Etcd
概述
参考:
Etcd 是 CoreOS 基于 Raft 共识算法 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
- 基本的 key-value 存储,后端存储采用的是 BBolt 存储引擎,其前身是 BoltDB ,这是一款 golang 实现的嵌入式 KV 存储引擎,参考的是 LMDB,支持事务、ACID、MVCC、ZeroCopy、BTree 等特性。
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举
- 选举机制详见:Etcd 基于 RAFT 的一致性
Glossary(术语)
参考:
- Raft # etcd 所采用的保证分布式系统强一致性的算法。
- Endpoint(端点)# 指向 etcd 服务或资源的 URL 。比如 http://172.38.40.212:2379 就是 etcd 中的一个 endpoint ,这个 endpoint 指向了 172.38.40.212 设备的 2379 端口上的 etcd
- Node # 一个 Raft 状态机实例。
- Member(成员) # 一个 etcd 实例。它管理着一个 Node,并且可以为客户端请求提供服务。
- Member 是组成 etcd cluster 的一部分。一个逻辑概念,是集群中提供服务的 etcd 服务器。可以为一个 member 单独定义一个名字和描述等信息。
- Cluster(集群) # 由多个 Member 构成可以协同工作的 etcd 集群。
- Peer # 对同一个 etcd 集群中另外一个 Member 的称呼。
- Client # 向 etcd 集群发送 HTTP 请求的客户端。
- snapshot # etcd 防止 WAL 文件过多而设置的快照,存储 etcd 数据状态。
- Proxy # etcd 的一种模式,为 etcd 集群提供反向代理服务。
- Leader # Raft 算法中通过竞选而产生的处理所有数据提交的节点。
- Follower # 竞选失败的节点作为 Raft 中的从属节点,为算法提供强一致性保证。
- Candidate # 当 Follower 超过一定时间接收不到 Leader 的心跳时转变为 Candidate 开始竞选。
- Term # Raft 算法中的概念。某个节点成为 Leader 到下一次竞选时间,称为一个 Term。
- Index # 数据项编号。Raft 中通过 Term 和 Index 来定位数据。
Etcd 工作方式简述
每个 etcd 一般使用两个端口进行工作,一个端口面向客户端提供服务(2379),另一个端口集群内部通信(2380)。可以将 etcd 端口设置为接受 TLS 流量,非 TLS 流量,或同时接受 TLS 和非 TLS 流量。
数据读写顺序
为了保证数据的强一致性,etcd 集群中所有的数据流向都是一个方向,从 Leader (主节点)流向 Follower,也就是所有 Follower 的数据必须与 Leader 保持一致,如果不一致会被覆盖。
用户对于 etcd 集群所有节点进行读写
- 读取:由于集群所有节点数据是强一致性的,读取可以从集群中随便哪个节点进行读取数据
- 写入:etcd 集群有 leader,如果写入往 leader 写入,可以直接写入,然后然后 Leader 节点会把写入分发给所有 Follower,如果往 follower 写入,然后 Leader 节点会把写入分发给所有 Follower
leader 选举
假设三个节点的集群,三个节点上均运行 Timer(每个 Timer 持续时间是随机的),Raft 算法使用随机 Timer 来初始化 Leader 选举流程,第一个节点率先完成了 Timer,随后它就会向其他两个节点发送成为 Leader 的请求,其他节点接收到请求后会以投票回应然后第一个节点被选举为 Leader。
成为 Leader 后,该节点会以固定时间间隔向其他节点发送通知,确保自己仍是 Leader。有些情况下当 Follower 们收不到 Leader 的通知后,比如说 Leader 节点宕机或者失去了连接,其他节点会重复之前选举过程选举出新的 Leader。
判断数据是否写入
etcd 认为写入请求被 Leader 节点处理并分发给了多数节点后,就是一个成功的写入。那么多少节点如何判定呢,假设总结点数是 N,那么多数节点 Quorum=N/2+1。关于如何确定 etcd 集群应该有多少个节点的问题,上图的左侧的图表给出了集群中节点总数(Instances)对应的 Quorum 数量,用 Instances 减去 Quorom 就是集群中容错节点(允许出故障的节点)的数量。
所以在集群中推荐的最少节点数量是 3 个,因为 1 和 2 个节点的容错节点数都是 0,一旦有一个节点宕掉整个集群就不能正常工作了。
Etcd 监控指标
官方文档:https://etcd.io/docs/latest/op-guide/monitoring/
ID:3070 是一个不错的 grafana dashboard
每个 etcd 服务器在 /metrics 路径下暴露 metrics 。默认在 http://ETCDIP:2379/metrics 下。
可以使用 –listen-metrics-urls 参数单独指定 etcd 要暴露 metrics 的 ip 和 port。
~]$ curl -L http://localhost:2379/metrics | grep -v debugging # ignore unstable debugging metrics
# HELP etcd_disk_backend_commit_duration_seconds The latency distributions of commit called by backend.
# TYPE etcd_disk_backend_commit_duration_seconds histogram
etcd_disk_backend_commit_duration_seconds_bucket{le="0.002"} 72756
etcd_disk_backend_commit_duration_seconds_bucket{le="0.004"} 401587
etcd_disk_backend_commit_duration_seconds_bucket{le="0.008"} 405979
etcd_disk_backend_commit_duration_seconds_bucket{le="0.016"} 406464
...
