Telemetry Library
概述
参考:
在 Telemetry Library 相关代码 telemetry_v2_init 进行初始化,之后即可使用。初始化之后会注册一些基本的命令,其他命令则取决于我们使用的 DPDK 都引用了哪些 Librairies,以及这些 Libraires 是否初始化了 telemetry
- 注册了几个基本的命令
/命令可以列出所有可用命令/info命令显示基本信息/help,COMMAND命令显示 COMMAND 的帮助信息
- 其他注册的命令则需要到各种 Libraries 的代码中查看。可以通过搜索 init_telemetry 关键字找到各种 Library 注册到 Telemetry 的命令,e.g. ethdev, mempool, etc.
简单示例如下:
~]# dpdk-telemetry.py
Connecting to /var/run/dpdk/rte/dpdk_telemetry.v2
{
"version": "DPDK 23.11.0",
"pid": 4054033,
"max_output_len": 16384
}
Connected to application: "usps"
--> /
{
"/": [
"/",
"/cnxk/ethdev/info",
"/eal/memseg_info",
"/ethdev/info",
"/ethdev/link_status",
"/ethdev/list",
"/eventdev/dev_dump",
......有很多,都省略了
]
}
--> /help,/ethdev/list
{
"/help": {
"/ethdev/list": "Returns list of available ethdev ports. Takes no parameters"
}
}
--> /ethdev/list
{
"/ethdev/list": [
0,
1
]
}
--> /help,/ethdev/stats
{
"/help": {
"/ethdev/stats": "Returns the common stats for a port. Parameters: int port_id"
}
}
--> /ethdev/stats,0
{
"/ethdev/stats": {
"ipackets": 0,
"opackets": 0,
"ibytes": 0,
"obytes": 0,
"imissed": 0,
"ierrors": 0,
"oerrors": 0,
"rx_nombuf": 0,
"q_ipackets": [
0,
......
--> /ethdev/xstats,0
{
"/ethdev/xstats": {
"rx_good_packets": 0,
"tx_good_packets": 0,
"rx_good_bytes": 0,
"tx_good_bytes": 0,
"rx_missed_errors": 0,
"rx_errors": 0,
"tx_errors": 0,
......
[!Tip] 在个人的学习项目中使用 Go 语言通过使用 unixpacket 与 Socket 文件建立连接后,也可以实现 dpdk-telemetry.py 的效果
从 DPDK 的 API 也可以查看一些,各种命令返回信息的含义

TODO: 还有没有其它官方文档来代替 API 文档或者源码中来了解各种命令返回的信息?
TODO: 根据 https://github.com/search?q=repo%3ADPDK%2Fdpdk%20init_telemetry&type=code 总结一下都有哪些库注册了 Telemetry
cnxk_mempool_init_telemetry
cnxk_ethdev_init_telemetry
ring_init_telemetry
librawdev_init_telemetry
dmadev_init_telemetry
security_init_telemetry
mempool_init_telemetry
eventdev_init_telemetry
cryptodev_init_telemetry
cnxk_ipsec_init_telemetry
ta_init_telemetry
ethdev_init_telemetry
rxa_init_telemetry
架构
/**
* @file
*
* RTE Telemetry.
*
* Telemetry 库提供了一种方法,可以通过套接字发送请求消息,以便从 DPDK 获取统计数据。
* DPDK 会发送 JSON 编码的遥测数据作为响应。
*/
/** 用于内部管理回调函数数据的非透明结构。 */
struct rte_tel_data;
ethdev
参考:
- /etcdev/stats # 端口(网卡)的普通统计信息
- /ethdev/xstats # 端口(网卡)的扩展统计信息
[!Tip] 与 Linux 网络设备 的
/sys/class/net/<iface>/statistics/统计目录类似,stats 与 xstats 这些数据统计生成的逻辑,取决于网卡的驱动程序,不同驱动程序可能逻辑细节上有些许不同。不过总体含义不会差距过大。
/ethdev/stats
参考:
在 eth_dev_handle_port_stats() 函数中可以看到如下定义
#define ADD_DICT_STAT(stats, s) rte_tel_data_add_dict_uint(d, #s, stats.s)
eth_dev_handle_port_stats(
const char *cmd __rte_unused,
const char *params,
struct rte_tel_data *d)
{
......
