select
概述
参考:
SQL 中最常见的操作(查询)使用声明性 SELECT 语句,SELECT 决定了要展示哪些数据
SELECT 1 AS "demo"
会生成下面这种表
| demo |
|---|
| 1 |
下面是一些查询时最基本的与 SELECT 配合的子句:
- FROM 子句,用于指定要检索数据的表。 FROM 子句可以包含可选的 JOIN 子句来指定另一个要检索数据的表(i.e. 多表联合查询)。
- WHERE 子句包含一个比较谓词,它限制查询返回的行。 WHERE 子句从结果集中消除比较谓词不计算为 True 的所有行。
- GROUP BY 子句将具有公共值的行投影到较小的行集中。GROUP BY 通常与 SQL 聚合函数结合使用,或用于从结果集中消除重复行。 WHERE 子句在 GROUP BY 子句之前应用。
- HAVING 子句包含一个谓词,用于过滤 GROUP BY 子句产生的行。由于聚合函数作用于 GROUP BY 子句的结果,因此可以在 HAVING 子句谓词中使用聚合函数。
- ORDER BY 子句标识使用哪个列对结果数据进行排序,以及按哪个方向对它们进行排序(升序或降序)。如果没有 ORDER BY 子句,则 SQL 查询返回的行的顺序是不确定的。
- FETCH FIRST 子句指定要返回的行数。有些 SQL 数据库有非标准的替代方案,例如 LIMIT、TOP 或 ROWNUM。常见 LIMIT
- OFFSET 子句指定开始返回数据之前要跳过的行数。
虽然 SELECT 位于语句最前面,它在逻辑处理中,基本上是最后一个被执行的部分。下面列出查询子句在逻辑上处理顺序:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- OFFSET
- LIMIT
select 用来从一个或多个表中检索匹配到的行,并将结果存储在一个结果表中。
select
[Modifiers]
<SelectExpr>
from
<TableReferences>
[where <WhereCondition>]
[limit N]
[offset M]
- select # 查询数据关键字
- Modifiers # 修饰符。可以针对某列或某些列进行一些数据的 去重、etc. 操作。
- SelectExpr # 要检索的列,可以使用
*以检索所有列。
- from # 关键字,指定要检索行的一个或多个表,多个表使用 , 分隔。
- TableReferences # 表引用。除了基本的直接使用表名,还可以通过 join 和 union 子句使用表达式引用表,甚至可以引用通过 select 返回的表。
- where # 从 from 中指定的表中所检索的行需要满足 where 定义的匹配条件。
- WhereCondition # 多个条件以
and和or关键字连接。
- WhereCondition # 多个条件以
- limit # 为返回的记录数
- offset # 可以指定 select 语句开始查询的数据偏移量,i.e. 选择从第 N 条数据开始查询。默认偏移量为 0。常用在分页场景。
Notes:
select 输出的内容本质是一个新表,所以我们时常可以看到下面这种语句
select t2.Name,
from (
select t.Name
from (
select *
from t_diversion diversion
left join t_data_lake lake on diversion.data_lake_code = lake.code
left join t_private_net net on diversion.private_net_code = net.code
) t
) t2
最里层的 select 返回了一个表,名命名为 t,然后第二层 select 的 from 来自于最里层 select 生成的表,以此类推。
SELECT
修饰符
在 SELECT 关键字之后,可以使用许多影响语句操作的修饰符。
ALL 和 DISTINCT 修饰符指定是否应返回重复行。
- ALL # 默认值。指定应返回所有匹配行,包括重复行。
- DISTINCT # 指定从结果集中删除重复行。
注意:同时指定两个修饰符是错误的。
FROM
参考:
要检索数据的表,可以是 具体存在的表、通过 SELECT 查询到的临时表、etc.
WHERE
过滤条件。比如 检索某列的数据是某值的所有行、etc.