健康检查
从 v3.3.0 开始,除了响应 /metrics 端点之外,–listen-metrics-urls 参数指定的任何位置也将响应 /health 端点。如果标准端点配置了相互(客户机)TLS 身份验证,但负载平衡器或监视服务仍需要访问运行状况检查,则此功能非常有用。
Etcd 关联文件与配置
/var/lib/etcd/ # Etcd 数据存储目录。该目录为默认目录,可以在配置文件的 ETCD_DATA_DIR 字段中修改路径
/etc/etcd/etcd.conf # 基本配置文件
/etc/etcd/etcd.conf.yaml # 与基本配置文件类似,可以已 yaml 的形式写配置文件。
下面是基本配置文件的示例
#[Member]
ETCD_DATA_DIR="/PATH" #etcd中的数据是基于内存的Key/Val存储,持久化之后,需要保存的目录即在此配置中定义
ETCD_LISTEN_PEER_URLS="Protocol://IP:PORT,...." #指定etcd集群内互相通信时所监听的端口,默认2380
ETCD_LISTEN_CLIENT_URLS="Protocol://IP:PORT,..." #指定etcd与其客户端(apiserver)通信时所监听的端口,默认2379
ETCD_NAME="HostName" #指定etcd所在节点的主机名
ETCD_SNAPSHOT_COUNT="NUM" #指定可以快照多少次,默认100000,
#[Clustering]
ETCD_INITAL_ADVERTISE_PEER_URLS="Protocol://{IP|HostName}:PORT,...." #一个声明,指定对外广告的etcd集群内互相通信时所监听的端口
ETCD_ADVERTISE_CLIENT_URLS="Protocol://{IP|HostName}:PORT,...." #一个声明,指定对外广告的etcd与其客户端(apiserver)通信时所监听的端口
ETCD_INITIAL_CLUSTER="HostName1=Protocol://HostName1:PORT,HostName2=Protocol://HostName2:PORT,......." #指定etcd集群初始成员信息,集群中有几个etcd就用写几个
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000" #
#ETCD_PROXY_REFRESH_INTERVAL="30000" #
#ETCD_PROXY_DIAL_TIMEOUT="1000" #
