SQL
概述
参考:
Structured Query Language(结构化查询语言,简称 SQL) 是一种特定领域的编程语言,用于管理 RDBMS(关系数据库管理系统) 中保存的数据。使用 SQL 编写的语句也可以称为 Expression(表达式)。
SQL 在 1986 年成为 ANSI 的一项标准,在 1987 年成为国际标准化组织(ISO)标准。
每种关系型数据库所使用的 SQL 基本都一样,但是又有其自身特殊的 SQL。由于 MySQL 的使用率非常高,所以 SQL 文档的各种例子都以 MySQL 为主。
学习资料
SQL 标准
| Year | Name | Alias | Comments |
|---|---|---|---|
| 1986 | SQL-86 | SQL-87 | First formalized by ANSI |
| 1989 | SQL-89 | FIPS 127-1 | Minor revision that added integrity constraints adopted as FIPS 127-1 |
| 1992 | SQL-92 | SQL2, FIPS 127-2 | 主要修订 (ISO 9075), Entry Level SQL-92 adopted as FIPS 127-2 |
| 1999 | SQL:1999 | SQL3 | Added regular expression matching, recursive queries (e.g. transitive closure), triggers, support for procedural and control-of-flow statements, nonscalar types (arrays), and some object-oriented features (e.g. structured types), support for embedding SQL in Java (SQL/OLB) and vice versa (SQL/JRT) |
| 2003 | SQL:2003 | Introduced XML-related features (SQL/XML), window functions, standardized sequences, and columns with autogenerated values (including identity columns) | |
| 2006 | SQL:2006 | ISO/IEC 9075-14:2006 defines ways that SQL can be used with XML. It defines ways of importing and storing XML data in an SQL database, manipulating it within the database, and publishing both XML and conventional SQL data in XML form. In addition, it lets applications integrate queries into their SQL code with XQuery, the XML Query Language published by the W3C | |
| 2008 | SQL:2008 | Legalizes ORDER BY outside cursor definitions. Adds INSTEAD OF triggers, TRUNCATE statement,[34] FETCH clause | |
| 2011 | SQL:2011 | Adds temporal data (PERIOD FOR)[35] (more information at Temporal database#History). Enhancements for window functions and FETCH clause.[36] | |
| 2016 | SQL:2016 | Adds row pattern matching, polymorphic table functions, JSON | |
| 2019 | SQL:2019 | Adds Part 15, multidimensional arrays (MDarray type and operators) |
SQL 语法
参考:

SQL 语言被细分为几个语言元素,包括:
- Keywords(关键字) # SQL 语言中定义的单词。它们要么是保留的(例如 SELECT、COUNT、YEAR、etc.),要么是非保留的(例如 ASC、DOMAIN、KEY、etc.)
- Identifiers(标识符) # 数据库对象的名称,例如 表、列、模式、etc. 。
- Clauses(子句) # 它们是语句和查询的组成部分。(在某些情况下,这些是可选的。)
- Expressions(表达式) # 可以生成 标量值或由数据的 列 和 行 组成的表
- Predicates(谓词),指定可以评估为 SQL 三值逻辑 (3VL)(真/假/未知)或布尔 真值的条件,用于限制语句和查询的效果,或更改程序流程。
- Queries(查询),根据特定条件检索数据。这是 SQL 的一个重要元素。
- Statements(语句) # 可能对模式和数据产生持久影响,或者可能控制事务、程序流、连接、会话或诊断。
- SQL 语句还包括分号(
;) 语句终止符。虽然不是每个平台都需要它,但它被定义为 SQL 语法的标准部分。
- SQL 语句还包括分号(
- SQL 语句和查询中通常会忽略无关紧要的空格,从而更容易格式化 SQL 代码以提高可读性。
SQL 关键字
参考:
SELECT # 选择指定的数据存储在结果表中,称为结果集。有点类似于各种编程语言中的 print 函数。
FROM # 选择从哪个表中操作数据
WHERE # 过滤数据。以便处理匹配到到的记录
GROUP BY # 分组数据。根据指定列中相同的值所在的行和为一组。通常需要与聚合函数一起使用,否则将会报错。
ORDER BY # 对结果集排序(AES(正向) 或 DESC(逆向))
LIMIT # 限制结果集中返回的记录数
OFFSET # 从结果集中取第 X 条数据之后的数据
etc.