ADD_DICT_STAT(stats, ipackets);
ADD_DICT_STAT(stats, opackets);
ADD_DICT_STAT(stats, ibytes);
ADD_DICT_STAT(stats, obytes);
ADD_DICT_STAT(stats, imissed);
ADD_DICT_STAT(stats, ierrors);
ADD_DICT_STAT(stats, oerrors);
ADD_DICT_STAT(stats, rx_nombuf);
......
}
以 i, o 开头
- ipackets # 成功接收到的数据包总数
- opackets # 发送成功的数据包总数
- imissed # 由于没有可用缓冲区(i.e. Rx 队列已满)而被硬件丢弃的 Rx 数据包总数。
- Tips: 人话: 数据包进入缓冲区后,使用 DPDK 的上层应用程序处理不过来,导致缓冲区的队列一直是满的,所以就把无法进入队列的数据包扔掉了。
- …… etc.
/ethdev/xstats
参考:
通常以 rx, tx 开头
xstats 这些扩展信息的条目由两部分组成
- 基本的统计信息。i.e. /ethdev/stats 的结果。只不过会改名
- 网卡驱动程序相关的统计信息
下面从代码角度看一下逻辑
首先,检查命令执行的入口。函数为 eth_dev_handle_port_xstats
RTE_INIT(ethdev_init_telemetry)
{
rte_telemetry_register_cmd_arg(
"/ethdev/xstats",
eth_dev_telemetry_do, eth_dev_handle_port_xstats,
"Returns the extended stats for a port. Parameters: int port_id,hide_zero=true|false(Optional for indicates hide zero xstats)");
}
在 eth_dev_handle_port_xstats() 函数中,可以看到如下内容
eth_dev_handle_port_xstats(const char *cmd __rte_unused,
const char *params,
struct rte_tel_data *d)
{
const char *const valid_keys[] = { "hide_zero", NULL };
struct rte_eth_xstat *eth_xstats;
struct rte_eth_xstat_name *xstat_names;
struct rte_kvargs *kvlist;
bool hide_zero = false;
// 从命令行的参数里获取 port_id。解析 params,将解析结果赋值给 port_id
ret = eth_dev_parse_port_params(params, &port_id, &end_param, true);
// 获取 xstats 数量
num_xstats = rte_eth_xstats_get(port_id, NULL, 0);
// 获取 xstats 所有条目的名称
rte_eth_xstats_get_names(port_id, xstat_names, num_xstats);
// 获取 xstats 所有条目的值
rte_eth_xstats_get(port_id, eth_xstats, num_xstats);
// 构造 Telemetry 返回数据
rte_tel_data_start_dict(d);
for (i = 0; i < num_xstats; i++) {
rte_tel_data_add_dict_uint(d, xstat_names[i].name, eth_xstats[i].value);
}
}
通过统计信息的条目名称入手,看看都有哪些名字
从 rte_eth_xstats_get_names 函数中看到所有 xstats 条目的组成(基本统计 和 驱动相关统计)
int
rte_eth_xstats_get_names(uint16_t port_id,
struct rte_eth_xstat_name *xstats_names,
unsigned int size)
{
// 基本统计信息
cnt_used_entries = eth_basic_stats_get_names(dev, xstats_names);
// 特定于驱动程序的统计信息
cnt_driver_entries = dev->dev_ops->xstats_get_names(dev, xstats_names + cnt_used_entries, size - cnt_used_entries);
// 合并两种统计信息
