ClickHouse
概述
参考:
存算分离,查询性能过剩
https://clickhouse.com/docs/en/guides/sre/network-ports
| 端口号 | 描述 |
|---|---|
| 2181 | ZooKeeper default service port. Note: see 9181 for ClickHouse Keeper |
| 8123 | HTTP default port |
| 8443 | HTTP SSL/TLS default port |
| 9000 | 原生协议端口(也称为 ClickHouse TCP 协议)。由 ClickHouse 生态的应用程序和进程使用(e.g. 各种语言利用 SDK 编写的程序、clickhouse-client 等自带程序、etc.)。也用于分布式查询的内部服务器之间的通信。 |
| 9440 | 与 9000 的功能相同,但是带有 SSL/TLS |
| 9004 | MySQL emulation port |
| 9005 | PostgreSQL emulation port (also used for secure communication if SSL is enabled for ClickHouse). |
| 9009 | Inter-server communication port for low-level data access. Used for data exchange, replication, and inter-server communication. |
| 9010 | SSL/TLS for inter-server communications |
| 9011 | Native protocol PROXYv1 protocol port |
| 9019 | JDBC bridge |
| 9100 | gRPC port |
| 9181 | Recommended ClickHouse Keeper port |
| 9234 | Recommended ClickHouse Keeper Raft port (also used for secure communication if <secure>1</secure> enabled) |
| 9363 | 在 /metrics 路径下暴露 Prometheus 格式的 Metric 指标 |
| 9281 | Recommended Secure SSL ClickHouse Keeper port |
| 42000 | Graphite default port |
学习资料
B 站 - 蜂蜜柠檬水HLN,带你快速认识 ClickHouse 数据库 | 了解 OLTP 与 OLAP
Engine
Engine(引擎) 是 ClickHouse 实现数据处理功能的核心抽象。数据库 以及 表 都由各种各样的 Engine 实现
- Database Engine(数据库引擎)
- Table Engine(表引擎)
关联文件与配置
参考:
/etc/clickhouse-server/
- ./config.xml # ClickHouse Server 运行配置。
- ./config.d/ # 配置文件可以拆分到该目录,程序运行时会将该目录下的文件合并到 config.xml 主配置文件
- ./metrika.xml # 默认的 include_from 文件。该文件中的配置用来替换主配置文件 config.xml 中的配置。
- e.g. config.xml 中有
<remote_servers incl="clickhouse_remote_server"/>,那么 metrika.xml 中的<clickhouse_remote_servers>部分配置就会作为 config.xml 中的 remote_servers。
- e.g. config.xml 中有
- ./users.xml # e.g. 认证信息、etc. 相关配置
- ./users.d/ # 配置文件可以拆分到该目录,程序运行时会将该目录下的文件合并到 users.xml 主配置文件
ClickHouse 部署
https://clickhouse.com/docs/en/install
CLI
https://clickhouse.com/docs/en/operations/utilities
clickhouse-server
clickhouse-client
https://clickhouse.com/docs/integrations/sql-clients/cli
OPTIONS
https://clickhouse.com/docs/integrations/sql-clients/cli#command-line-options
连接选项
- -h, –host(STRING) # ClickHouse Server 的 IP
- –port(INT) # ClickHouse Server 的 PORT
- -u, –user(STRING) # 连接数据库所使用的用户名。
默认值: default - –possword(STRING) # 连接数据库的用户的密码
- -d, –database(STRING) # 连接的数据库名称。
默认值: default
查询选项
- -m, –multiline # 允许多行查询(按 Enter 键时不发送查询),仅当查询以分号结尾时才会发送查询。
- -q, –query(STRING) # 指定查询 SQL。
- 可以将 SQL 保存到文件中,使用
--query="$(cat query.sql)"这种方式执行查询;或者直接使用 –queries-file 选项。
- 可以将 SQL 保存到文件中,使用
- –queries-file(STRING) # 指定包含 SQL 的文件路径。可以多次使用,执行多个 SQL 文件。
格式化选项
- -f, –format(STRING) # 使用指定的格式输出结果。
默认值: TabSeparated- 所有可用的格式详见: 官方文档,输入和输出数据的格式。e.g. CSV, JSON, etc.
