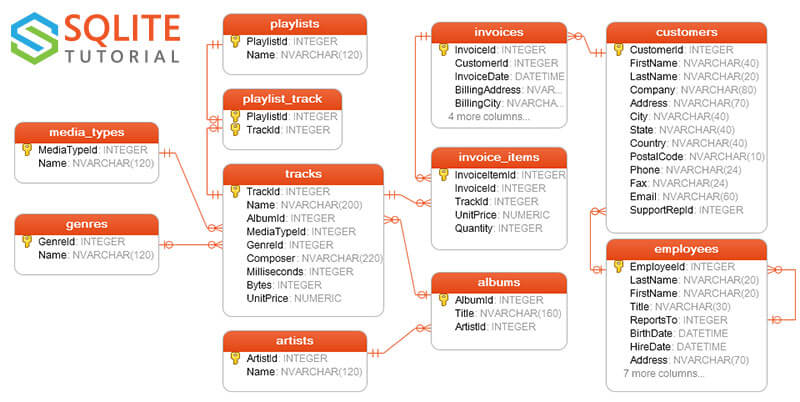
示例库里面的数据库,是从网上拷贝的 Sqlite 数据库。它的 Schema 图如下(PDF 大图下载)。
四、连接数据库
使用 ORM 的第一步,就是你必须告诉它,怎么连接数据库(完整代码看这里)。
// demo01.js
const Store = require('openrecord/store/sqlite3');
const store = new Store({
type: 'sqlite3',
file: './db/sample.db',
autoLoad: true,
});
await store.connect();
连接成功以后,就可以操作数据库了。
五、Model
5.1 创建 Model
连接数据库以后,下一步就要把数据库的表,转成一个类,叫做数据模型(Model)。下面就是一个最简单的 Model(完整代码看这里)。
// demo02.js
class Customer extends Store.BaseModel {
}
store.Model(Customer);
上面代码新建了一个Customer类,ORM(OpenRecord)会自动将它映射到customers表。使用这个类就很简单。
// demo02.js
const customer = await Customer.find(1);
console.log(customer.FirstName, customer.LastName);
上面代码中,查询数据使用的是 ORM 提供的find()方法,而不是直接操作 SQL。Customer.find(1)表示返回id为1的记录,该记录会自动转成对象,customer.FirstName属性就对应FirstName字段。
5.2 Model 的描述
Model 里面可以详细描述数据库表的定义,并且定义自己的方法(完整代码看这里)。
class Customer extends Store.BaseModel {
static definition(){
this.attribute('CustomerId', 'integer', { primary: true });
this.attribute('FirstName', 'string');
this.attribute('LastName', 'string');
this.validatesPresenceOf('FirstName', 'LastName');
}
getFullName(){
return this.FirstName + ' ' + this.LastName;
}
}
上面代码告诉 Model,CustomerId是主键,FirstName和LastName是字符串,并且不得为null,还定义了一个getFullName()方法。
实例对象可以直接调用getFullName()方法。
const customer = await Customer.find(1);
console.log(customer.getFullName());
六、CRUD 操作
数据库的基本操作有四种:create(新建)、read(读取)、update(更新)和delete(删除),简称 CRUD。
ORM 将这四类操作,都变成了对象的方法。
6.1 查询
前面已经说过,find()方法用于根据主键,获取单条记录(完整代码看这里)或多条记录(完整代码看这里)。
Customer.find(1)
Customer.find([1, 2, 3])
where()方法用于指定查询条件(完整代码看这里)。
Customer.where({Company: 'Apple Inc.'}).first()
如果直接读取类,将返回所有记录。
const customers = await Customer;
但是,通常不需要返回所有记录,而是使用limit(limit[, offset])方法指定返回记录的位置和数量(完整代码看这里)。
const customers = await Customer.limit(5, 10);)
上面的代码制定从第10条记录开始,返回5条记录。
6.2 新建记录
create()方法用于新建记录(完整代码看这里)。
Customer.create({
Email: '[president@whitehouse.gov](mailto:president@whitehouse.gov)',
FirstName: 'Donald',
LastName: 'Trump',
Address: 'Whitehouse, Washington'
})
6.3 更新记录
update()方法用于更新记录(完整代码看这里)。
const customer = await Customer.find(60);
await customer.update({
Address: 'Whitehouse'
});
6.4 删除记录
destroy()方法用于删除记录(完整代码看这里)。
const customer = await Customer.find(60);
await customer.destroy();
七、关系
7.1 关系类型
表与表之间的关系(relation),分成三种。
- 一对一(one-to-one):一种对象与另一种对象是一一对应关系,比如一个学生只能在一个班级。
- 一对多(one-to-many): 一种对象可以属于另一种对象的多个实例,比如一张唱片包含多首歌。
- 多对多(many-to-many):两种对象彼此都是"一对多"关系,比如一张唱片包含多首歌,同时一首歌可以属于多张唱片。
7.2 一对一关系
设置"一对一关系",需要设置两个 Model。举例来说,假定顾客(Customer)和发票(Invoice)是一对一关系,一个顾客对应一张发票,那么需要设置Customer和Invoice这两个 Model。
Customer内部使用this.hasOne()方法,指定每个实例对应另一个 Model 的一个实例。
class Customer extends Store.BaseModel {
static definition(){
this.hasOne('invoices', {model: 'Invoice', from: 'CustomerId', to: 'CustomerId'});