#ETCD_PROXY_WRITE_TIMEOUT="5000" #
#ETCD_PROXY_READ_TIMEOUT="0" #
#[Security]
ETCD_CERT_FILE="/PATH/FILE" #指定集群与客户端通信时所用的服务端证书
ETCD_KEY_FILE="/PATH/FILE" #指定集群与客户端通信时所用的服务端证书的私钥
ETCD_CLIENT_CERT_AUTH="false|ture" #指明是否验证客户端证书
ETCD_TRUSTED_CA_FILE="/PATH/FILE" ##指定签署服务端证书的CA证书
ETCD_AUTO_TLS="false|ture" #是否让etcd自动生成服务端证书
ETCD_PEER_CERT_FILE="/PATH/FILE" #指定集群间通信时所用的证书
ETCD_PEER_KEY_FILE="/PATH/FILE" #指定集群间通信时所用的证书的私钥
ETCD_PEER_CLIENT_CERT_AUTH="false|ture" #指明是否验证客户端(即apiserver)的证书(peer模式中各节点互为服务端和客户端)
ETCD_PEER_TRUSTED_CA_FILE="/PATH/FILE" #指定签署peer证书的CA证书
ETCD_PEER_AUTO_TLS="false|ture" #是否让etcd自动生成peer证书
#[Logging]
#ETCD_DEBUG="false" #
#ETCD_LOG_PACKAGE_LEVELS="" #
#ETCD_LOG_OUTPUT="default" #
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false" #
#[Version]
#ETCD_VERSION="false" #
#ETCD_AUTO_COMPACTION_RETENTION="0" #
#[Profiling]
#ETCD_ENABLE_PPROF="false" #
#ETCD_METRICS="basic" #
#[Auth]
#ETCD_AUTH_TOKEN="simple" #
Etcd 架构
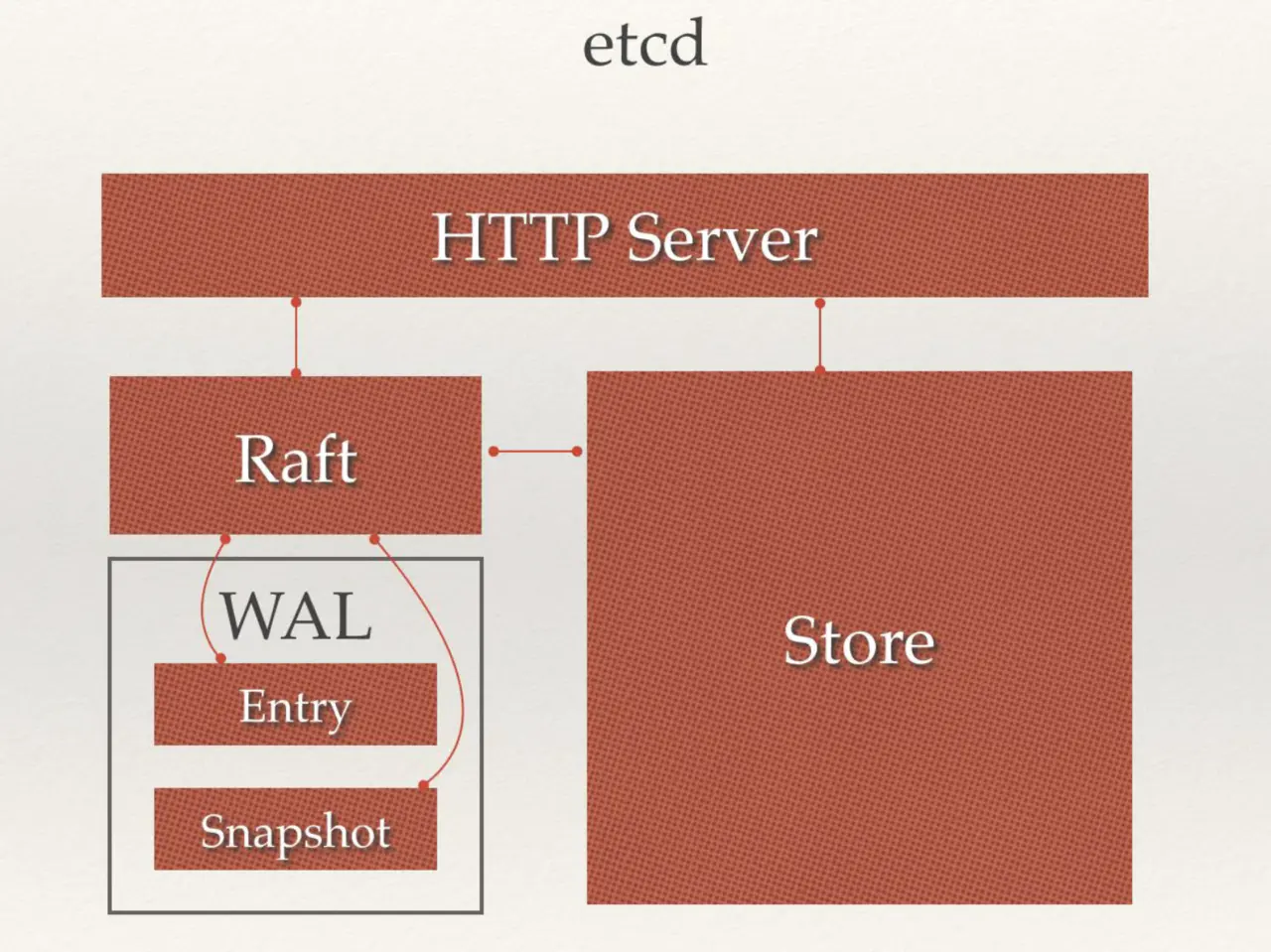
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
- HTTP Server:用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
- Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft:Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL:Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。
- Snapshot 是为了防止数据过多而进行的状态快照;
- Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
Etcd 应用场景
3.1 服务注册与发现
etcd 可以用于服务的注册与发现
- 前后端业务注册发现
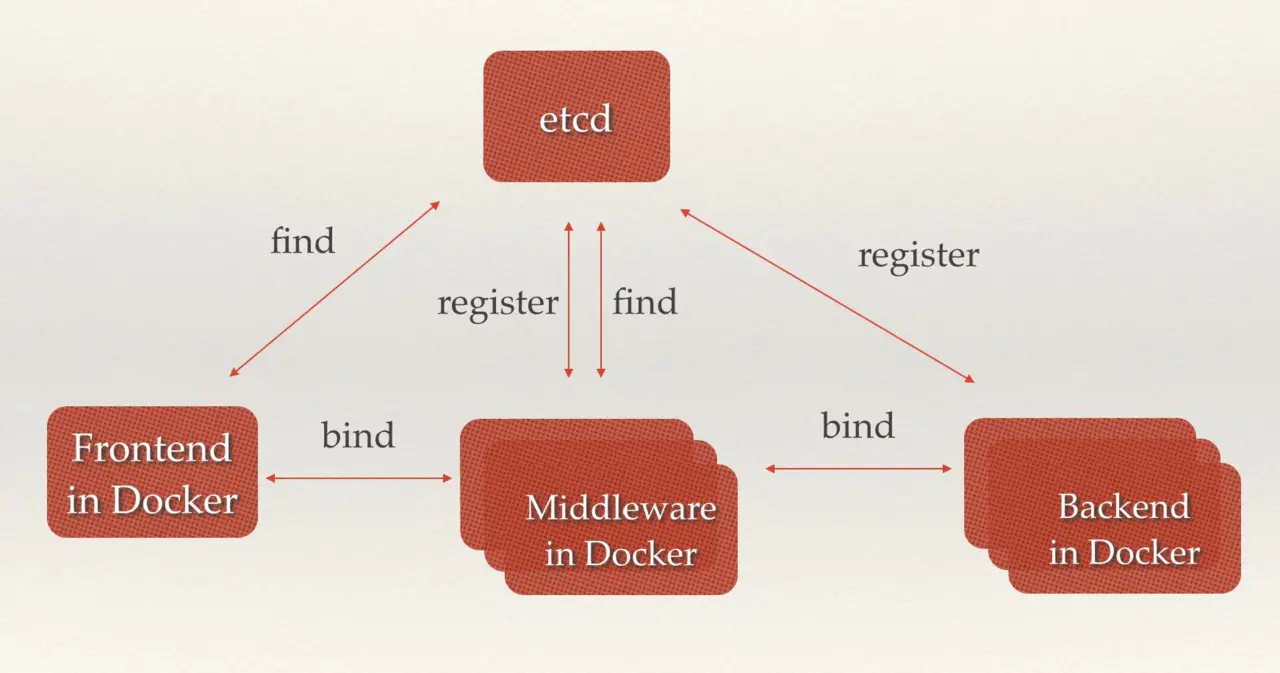
中间价已经后端服务在 etcd 中注册,前端和中间价可以很轻松的从 etcd 中发现相关服务器然后服务器之间根据调用关系相关绑定调用
- 多组后端服务器注册发现
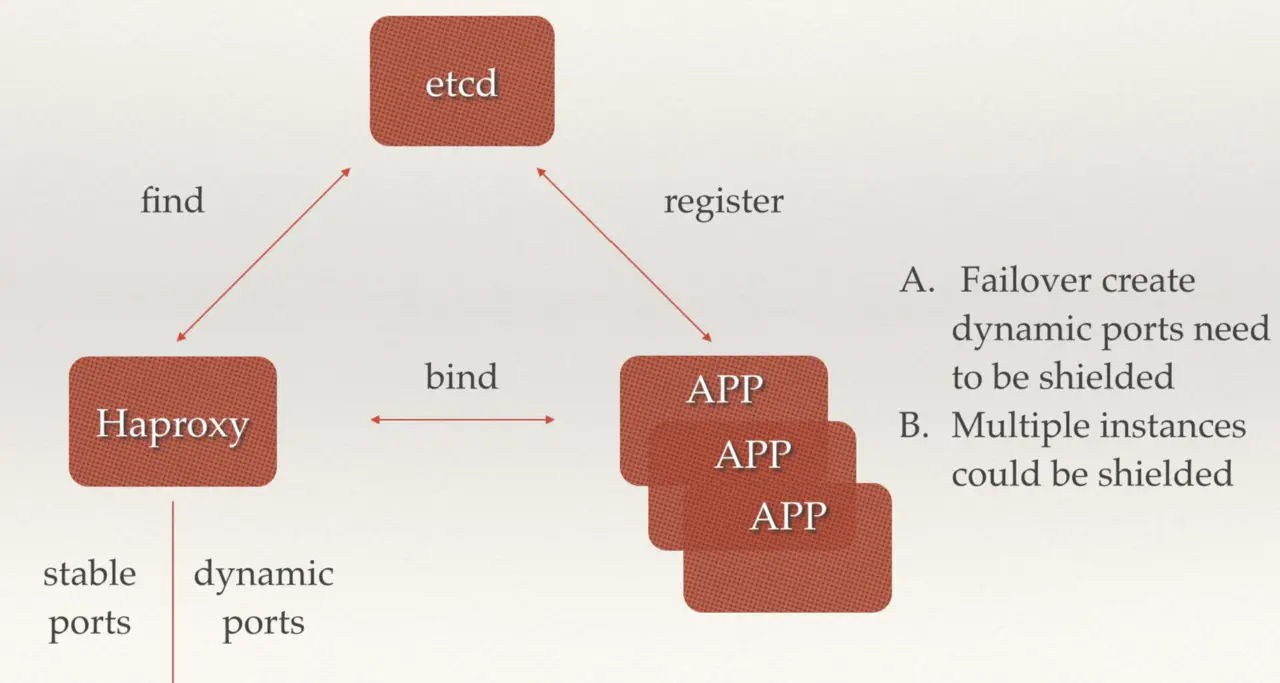
后端多个无状态相同副本的 app 可以同事注册到 etcd 中,前端可以通过 haproxy 从 etcd 中获取到后端的 ip 和端口组,然后进行请求转发,可以用来故障转移屏蔽后端端口已经后端多组 app 实例。
3.2 消息发布与订阅
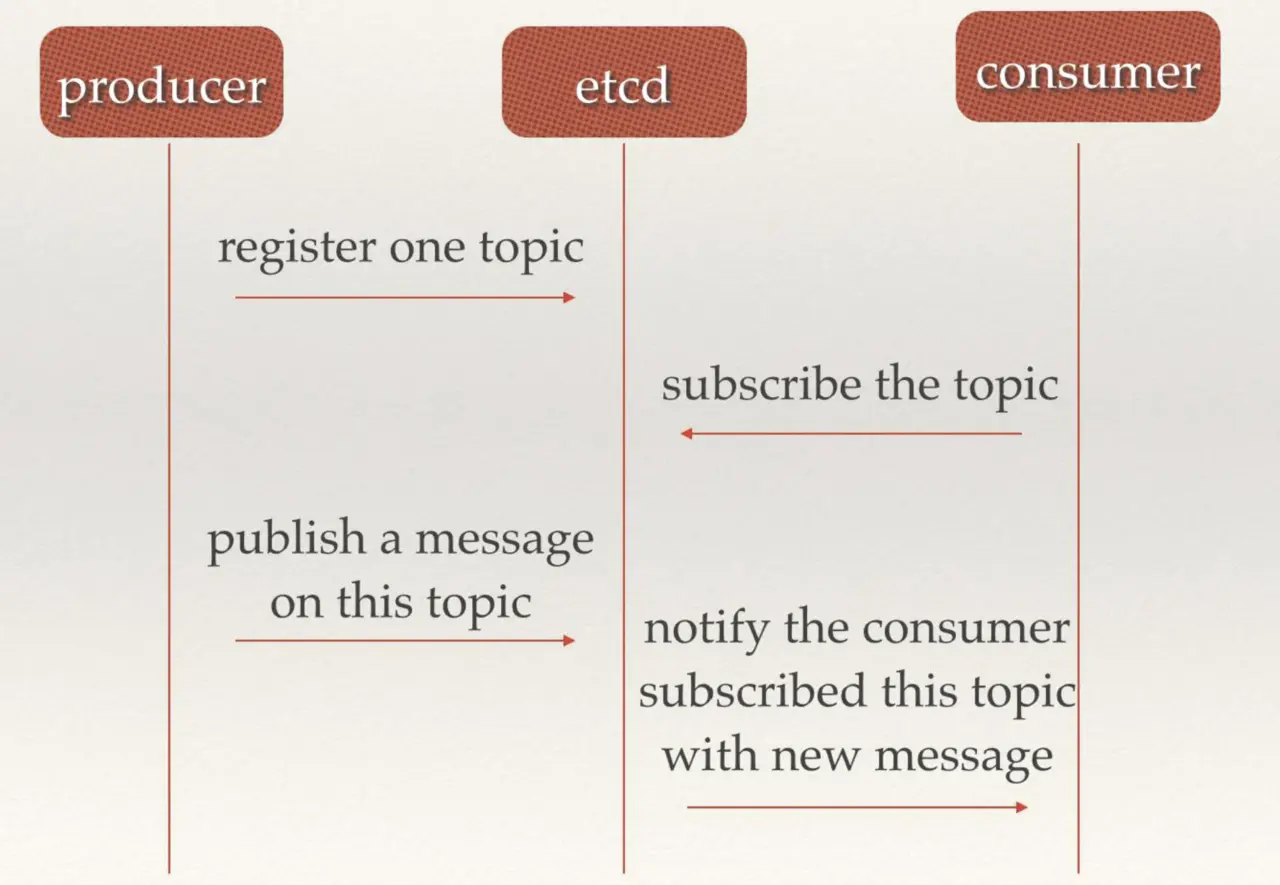