cnt_used_entries += cnt_driver_entries;
return cnt_used_entries;
}
基本统计信息在 rte_eth_xstats_name_off 类型的数组 eth_dev_stats_strings[] 中
static const struct rte_eth_xstats_name_off eth_dev_stats_strings[] = {
{"rx_good_packets", offsetof(struct rte_eth_stats, ipackets)},
{"tx_good_packets", offsetof(struct rte_eth_stats, opackets)},
{"rx_good_bytes", offsetof(struct rte_eth_stats, ibytes)},
{"tx_good_bytes", offsetof(struct rte_eth_stats, obytes)},
{"rx_missed_errors", offsetof(struct rte_eth_stats, imissed)},
{"rx_errors", offsetof(struct rte_eth_stats, ierrors)},
{"tx_errors", offsetof(struct rte_eth_stats, oerrors)},
{"rx_mbuf_allocation_errors", offsetof(struct rte_eth_stats, rx_nombuf)},
};
驱动相关的统计信息来源,是 dev->dev_ops->xstats_get_names,这是结构体 eth_dev_ops 中的一个属性。追踪 xstats_get_names 可以看到,所有驱动代码中都有对其的引用
Tips: 为什么是
dev->dev_ops->xstats_get_names而不是dev->eth_dev_ops->xstats_get_names?因为在 ethdev_driver.h 文件中声明了const struct eth_dev_ops *dev_ops;
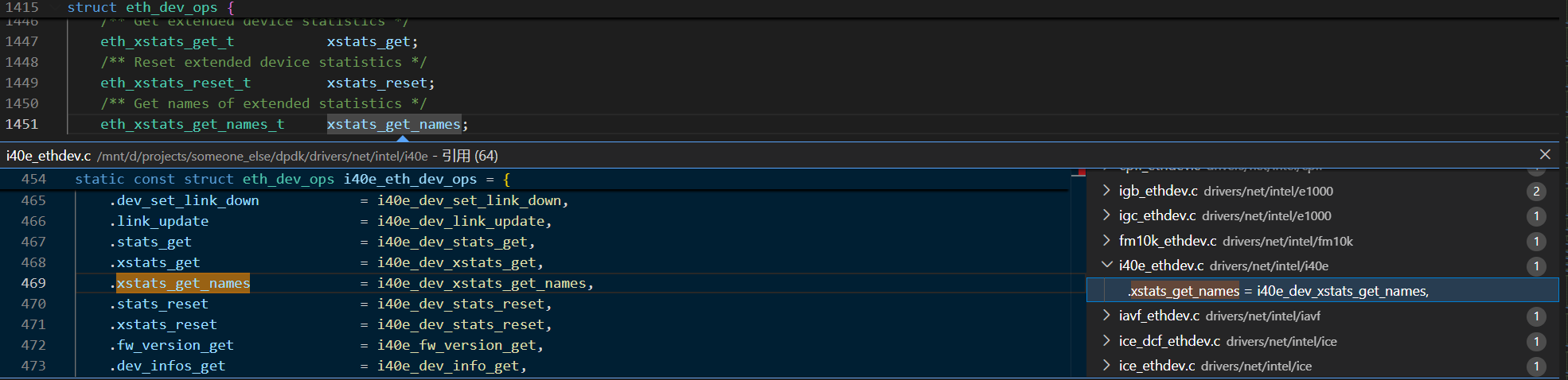
以 i40e 驱动为例,找到 i40e_dev_xstats_get_names 的具体实现逻辑
static int i40e_dev_xstats_get_names(__rte_unused struct rte_eth_dev *dev,
struct rte_eth_xstat_name *xstats_names,
__rte_unused unsigned limit)
{
/* Get stats from i40e_eth_stats struct */
for (i = 0; i < I40E_NB_ETH_XSTATS; i++) {
strlcpy(xstats_names[count].name,
rte_i40e_stats_strings[i].name);
}
/* Get stats from i40e_mbuf_stats struct */
for (i = 0; i < I40E_NB_MBUF_XSTATS; i++) {
strlcpy(xstats_names[count].name,
i40e_mbuf_strings[i].name);
}
/* Get individual stats from i40e_hw_port struct */
for (i = 0; i < I40E_NB_HW_PORT_XSTATS; i++) {
strlcpy(xstats_names[count].name,
rte_i40e_hw_port_strings[i].name);
}
for (i = 0; i < I40E_NB_RXQ_PRIO_XSTATS; i++) {
snprintf(xstats_names[count].name,
rte_i40e_rxq_prio_strings[i].name);
}
for (i = 0; i < I40E_NB_TXQ_PRIO_XSTATS; i++) {
snprintf(xstats_names[count].name,
rte_i40e_txq_prio_strings[i].name);
}
}
i40e 的 xstats 由如下几个 rte_i40e_xstats_name_off 类型的数组组成:
rte_i40e_stats_stringsi40e_mbuf_stringsrte_i40e_hw_port_stringsrte_i40e_rxq_prio_stringsrte_i40e_txq_prio_strings
以其中的 rte_i40e_stats_strings 为例(其他的数组同理):
struct rte_i40e_xstats_name_off {
char name[RTE_ETH_XSTATS_NAME_SIZE];