数据定义语句
create - 创建数据库或者表
create database NAME [ARGS];
create table NAME (Column_Name1 Column_Type1 [ARGS],….,Column_NameN Column_TypeN [ARGS])[ARGS];
其中 Column_Type 可以使用的参数,涉及每种关系型数据库的各自实现方式
ARGS
适用于创建 database 时使用的 ARGS:
- character set # 指定字符集为 CharacterName。定义了字符以及字符的编码。
- collation # 指定字符序为 CollationName。定义了字符的培训规则。
适用于创建 table 时使用的 ARGS: 在 () 外设置的 ARGS 将对所有列生效,也可以在 () 内对指定的列设置 ARGS
- null | not null # 指定该列是否可以插入 null 值。默认为 yes,可以插入。一般情况使用设置为 not null,原因见下面说明。
- default [VALUE] # 指定该列在插入数据为空时的默认值。默认插入 NULL。
- Note:如果当前列不设定 default 的 VALUE ,在插入数据时,如果不指定列的值。则会根据列的 null 或者 not null 来插入值
- 当 null 为 yes 时,默认插入 null
- 当 null 为 no 时,默认根据当前列的类型插入值,对于数值类型插入 0,字符串类型插入空字符串,时间戳类型插入当前日期和时间,ENUM 类型插入枚举组的第一条。
- e.g.当设置列为 not null、default 不指定 VALUE 时。在插入一个空值时,会报错。因为插入空值,会根据 default 的规则插入 null,但是又不能插入 null,所以插入失败
- comment # 指定该列的注释
- key | primary key | unique key | foreign key <(Column_Name)> # 指定 Column_Name 为该表的索引
- primary key # 关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- engine # 设置存储引擎
- charset=ENCODE # 设置编码为 ENCODE。一般设定为 utf8
- collate
适用于 int 类型数据的参数
- auto_increment # 指定该字段自动递增。该参数只适用于 int 类型。每个表有且只能有一个自动递增列,且必须将该列定义为 key
- unsigned # 指定该列的数值无符号,i.e.不会为负数
EXAMPLE
- 创建一个名为 caredaily 的数据库
- create database caredaily set utf8 collate utf8_general_ci;
- 创建名为 practice 的数据库,并且指定字符集为 utf8,字符序为 utf8_general_ci。
- create database
practicecharacter set utf8 collate utf8_general_ci;
- create database
- 创建一个名为 test 的表,其中只有名为 id 的列,类型是 int。
- create table
test(idint);
- create table
- 创建一个名为 product 的数据表。第一列名为 id 的 int 类型 ,无符号,自动递增。第二列名为 size 的 varchar(64) 类型。设定 id 列为主键。自动生成默认值,引擎为 innodb。编码为 utf8
create table `product` (
`id` int unsigned not null auto_increment,
`product` varchar(64) not null,
primary key (`id`)
)engine=innodb default charset=utf8;
- 创建一个名为 size 的表。
create table `size` (
`id` int unsigned not null auto_increment,
`size` varchar(64) not null,