etcd 可以充当消息中间件,生产者可以往 etcd 中注册 topic 并发送消息,消费者从 etcd 中订阅 topic,来获取生产者发送至 etcd 中的消息。
3.3 负载均衡
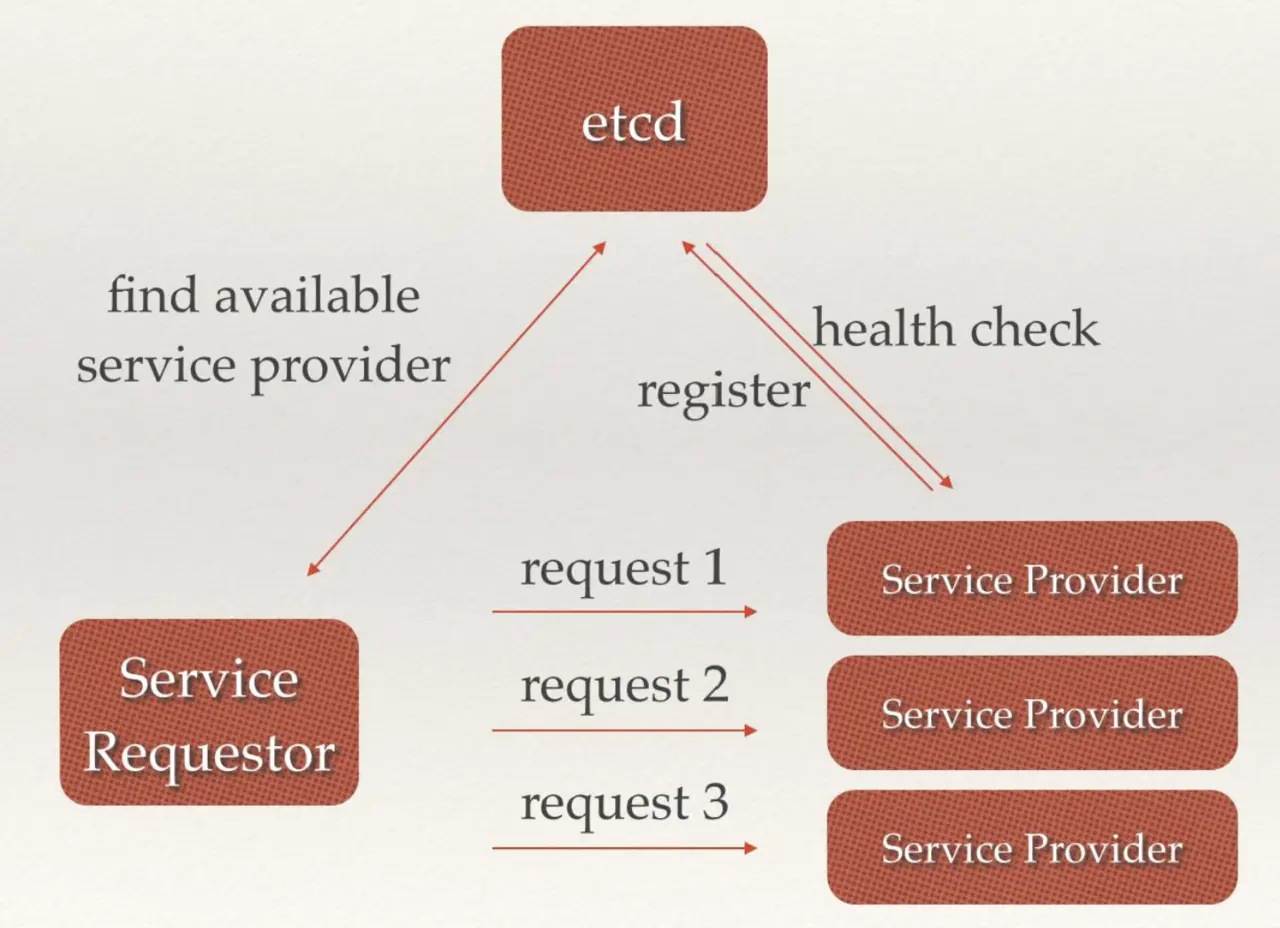
后端多组相同的服务提供者可以经自己服务注册到 etcd 中,etcd 并且会与注册的服务进行监控检查,服务请求这首先从 etcd 中获取到可用的服务提供者真正的 ip:port,然后对此多组服务发送请求,etcd 在其中充当了负载均衡的功能
3.4 分部署通知与协调
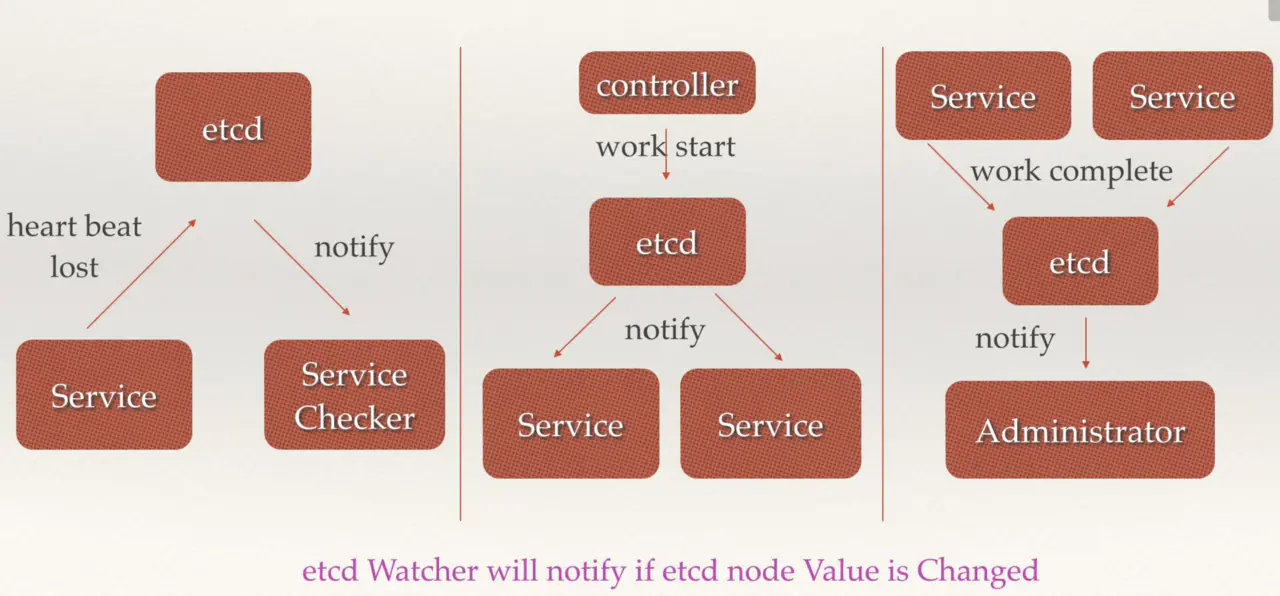
- 当 etcd watch 服务发现丢失,会通知服务检查
- 控制器向 etcd 发送启动服务,etcd 通知服务进行相应操作
- 当服务完成 work 会讲状态更新至 etcd,etcd 对应会通知用户
3.5 分布式锁
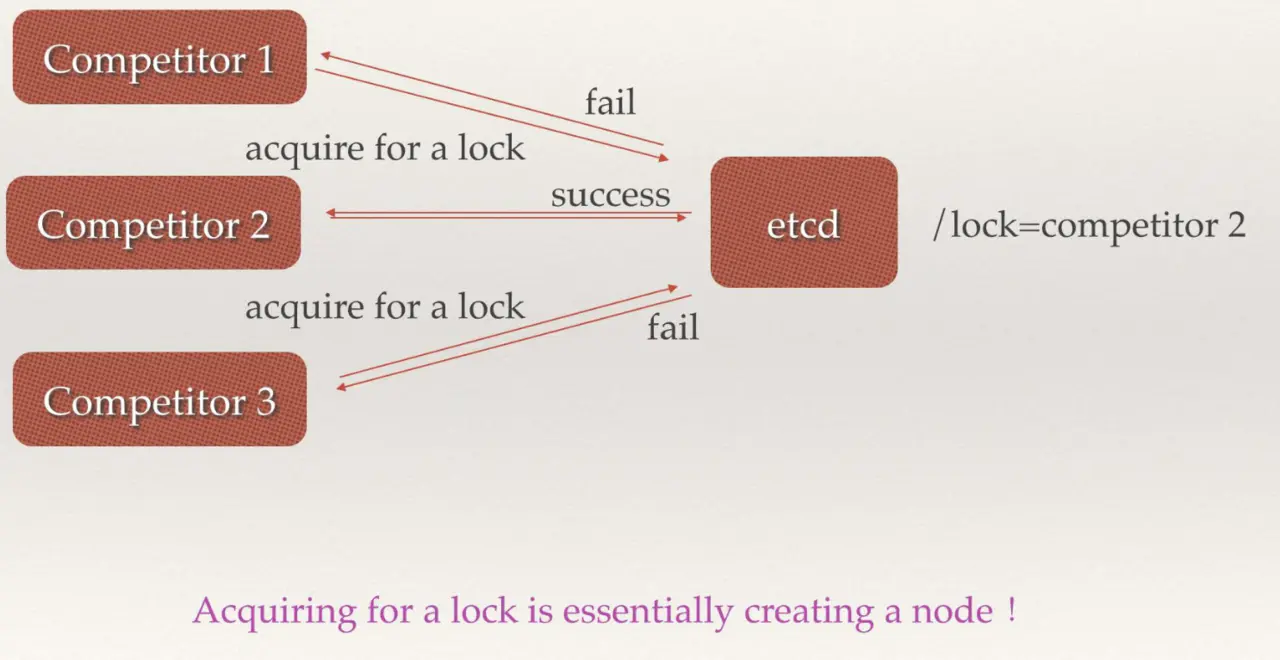
当有多个竞争者 node 节点,etcd 作为总控,在分布式集群中与一个节点成功分配 lock
3.6 分布式队列
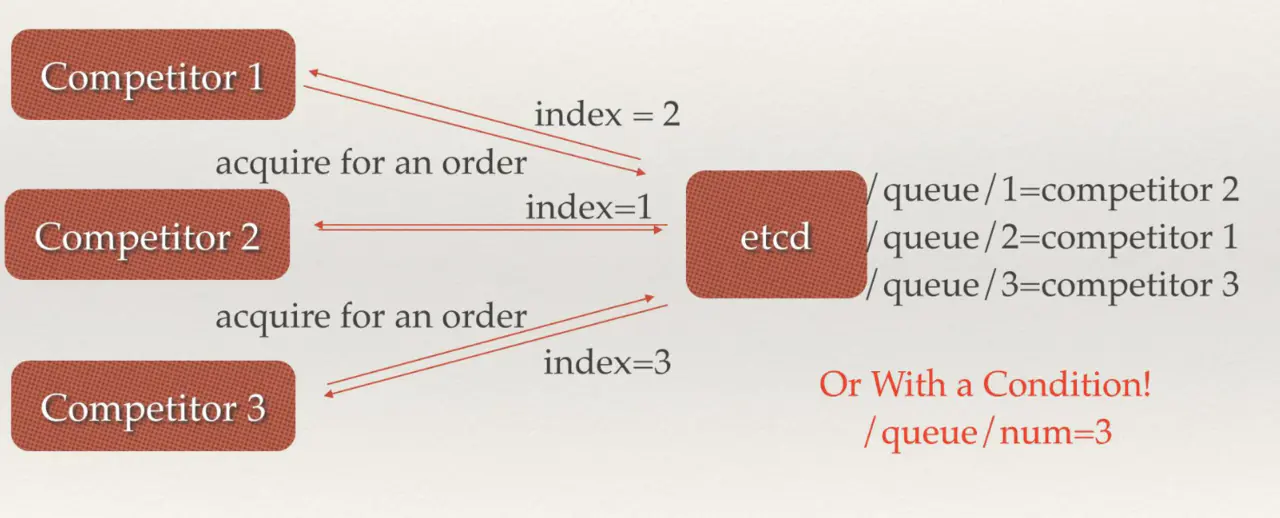
