Templates and Variables(模板与变量)
概述
参考:
在前面的小节中介绍了 Grafana 中 4 中常用的可视化面板的使用,通过在面板中使用 PromQL 表达式,Grafana 能够方便的将 Prometheus 返回的数据进行可视化展示。例如,在展示主机 CPU 使用率时,我们使用了如下表达式:
1 - (avg(irate(node_cpu{mode='idle'}[5m])) without (cpu))
该表达式会返回当前 Promthues 中存储的所有时间序列,每一台主机都会有一条单独的曲线用于体现其 CPU 使用率的变化情况:

而当用户只想关注其中某些主机时,基于当前我们已经学习到的知识只有两种方式,要么每次手动修改 Panel 中的 PromQL 表达式,要么直接为这些主机创建单独的 Panel。但是无论如何,这些硬编码方式都会直接导致 Dashboard 配置的频繁修改。在这一小节中我们将学习使用 Dashboard 变量的方式解决以上问题。
变量
在 Grafana 中用户可以为 Dashboard 定义一组变量(Variables),变量一般包含一个到多个可选值。如下所示,Grafana 通过将变量渲染为一个下拉框选项,从而使用户可以动态的改变变量的值:
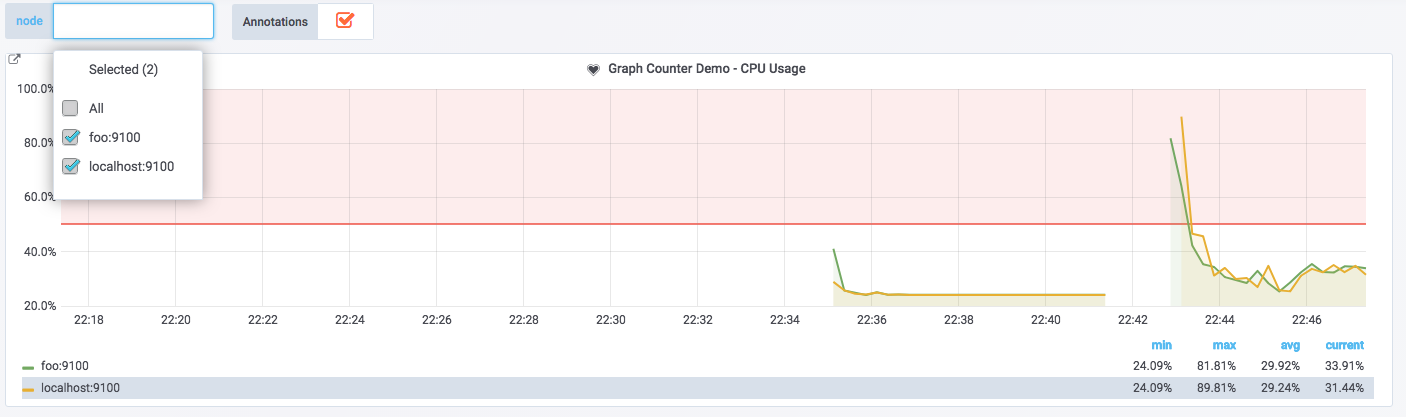
Dashboard 变量
例如,这里定义了一个名为 node 的变量,用户可以通过在 PromQL 表达式或者 Panel 的标题中通过以下形式使用该变量:
1 - (avg(irate(node_cpu{mode='idle', instance=~"$node"}[5m])) without (cpu))
变量的值可以支持单选或者多选,当对接 Prometheus 时,Grafana 会自动将$node 的值格式化为如“host1|host2|host3”的形式。配合使用 PromQL 的标签正则匹配“=~”,通过动态改变 PromQL 从而实现基于标签快速对时间序列进行过滤。
变量定义
通过 Dashboard 页面的 Settings 选项,可以进入 Dashboard 的配置页面并且选择 Variables 子菜单:
 为 Dashboard 添加变量
为 Dashboard 添加变量
用户需要指定变量的名称,后续用户就可以通过$variable_name 的形式引用该变量。Grafana 目前支持 6 种不同的变量类型,而能和 Prometheus 一起工作的主要包含以下 5 种类型:
| 类型 | 工作方式 |
| Query | 允许用户通过 Datasource 查询表达式的返回值动态生成变量的可选值 |
| Interval | 该变量代表时间跨度,通过 Interval 类型的变量,可以动态改变 PromQL 区间向量表达式中的时间范围。如 rate(node_cpu[$interval]) |
| Datasource | 允许用户动态切换当前 Dashboard 的数据源,特别适用于同一个 Dashboard 展示多个数据源数据的情况 |
