PromQL Functions
概述
参考:
Prometheus 提供了其它大量的内置函数,可以对时序数据进行丰富的处理。在代码 promql/functions.go 中可以看到当前所有可用的 PromQL 函数。
函数的语法
某些函数有默认的参数,例如:year(v=vector(time()) instant-vector)。这是一个标准的函数结构 函数名(形参 形参的类型)
- instant-vector # 表示参数类型,该类型表示一个瞬时向量表达式
- range-vector 表示一个范围向量表达式
- v # 表示这是 year 函数中,instant-vector 类型的形参
- vector(time()) # 表示参数 v 的默认值。
比如 absent(up) 这个表达式中,up 就是传递给参数 v 的值,是一个瞬时向量表达式。absent 表示该函数的功能。
基本函数
vector() # vector(s scalar) 函数将标量 s 作为没有标签的即时向量返回,即返回结果为:key: value= {}, s
absent() - 判断表达式是否可以获取到序列
absent(v instant-vector) 返回值有两种
- 空向量 # 如果传递给它的向量参数具有样本数据,返回空向量,就是不返回任何时间序列的意思。
- 1 # 如果传递的向量参数没有样本数据,则返回不带度量指标名称且带有标签的时间序列,且样本值为 1。
效果如下:
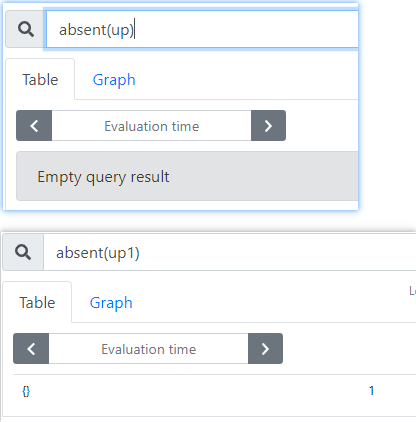
absent() 函数特别适用于告警,用于判断单条时间序列(给定 Name 与 Label 组合成的 Metrics)是否存在。
比如,现在有如下两条时间序列
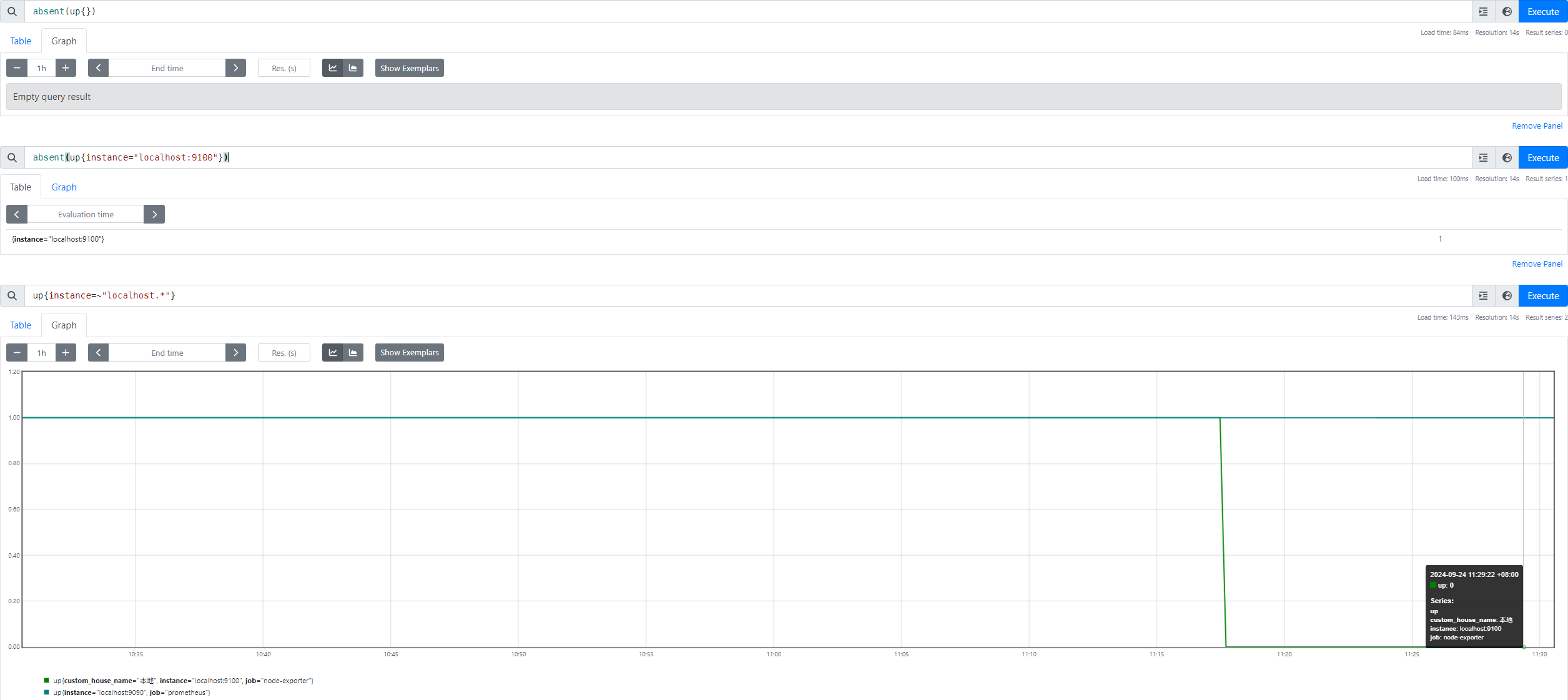
从图中前两个 promql 的结果可以看出来,只有对具体的单一的时间序列进行 absent 的判断,才可以触发。若一个 Metrics Name 下有多条时间序列,那么就算其中一条没数据了,通过 absent() 也无法判断 up 中所有时间序列是否存在,而是对 up 本身是否存在进行判断。
Tip: 若想判断一个 Metrics Name 具体有哪条时间序列缺了数据,可以尝试使用 count_over_time(),基于一段时间的样本总数进行判断。e.g.