}
}
上面代码中,this.hasOne(name, option)的第一个参数是该关系的名称,可以随便起,只要引用的时候保持一致就可以了。第二个参数是关系的配置,这里只用了三个属性。
- model:对方的 Model 名
- from:当前 Model 对外连接的字段,一般是当前表的主键。
- to:对方 Model 对应的字段,一般是那个表的外键。上面代码是
Customer的CustomerId字段,对应Invoice的CustomerId字段。
然后,Invoice内部使用this.belongsTo()方法,回应Customer.hasOne()方法。
class Invoice extends Store.BaseModel {
static definition(){
this.belongsTo('customer', {model: 'Customer', from: 'CustomerId', to: 'CustomerId'});
}
}
接下来,查询的时候,要用include(name)方法,将对应的 Model 包括进来。
const invoice = await Invoice.find(1).include('customer');
const customer = await invoice.customer;
console.log(customer.getFullName());
上面代码中,Invoice.find(1).include('customer')表示Invoice的第一条记录要用customer关系,将Customer这个 Model 包括进来。也就是说,可以从invoice.customer属性上,读到对应的那一条 Customer 的记录。
7.3 一对多关系
上一小节假定 Customer 和 Invoice 是一对一关系,但是实际上,它们是一对多关系,因为一个顾客可以有多张发票。
一对多关系的处理,跟一对一关系很像,唯一的区别就是把this.hasOne()换成this.hasMany()方法。从名字上就能看出,这个方法指定了 Customer 的一条记录,对应多个 Invoice(完整代码看这里)。
class Customer extends Store.BaseModel {
static definition(){
this.hasMany('invoices', {model: 'Invoice', from: 'CustomerId', to: 'CustomerId'});
}
}
class Invoice extends Store.BaseModel {
static definition(){
this.belongsTo('customer', {model: 'Customer', from: 'CustomerId', to: 'CustomerId'});
}
}
上面代码中,除了this.hasMany()那一行,其他都跟上一小节完全一样。
7.4 多对多关系
通常来说,“多对多关系"需要有一张中间表,记录另外两张表之间的对应关系。比如,单曲Track和歌单Playlist之间,就是多对多关系:一首单曲可以包括在多个歌单,一个歌单可以包括多首单曲。数据库实现的时候,就需要一张playlist_track表来记录单曲和歌单的对应关系。
因此,定义 Model 就需要定义三个 Model(完整代码看这里)。
class Track extends Store.BaseModel{
static definition() {
this.hasMany('track_playlists', { model: 'PlaylistTrack', from: 'TrackId', to: 'TrackId'});
this.hasMany('playlists', { model: 'Playlist', through: 'track_playlists' });
}
}
class Playlist extends Store.BaseModel{
static definition(){
this.hasMany('playlist_tracks', { model: 'PlaylistTrack', from: 'PlaylistId', to: 'PlaylistId' });
this.hasMany('tracks', { model : 'Track', through: 'playlist_tracks' });
}
}
class PlaylistTrack extends Store.BaseModel{
static definition(){
this.tableName = 'playlist_track';
this.belongsTo('playlists', { model: 'Playlist', from: 'PlaylistId', to: 'PlaylistId'});
this.belongsTo('tracks', { model: 'Track', from: 'TrackId', to: 'TrackId'});
}
}
上面代码中,Track这个 Model 里面,通过this.hasMany('playlists')指定对应多个歌单。但不是直接关联,而是通过through属性,指定中间关系track_playlists进行关联。所以,Track 也要通过this.hasMany('track_playlists'),指定跟中间表的一对多关系。相应地,PlaylistTrack这个 Model 里面,要用两个this.belongsTo()方法,分别跟另外两个 Model 进行连接。
查询的时候,不用考虑中间关系,就好像中间表不存在一样。
const track = await Track.find(1).include('playlists');
const playlists = await track.playlists;
playlists.forEach(l => console.log(l.PlaylistId));
上面代码中,一首单曲对应多张歌单,所以track.playlists返回的是一个数组。
(完)
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.