int offset;
};
// 数组中的元素是 rte_i40e_xstats_name_off 类型。
static const struct rte_i40e_xstats_name_off rte_i40e_stats_strings[] = {
{"rx_unicast_packets", offsetof(struct i40e_eth_stats, rx_unicast)},
{"rx_multicast_packets", offsetof(struct i40e_eth_stats, rx_multicast)},
{"rx_broadcast_packets", offsetof(struct i40e_eth_stats, rx_broadcast)},
{"rx_dropped_packets", offsetof(struct i40e_eth_stats, rx_discards)},
{"rx_unknown_protocol_packets", offsetof(struct i40e_eth_stats, rx_unknown_protocol)},
{"rx_size_error_packets", offsetof(struct i40e_hw_port_stats, rx_err1)},
{"tx_unicast_packets", offsetof(struct i40e_eth_stats, tx_unicast)},
{"tx_multicast_packets", offsetof(struct i40e_eth_stats, tx_multicast)},
{"tx_broadcast_packets", offsetof(struct i40e_eth_stats, tx_broadcast)},
{"tx_dropped_packets", offsetof(struct i40e_eth_stats, tx_discards)},
};
#define I40E_NB_ETH_XSTATS (sizeof(rte_i40e_stats_strings) / \
sizeof(rte_i40e_stats_strings[0]))
此时,算是找到了 i40e 驱动的所有可用的 xstats 数据。i.e. 那几个元素类型是 rte_i40e_xstats_name_off 的数组。数组中的每个元素都是一个 xstats 条目。
mempool
imissed by AI
DPDK 的 ethdev 中有个统计信息 imissed。怎么理解这个?
imissed 是 DPDK ethdev 统计信息中的一个重要字段,表示 由于接收队列满或其他硬件资源不足而被丢弃的数据包数量。
具体来说:
- 定义位置:在
rte_eth_stats结构体中,imissed表示因硬件接收资源不足导致的丢包 - 丢包原因:
- RX 队列(ring buffer)已满,新到的包无法入队
- 网卡的接收描述符用尽
- 硬件缓冲区不足
- 与其他丢包统计的区别:
imissed:硬件层面的丢包(包已到达网卡但无法接收)ierrors:接收错误(如 CRC 错误、对齐错误等)rx_nombuf:因 mbuf 不足导致的丢包(软件层面)
- 常见触发场景:
- 应用处理速度跟不上网卡接收速度
- 分配给 RX 队列的描述符数量太少
- CPU 核心被其他任务占用,来不及处理收包
如果看到 imissed 持续增长,通常需要:
- 增加 RX 描述符数量
- 优化应用处理逻辑
- 检查 CPU 亲和性设置
- 考虑使用多队列分流
不同网卡驱动对 imissed 的实现可能略有差异,但核心含义是硬件层面因资源不足导致的丢包。
这个 rx 队列是做什么用的?是网卡接收包的时候满了,还是程序接收包的时候满了?
这个 RX 队列是 网卡和应用程序之间共享的数据结构,用于传递接收到的数据包。理解它需要看完整的数据包接收流程:
数据包接收流程
- 数据包到达网卡
- 网卡硬件接收到物理层的数据包
- 网卡将数据包通过 DMA 写入内存中的 RX 描述符指向的缓冲区
- RX 队列(Ring Buffer)的作用
- 这是一个环形队列,由应用程序在初始化时创建
- 队列中每个描述符指向一个 mbuf(数据包缓冲区)
- 网卡通过 DMA 将数据包内容写入这些 mbuf
- 网卡写入 → 程序读取
- 网卡侧:不断将新到的包写入队列,移动写指针
- 程序侧:调用
rte_eth_rx_burst()从队列读取,移动读指针
imissed 发生的时机
imissed 是网卡写入时发现队列满了:
网卡接收包 → 尝试写入 RX 队列 → 发现队列满(所有描述符都被占用)→ imissed++
具体来说:
- 网卡已经将包 DMA 到内存了
- 但发现 RX 队列的描述符都被占用(应用还没来得及处理)
- 网卡无法将新包的描述符放入队列
- 只能丢弃这个包,
imissed计数增加
为什么会满?