primary key (`id`)
)engine=innodb default charset=utf8;
- 创建一个名为 inventory 的表。第四列名为 create_time 的 时间戳 类型
create table `inventory` (
`id` int unsigned not null auto_increment,
`src` varchar(64) not null default "总部",
`product` varchar(64) not null,
`size` varchar(64) not null,
`amount` int not null,
`create_time` timestamp not null,
primary key (`id`)
)engine=innodb default charset=utf8;
drop - 删除数据库或者表
drop {database|table} NAME;
truncate - 清空数据
EXAMPLE
- truncate table inventory; # 清空 emp 表,这个命令删除上万条记录特别快,因为他不记录日志
alter - 修改数据库或者数据表
alter database NAME; # 修改数据库的信息
alter table NAME; # 修改数据表的信息
EXAMPLE
- alter table inventory add column
create_timetimestamp; # 修改 inventory 表,添加名为 create_time 的列 - alter table inventory drop column
create_time# 删除 inventory 表中名为 create_time 的列
数据操作语句
参考:
delete - 删除数据表中的数据
delete from Table_Name [WHERE CLAUSE];
应用示例
- delete from inventory; # 删除 inventory 表中的所有数据,这个命令要是删除上万条记录很慢(因为他记录日志,可以利用日志还原)
- delete from inventory where size=“XXL”; # 删除 inventory 表中所有 size 为 XXL 的数据
insert - 插入数据
insert into TableNAME [Field1,Field2,…,FieldN] values (Value1,Value2,…,ValueN);
当不指定 Field 时,需要给表中每一列指定一个 Value。
应用示例
简单插入
向 card_prices 表中添加一条数据,card_id_from、sc_name 这两列的值分别为 3319、奥米加兽
INSERT INTO card_prices (card_id_from_db,sc_name) VALUES ("3319","奥米加兽");
select - 查询数据
详见 《查询》
update - 修改数据
update TableName set FIELD1=NewVALUES1,FIELD2=NewVALUES2,….. [where CLAUSE]
应用示例
- update inventory set size=“XXL” # 将 inventory 表中的 size 列中所有数据都改为 XXL
join 子语句
join 子语句用于 select,delete,update 语句的 table_references 部分,用以引用表。
用人话说:join 用于多表合并。所谓的表合并,就是为表中的行添加数据,两个表中的两个行,只要满足某列相同,即可将这两行数据合在一起,生成一个具有更多列的新行,多个新行组合在一起,形成一张新表。
假如现在有如下两个表:
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
执行如下语句将会生成一个新表
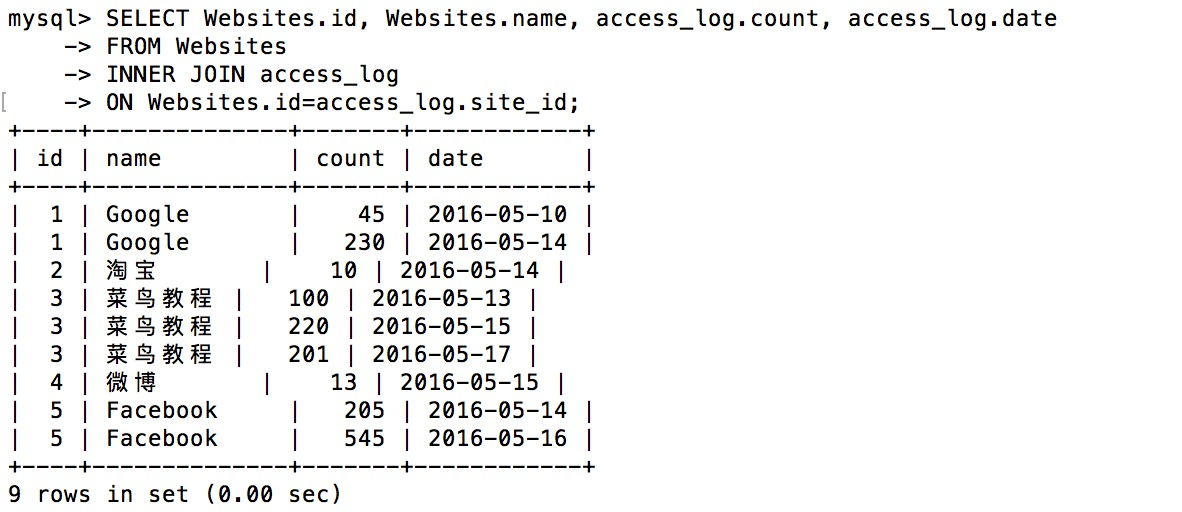
这里是将 Websites 表中 id 列和 access_log 表中 site_id 列进行对比,凡是相同的行都合并。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.