有对个 node,etcd 根据每个 node 来创建对应 node 的队列,根据不同的队列可以在 etcd 中找到对应的 competitor
3.7 集群与监控与 Leader 选举
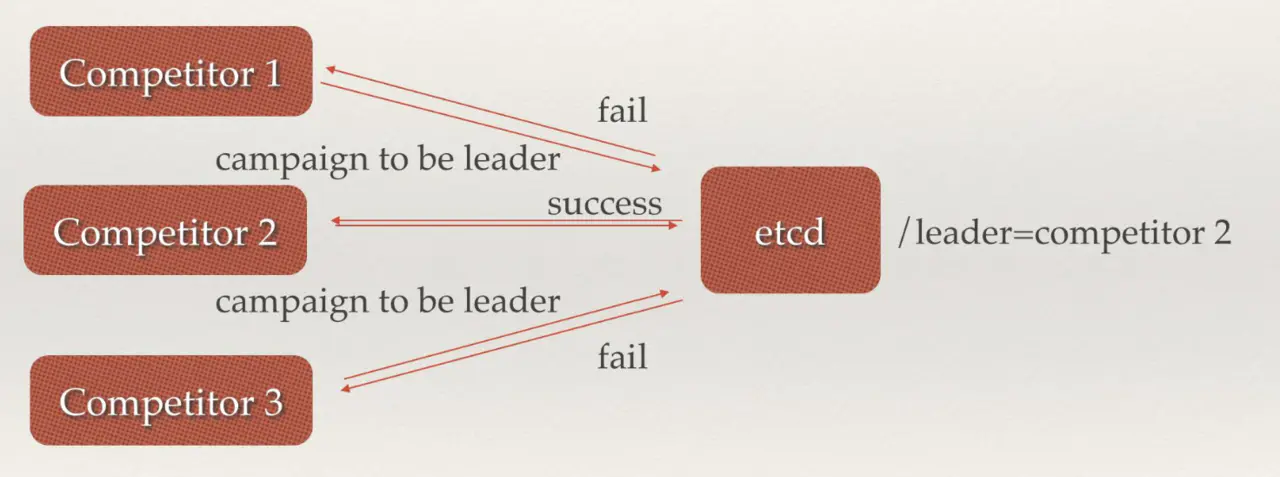
etcd 可以根据 raft 算法在多个 node 节点来选举出 leader
重大变化
2022 年 8 月 22 日 众所周知,etcd 是 Kubernetes 的核心组件之一,同时它也被大量其他的开源项目所依赖,比如 Apache APISIX 也是使用 etcd 作为其默认的数据存储的。 但是 etcd 最早的两个维护者,基本上都由于工作变动的原因已经不在 etcd 项目中积极活跃了。后来社区中剩余的一些贡献者开始承担起了该项目的维护工作。 在几个月之前,etcd 项目现有的维护者们,由于难以达到大多数人的同意,也发起了一次社区治理方案的调整,在决策时改成了惰性共识 https://github.com/etcd-io/etcd/pull/14053 当前 CNCF TOC 正在讨论 etcd 项目的健康度问题,也许我们可以做点什么,让这个项目变的更好。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.