RX 队列满的根本原因是 应用程序处理速度跟不上网卡接收速度:
- 应用调用
rte_eth_rx_burst()取包太慢 - 取出的包还没处理完(或处理太慢)
- 导致 RX 队列中的描述符无法被释放回来给网卡继续使用
所以虽然队列是在网卡写入时满的,但根源是程序处理不过来。
DMA 是什么?
DMA 是 Direct Memory Access(直接内存访问) 的缩写,是一种硬件机制,允许外设(如网卡、磁盘)直接访问系统内存,而不需要 CPU 参与数据搬运。
传统方式 vs DMA
传统方式(没有 DMA):
网卡 → CPU 读取 → CPU 写入内存
- CPU 必须参与每个字节的搬运
- CPU 被占用,无法做其他事情
- 效率低,尤其是大量数据时
DMA 方式:
网卡 ← 告诉地址 ← CPU
网卡 → 直接写入内存(CPU 可以做其他事)
网卡 → 完成后中断通知 CPU
- CPU 只需告诉网卡"把数据放到这个内存地址"
- 网卡自己完成数据传输
- CPU 被解放出来做其他计算
在 DPDK 中的应用
当网卡接收数据包时:
- 初始化阶段:
- 应用程序分配 mbuf(内存缓冲区)
- 将这些 mbuf 的物理地址填入 RX 描述符
- 告诉网卡:收到包就放到这些地址
- 收包阶段:
- 网卡收到数据包
- 通过 DMA 直接将包内容写入 mbuf 的内存地址
- 不需要 CPU 搬运数据
- 通知阶段:
- 网卡更新描述符状态
- 应用程序轮询(或中断)发现有新包
- 直接读取 mbuf 中的数据
DMA 的优势
- 高效:CPU 不参与数据搬运,减少 CPU 开销
- 快速:硬件直接操作内存,速度快
- 并行:CPU 可以在 DMA 传输时做其他计算
这就是为什么高性能网络处理(如 DPDK)严重依赖 DMA —— 它让数据传输几乎不消耗 CPU 资源。
如果 DPDK 是靠 DMA 取得优势的话,那 Linux 不用 DMA 用什么?
好问题!Linux 内核网络栈也用 DMA,这不是 DPDK 的独特优势。
DPDK 的性能优势来自其他方面,不是因为用了 DMA。让我说清楚两者的区别:
Linux 内核网络栈的流程
- 网卡通过 DMA 将数据写入内存
- 网卡触发硬件中断通知 CPU
- CPU 进入内核态处理中断
- 内核将数据包复制到 socket 缓冲区
- 应用程序通过 系统调用(如
recvfrom())从内核态复制到用户态 - 上下文切换:用户态 ↔ 内核态
DPDK 的流程
- 网卡通过 DMA 将数据写入内存(和 Linux 一样)
- 应用程序直接轮询内存中的描述符(无中断)
- 数据已经在用户态内存中,直接使用(零拷贝)
- 全程在用户态,无系统调用,无上下文切换
DPDK 的真正优势
- 用户态驱动:绕过内核,减少上下文切换
- 轮询模式(PMD):不用中断,CPU 专心收包
- 零拷贝:数据直接在用户态,无需内核到用户的拷贝
- 批处理:一次处理多个包,提高效率
- CPU 亲和性:绑核,避免缓存失效
- 无锁设计:每个核独立处理,减少竞争
简单对比
| 特性 | Linux 内核 | DPDK |
|---|---|---|
| DMA | ✓ 用 | ✓ 用 |
| 中断 | ✓ 用 | ✗ 轮询 |
| 内核态处理 | ✓ | ✗ |
| 数据拷贝 | 2次(DMA→内核→用户) | 1次(DMA→用户) |
| 上下文切换 | 频繁 | 无 |
所以 DMA 不是 DPDK 的优势,减少内核开销、零拷贝、轮询模式才是关键。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.