- –pager(COMMAND) # 将所有输出结果传递给 COMMAND。通常是 less 命令(e.g. 使用
less -S显示更宽的结果)或类似命令。
EXAMPLE
clickhouse-client -u default --password d1234567 -h 127.0.0.1 --port 9000 -d my_database --queries-file tmp/query.sql --format CSV > result.csv
ClickHouse 生态
参考:
Grafana 数据源插件 https://github.com/grafana/clickhouse-datasource 。详见 Grafana Plugins
- 在 https://github.com/grafana/clickhouse-datasource/tree/main/src/dashboards 有一些内置的利用 ClickHouse 本身的数据创建出来的 Grafana 仪表盘
- 官方文档,可观测性 - Grafana 有一些最佳实践和示例
https://github.com/clickvisual/clickvisual 一个基于 clickhouse 构建的轻量级日志分析和数据可视化 Web 平台。
https://github.com/metrico/promcasa 通过 ClickHouse 的 SQL,将查询结果转为 OpenMetrics 格式数据。
驱动与接口
https://clickhouse.com/docs/en/interfaces/overview
Cluster
参考:
基础概念
- Shard # 数据的分片。ClickHouse 始终至少有 1 个 Shard。用来横向(添加机器数量,而非提高机器硬件配置)扩展数据的储存与处理的能力。
- Replica # 每个分片的副本。用来保障数据的高可用。ClickHouse 始终至少有 1 个 Replica
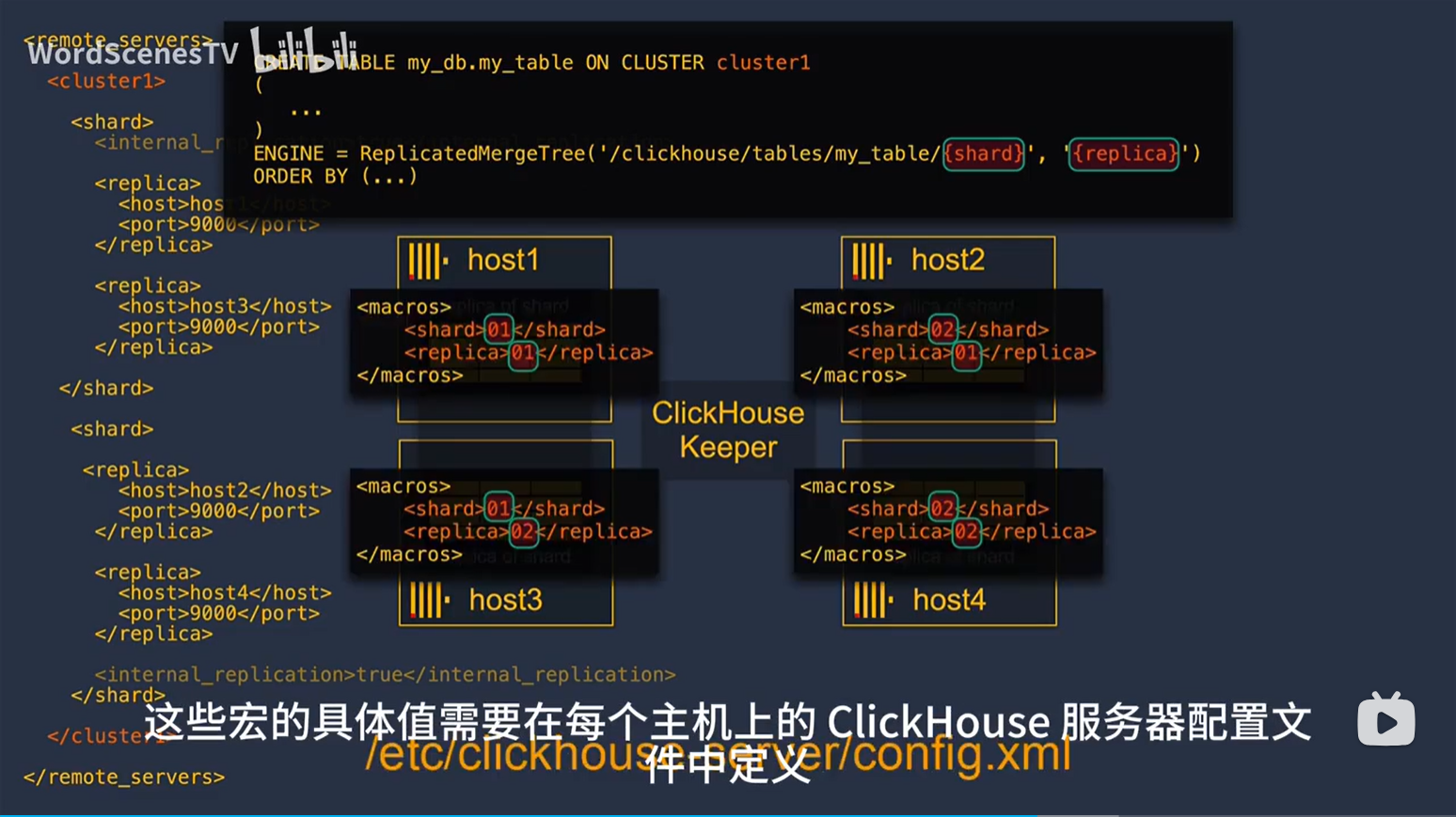
- Distributed coordination # 为 “数据复制” 和 “分布式 DDL” 提供分布式协调系统。可以使用 ClickHouseKeeper 或 Zookeeper 实现分布式协调系统。
- 数据复制 # 保证每个 Shard 的多个 Replica 总是能同步最新的数据
- 分布式 DDL # 看完后面的再回来理解。由于 ClickHouse 集群中的 Shard 各自独立,CREATE、DROP、ALERT、RENAME 操作仅影响执行该 SQL 时所在的节点。但是 ClickHouse 可以通过
ON CLUSTER子句,将操作同步给集群其他节点。这个就是分布式 DDL能力
[!Note] ClickHouse 中的 Replica 概念有点易混淆。ClickHouse 在没有复制任何数据的时候,也看作是有一个 Replica。不存在原始数据或备份数据的概念。如果数据只有一份,那就是只有一个 Replica 的数据,如果数据有两份(备份了一份),那就是有两个 Replica 的数据。
默认情况下,一个独立的 ClickHouse 保存了 1 Shard 数据,该 Shard 有 1 Replica。
为什么需要 ClickHouse 集群?
- 当我们存储或处理的数据超过了单台服务器的能力时,怎么办?
- 若想实现高可用,怎么办?