| Custom | 用户直接通过手动的方式,定义变量的可选值 |
| Constant | 常量,在导入 Dashboard 时,会要求用户设置该常量的值 |
Label 属性用于指定界面中变量的显示名称,Hide 属性则用于指定在渲染界面时是否隐藏该变量的下拉框。
使用变量过滤时间序列
当 Prometheus 同时采集了多个主机节点的监控样本数据时,用户希望能够手动选择并查看其中特定主机的监控数据。这时我们需要使用 Query 类型的变量。
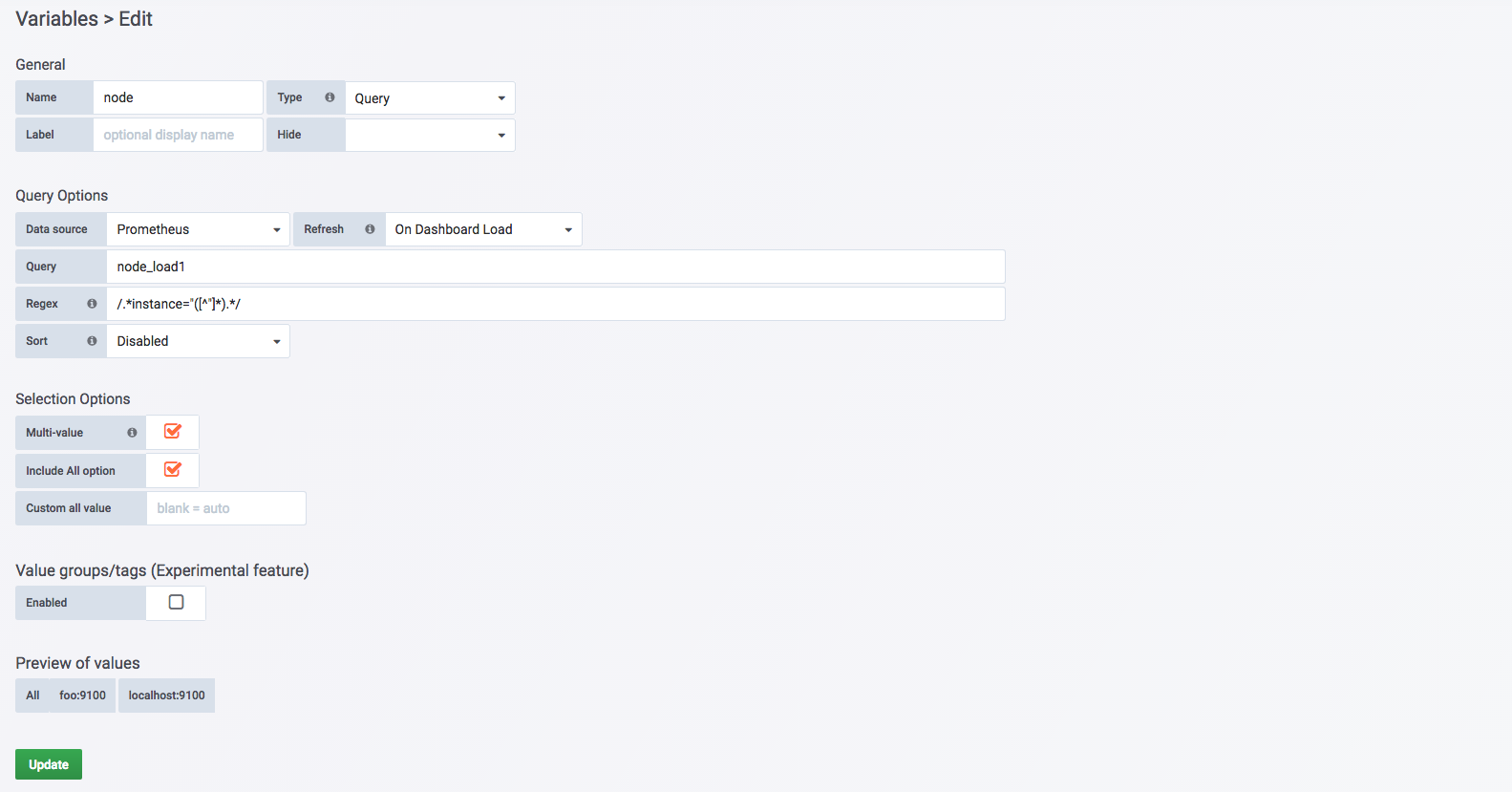
新建 Query 类型的变量
如上所示,这里我们为 Dashboard 创建了一个名为 node 的变量,并且指定其类型为 Query。Query 类型的变量,允许用户指定数据源以及查询表达式,并通过正则匹配(Regex)的方式对查询结果进行处理,从而动态生成变量的可选值。在这里指定了数据源为 Prometheus,通过使用 node_load1 我们得到了两条时间序列:
node_load1{instance="foo:9100",job="node"}
node_load1{instance="localhost:9100",job="node"}
通过指定正则匹配表达式为/.*instance="([^"]*).*/从而匹配出标签 instance 的值作为 node 变量的所有可选项,即:
foo:9100
localhost:9100
Selection Options选项中可以指定该变量的下拉框是否支持多选,以及是否包含全选(All)选项。
保存变量后,用户可以在 Panel 的 General 或者 Metrics 中通过$node 的方式使用该变量,如下所示:

在 Metrics 中使用变量
这里需要注意的是,如果允许用户多选在 PromQL 表达式中应该使用标签的正则匹配模式,因为 Grafana 会自动将多个选项格式化为如“foo:9100|localhost:9100”的形式。
使用 Query 类型的变量能够根据允许用户能够根据时间序列的特征维度对数据进行过滤。在定义 Query 类型变量时,除了使用 PromQL 查询时间序列以过滤标签的方式以外,Grafana 还提供了几个有用的函数:
- label_values(LABEL) # 返回 Promthues 所有监控指标中,标签名为 LABEL 的所有可选值
- label_values(METRIC, LABEL) # 返回监控指标 METRIC 中,标签名为 LABEL 的所有可选值
- metrics(RegEx) # 返回所有满足 RegEx(正则表达式) 匹配到的指标名称
- query_result(PromQL) # 返回 PromQL 的查询结果
例如,当需要监控 Prometheus 所有采集任务的状态时,可以使用如下方式,获取当前所有采集任务的名称:
label_values(up, job)
