Redis 高可用
概述
参考:
Redis 支持三种高可用方案
- Replication(复制) 模式
- 实际上,该模式并不是绝对的高可用,仅仅保证了数据的不丢失
- Sentinel(哨兵) 模式
- Cluster(集群) 模式
Cluster(集群)
http://www.redis.cn/topics/cluster-tutorial.html
https://redis.io/topics/cluster-tutorial
客户端操作原理(请求路由原理)
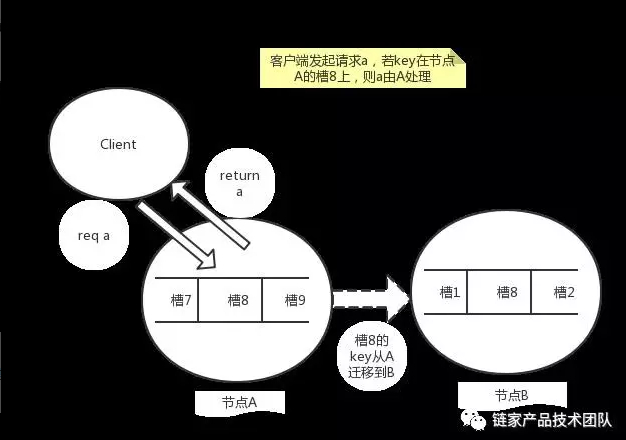
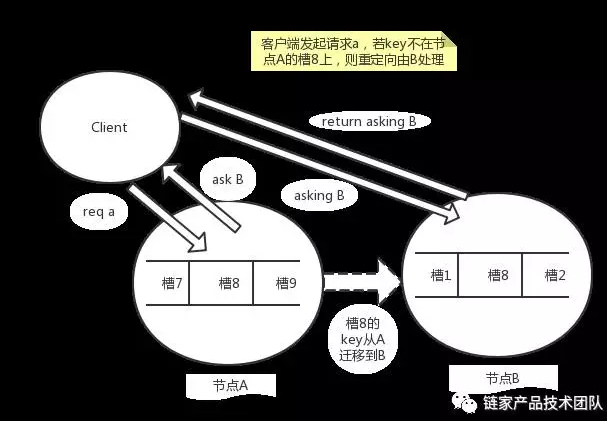
- 请求重定向
在集群模式下,Redis 接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED 重定向错误,通知客户端请求正确的节点。这个过程称为 MOVED 重定向。
# 如果key经过计算后,其分配的slot就在当前节点,那么可以请求成功,否则,回复重定向消息
[root@node01 redis]# redis-cli -h 10.0.0.100 -p 6379
10.0.0.100:6379> set name tom
OK
10.0.0.100:6379> set age 20
(error) MOVED 741 10.0.0.101:6379
重定向信息包含了键所对应的槽以及负责该槽的节点地址,根据这些信息客户端就可以向正确的节点发起请求。在 10.0.0.101:6379 节点上成功执行之前的命令:
[root@node02 redis]# redis-cli -h 10.0.0.101 -p 6379
10.0.0.101:6379> set age 20
OK
使用 redis-cli 命令时,可以加入-c 参数支持自动重定向,简化手动发起重定向的操作:
[root@node01 redis]# redis-cli -c -h 10.0.0.100 -p 6379
10.0.0.100:6379> set age 30
-> Redirected to slot [741] located at 10.0.0.101:6379
OK
redis-cli 自动帮我们连接到正确的节点执行命令,这个过程是在 redis-cli 内部维护,实质上是 client 端接到 MOVED 信息指定的节点之后再次发起请求,并不是在当前 Redis 节点中完成请求转发,节点对于不属于它的键命令只回复重定向响应,并不负责转发。
键命令执行步骤主要分两步:
- 计算槽
Redis 首先需要计算键所对应的槽,根据键的有效部分使用 CRC16 函数计算出散列值,再取对 16383 的余数,得到槽的编号,这样每个键都可以映射到 0~16383 槽范围内
10.0.0.101:6379> cluster keyslot age
(integer) 741
Redis 集群相对单机在功能上存在一些限制,限制如下:
key 批量操作支持有限,如 mset、mget,目前只支持具有相同 slot 值的 key 执行批量操作。对于映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上因此不被支持
key 事务操作支持有限,同理只支持多 key 在同一节点上的事务操作,当多个 key 分布在不同的节点上时无法使用事务功能
key 作为数据分区的最小粒度,因此不能将一个大的键值对象如 hash、list 等映射到不同的节点
不支持多数据库空间,单机下的 Redis 可以支持 16 个数据库,集群模式下只能使用一个数据库空间,即 db0
复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构
10.0.0.102:6379> mget name age (error) CROSSSLOT Keys in request don’t hash to the same slot
但通常会有这样的需求,例如把一个用户的信息存入到一个 slot 中,这是可以这样设置:
10.0.0.102:6379> set user:{user1}:name tony
-> Redirected to slot [8106] located at 10.0.0.100:6379
OK
10.0.0.100:6379> set user:{user1}:age 20
OK
10.0.0.100:6379> cluster keyslot user:{user1}:name
(integer) 8106
10.0.0.100:6379> cluster keyslot user:{user1}:age