若想扩容,可以添加 N 台额外的服务器组成 ClickHouse 集群。将一个表中的数据分一部分存储到另外 N 台服务器上。每台服务器上的数据都是一个 Shard。
但是此时我们如何通过一次查询获取所有 Shard 上的数据呢?可以利用 Engine 能力在一个或多个服务器上创建 Distributed(分布式)表,该表不存储任何数据,只是将查询转发给所有主机并等待来自各个 Shard 的查询结果,然后计算后,返回最终查询结果(有点像 View)。
Tips: 哪怕不查询分布式表,直接查询原始表,也是可以直接获取部分数据的。这种每个 Shard 数据的独立设计在某些场景是合理的(e.g 前提规划哪台服务器可以写入哪类数据),非常灵活。若直接对分布式表写入数据,那么数据将会根据配置自动决定需要写入到哪个 Shard 中。
若想高可用,也可以添加 N 台额外的服务器组成 ClickHouse 集群。每台服务器上都有 Shard 的一个副本。通过分布式协调系统保证各节点的数据始终一致。
下图中,cluster_2S_1R 用于横向扩容场景,表示这是具有 2 个 Shards,每个 Shard 有 1 个 Replica 的集群;cluster_1S_2R 用于数据高可用场景,表示这是具有 1 个 Shard,每个 Shard 有 2 个 Replica 的集群。
比如
通过如下 SQL 可以查看集群的拓扑结构:
SELECT cluster, shard_num, replica_num, host_name, port
FROM system.clusters;
结果像这样
| cluster | shard_num | replica_num | host_name | port |
|---|---|---|---|---|
| my_cluster | 1 | 1 | host1 | 9000 |
| my_cluster | 1 | 2 | host3 | 9000 |
| my_cluster | 2 | 1 | host2 | 9000 |
| my_cluster | 2 | 2 | host4 | 9000 |
这种结果的配置来源于下面这种配置:
<remote_servers>
<my_cluster>
<shard>
<replica>
<host>host1</host>
<port>9000</port>
</replica>
<replica>
<host>host3</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>host2</host>
<port>9000</port>
</replica>
<replica>
<host>host4</host>
<port>9000</port>
</replica>
</shard>
</my_cluster>
</remote_servers>
这个集群共两个分片,将数据分别保存在 host1/host3 和 host2/host4 上,每个分片都有一个自己的备份
Distributed coordination
ClickHouseKeeper 必须单数节点,最少 3 个来保证选举。使用 RAFT 共识算法实现
ClickHouseKeeper 的逻辑也在 ClickHouse 程序的逻辑中,所以可以有两种运行方式:
- 与 ClickHouse 一起运行,作为其内部逻辑
- 独立运行
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.