例如,有时候我们想要动态修改变量查询结果。比如某一个节点绑定了多个 ip,一个用于内网访问,一个用于外网访问,此时 prometheus 采集到的指标是内网的 ip,但我们需要的是外网 ip。这里我们想要能在 Grafana 中动态改变标签值,进行 ip 段的替换,而避免从 prometheus 或 exporter 中修改采集指标。
这时需要使用 grafana 的 query_result 函数
# 将10.10.15.xxx段的ip地址替换为10.20.15.xxx段 注:替换端口同理
query_result(label_replace(kube_pod_info{pod=~"$pod"}, "node", "10.20.15.$1", "node", "10.10.15.(.*)"))
# 通过正则从返回结果中匹配出所需要的ip地址
regex:/.*node="(.*?)".*/
在 grafana 中配置如图:

使用变量动态创建 Panel 和 Row
当在一个 Panel 中展示多条时间序列数据时,通过使用变量可以轻松实现对时间序列的过滤,提高用户交互性。除此以外,我们还可以使用变量自动生成 Panel 或者 Row。 如下所示,当需要可视化当前系统中所有采集任务的监控任务运行状态时,由于 Prometheus 的采集任务配置可能随时发生变更,通过硬编码的形式实现,会导致 Dashboard 配置的频繁变更:
 Prometheus 采集任务状态
Prometheus 采集任务状态
如下所示,这里为 Dashboard 定义了一遍名为 job 的变量:
 使用变量获取当前所有可选任务
使用变量获取当前所有可选任务
通过使用 label_values 函数,获取到当前 Promthues 监控指标 up 中所有可选的 job 标签的值:
label_values(up, job)
如果变量启用了 Multi-value 或者 Include All Option 选项的变量,那么在 Panel 的 General 选项的 Repeat 中可以选择自动迭代的变量,这里使用了 Singlestat 展示所有监控采集任务的状态:
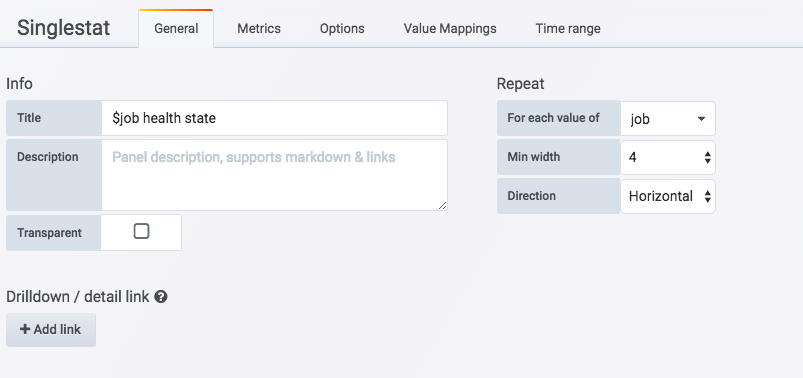 General 中的 Repeat 选项
General 中的 Repeat 选项
Repeat 选项设置完成后,Grafana 会根据当前用户的选择,自动创建一个到多个 Panel 实例。 为了能够使 Singlestat Panel 能够展示正确的数据,如下所示,在 Prometheus 中,我们依然使用了$job变量,不过此时的$job 反应的是当前迭代的值:
 在 Metric 中使用变量
在 Metric 中使用变量
而如果还希望能够自动生成 Row,只需要在 Row 的设置中,选择需要 Repeat 的变量即可:
 Repeat Row
Repeat Row
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.