JOIN
参考:
join 子句将一个或多个表根据条件合并为一个表
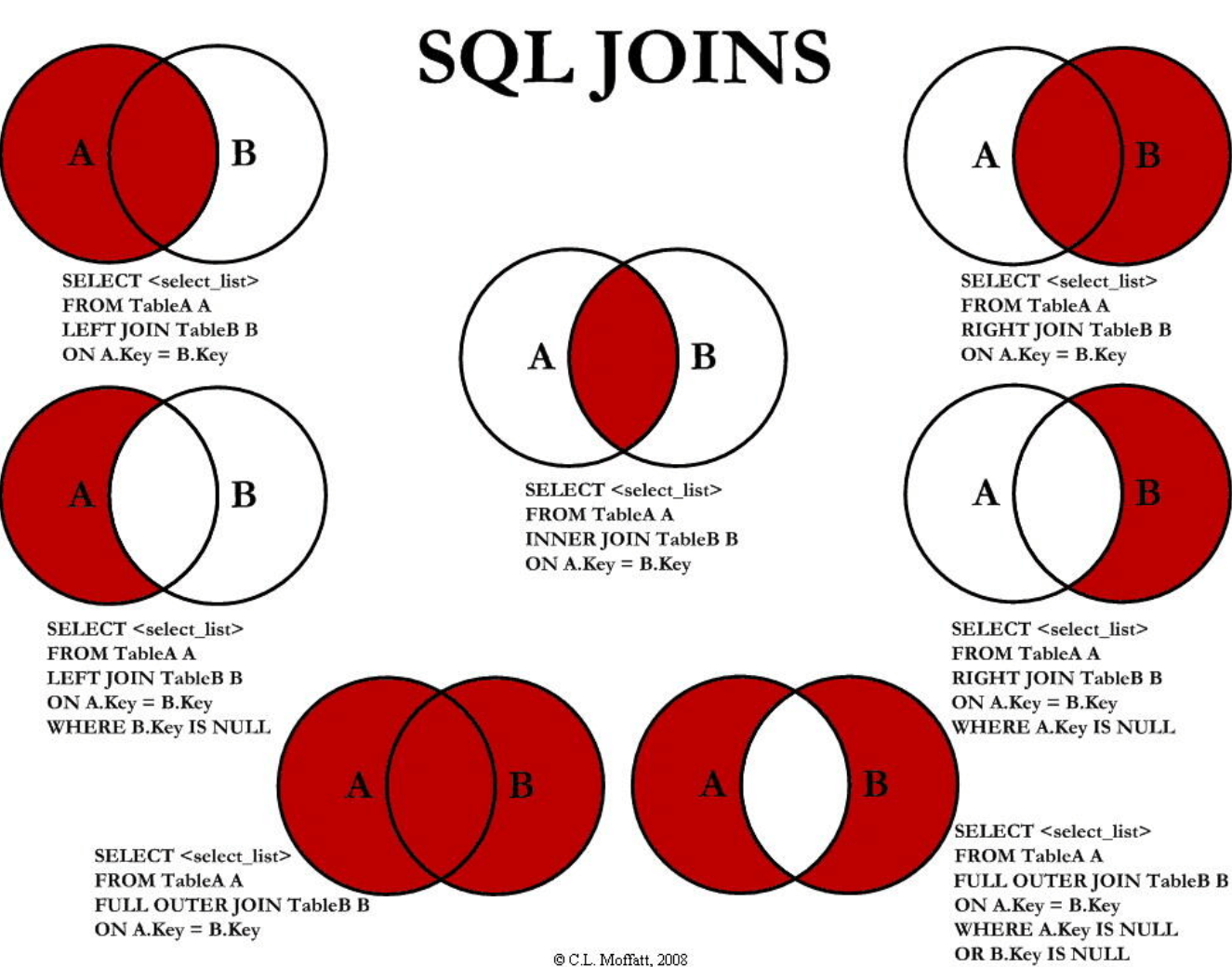
应用示例
从 inventory 表中返回所有行的所有列
MariaDB [caredaily]> select * from inventory;
+----+--------------+------+-----------+
| id | type | size | inventory |
+----+--------------+------+-----------+
| 1 | 果C精品 | NB | 1 |
| 2 | IP小飞侠 | NB | 5 |
| 3 | 果C精品 | NB | 50 |
| 4 | 新款丝薄 | XXL | 100 |
+----+--------------+------+-----------+
从 inventory 表中返回所有行的 type、size 列
MariaDB [caredaily]> select type,size from inventory;
+--------------+------+
| type | size |
+--------------+------+
| 果C精品 | NB |
| IP小飞侠 | NB |
| 果C精品 | NB |
| 新款丝薄 | XXL |
+--------------+------+
- 在 inventory 表中,对 amount 列的数据进行求和操作,条件是 product 列中所有的“新款丝薄”
select sum(amount) from inventory where product="新款丝薄";
多列模糊查询
SELECT * FROM card_descs WHERE concat(sc_name,effect,evo_cover_effect) LIKE '%奥米加%';
从 sc_name,effect,evo_cover_effect 这三列中搜索包含“奥米加”的行
等效于:
SELECT *
FROM card_descs
WHERE sc_name LIKE '%奥米加%'
OR effect LIKE '%奥米加%'
OR evo_cover_effect LIKE '%奥米加%';
获取某所有值并去重
distinct 简单来说就是用来去重的,而 group by 的设计目的则是用来聚合统计的,两者在能够实现的功能上有些相同之处,但应该仔细区分,因为用错场景的话,效率相差可以倍计。
单纯的去重操作使用 distinct,速度是快于 group by 的。
SELECT
distinct level
FROM
card_descs
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.