(integer) 8106
10.0.0.100:6379> mget user:{user1}:name user:{user1}:age
1) "tony"
2) "20"
这样,这两个 key 在计算 hash 值的时候,不会根据整个 key 来计算,而是只是拿{}中的内容的来计算,这样它们的 hash 值一定是相同的,就可以分配到同一个 slot 中,{}中的内容称为 hash_tag
- 查找槽所对应的节点
Redis 计算得到键对应的槽后,需要查找槽所对应的节点。集群内通过消息交换每个节点都会知道所有节点的槽信息。
根据 MOVED 重定向机制,客户端可以随机连接集群内任一 Redis 获取键所在节点,这种客户端又叫 Dummy(傀 儡)客户端,它优点是代码实现简单,对客户端协议影响较小,只需要根据重定向信息再次发送请求即可。但是它的弊端很明显,每次执行键命令前都要到 Redis 上进行重定向才能找到要执行命令的节点,额外增加了 IO 开销,这不是 Redis 集群高效的使用方式。正因为如此通常集群客户端都采用另一种实现:Smart 客户端
Cluster 模式的优缺点
优点:
无中心架构,数据按照 slot 分布在多个节点。
集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
可线性扩展到 1000 多个节点,节点可动态添加或删除
能够实现自动故障转移,节点之间通过 gossip 协议交换状态信息,用投票机制完成 slave 到 master 的角色转换
缺点:
客户端实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度。目前仅 JedisCluster 相对成熟,异常处理还不完善,比如常见的“max redirect exception”
节点会因为某些原因发生阻塞(阻塞时间大于 cluster-node-timeout)被判断下线,这种 failover 是没有必要的
数据通过异步复制,不保证数据的强一致性
slave 充当“冷备”,不能缓解读压力
批量操作限制,目前只支持具有相同 slot 值的 key 执行批量操作,对 mset、mget、sunion 等操作支持不友好
key 事务操作支持有线,只支持多 key 在同一节点的事务操作,多 key 分布不同节点时无法使用事务功能
不支持多数据库空间,单机 redis 可以支持 16 个 db,集群模式下只能使用一个,即 db 0
Redis Cluster 模式不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
Sentinel 与 Cluster 的区别
……我感觉楼主自己对 redis 的理解是有一定问题的,但提的问题其实是个好问题,而回帖的大部分人没有回应准确楼主的疑问,少部分评论我看一眼就明白,但楼主可能是想不到的。
那咱们把集群和哨兵能解决的问题列出来,就比较清楚了。
哨兵: 哨兵仅仅提供故障切换能力,在这之上,对使用方来说,和单机的 redis 是完全一样的。
集群: 集群最主要的,解决的是一个“数据分片”的问题,它能把 redis 的数据分散到不同的 slot 里,而不是都集中在一台机器的内存里。这样也就给单进程单线程、纯内存的 redis 提供了水平扩容的能力。
但是这是有代价的, 一部分命令无法跨节点执行,比如 zunionstore 等一些命令,它涉及多个 key,因此在集群状态下,需要自行保证这些 key 都在一个 slot 上;
再比如 watch exec, 在单节点或哨兵场景下可以用,但集群模式下是不能使用的。
还有一些命令,在集群状态下虽能执行或有替代方案,但会丧失原子性。 比如 mget 等。
所以楼主的疑问是为什么集群模式没有取代哨兵模式,是因为哨兵模式作为单节点+高可用的方案而言,确实有集群模式实现不了的功能。
……想换行不小心发出去了。
除了功能上的区别以外,集群模式显然比哨兵模式更重、需要更多的资源去运行;再就是部署运维复杂度也是更高的。
而哨兵和单节点,一般来说除了配置稍有区别以外,绝大部分业务代码是可以相容的,无需特地修改。
而现有的代码如果使用了集群模式不支持的那些命令,那么集群模式下是无法正常工作的。
所以目前哨兵模式仍然被广泛使用,没有被集群模式彻底替代。
我们公司就是用哨兵了。为什么不用 Cluster 。因为费钱。集群需要机器太多了。本身数据量就不大。分片功能不需要。 就只是想要一个高可用的 redis 。 用哨兵符合需求了。 只需要三台机器。而且三台机器还部署了 3 个 zookeeper 和 kafka 。都是数据量不大。 节约机器钱
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.