delta(count_over_time(up[1d])[15m:]) < 0判断一下 1 天中获取的样本数量,通过样本数量的下降来判断是否数据丢失。
changes() - 范围向量内每个样本数值的变化次数
changes(v range-vector) 输入一个区间向量, 返回这个区间向量内每个样本数据值变化的次数(瞬时向量)。例如:
# 如果样本数据值没有发生变化,则返回结果为 1;若 10 秒采集一次,共 6 个样本,6 个样本中每个值都不一样的话,则结果为 6
changes(node_load5{instance="192.168.1.75:9100"}[1m]) # 结果为 1
clamp_max()
clamp_max(v instant-vector, max scalar) 函数,输入一个瞬时向量和最大值,样本数据值若大于 max,则改为 max,否则不变。例如:
node_load5{instance="192.168.1.75:9100"} # 结果为 2.79
clamp_max(node_load5{instance="192.168.1.75:9100"}, 2) # 结果为 2
clamp_min()
clamp_min(v instant-vector, min scalar) 函数,输入一个瞬时向量和最小值,样本数据值若小于 min,则改为 min,否则不变。例如:
node_load5{instance="192.168.1.75:9100"} # 结果为 2.79
clamp_min(node_load5{instance="192.168.1.75:9100"}, 3) # 结果为 3
resets()
resets(v range-vector) 的参数是一个区间向量。对于每个时间序列,它都返回一个计数器重置的次数。两个连续样本之间的值的减少被认为是一次计数器重置。
这个函数一般只用在计数器类型的时间序列上。
变化量相关
概述
变化量相关的函数通常都以 FuncName(v ragnge-vector) 格式使用,用以计算 范围向量 v 中 2 个或多个元素之间的变化情况(e.g. 差值、变化率、etc.)
外推处理
在进行计算时,根据获取样本值的方式分为两类计算逻辑
| 英文 | 中文 | 描述 | ||
|---|---|---|---|---|
| extrapolated | 外推/推测 | 推测样本到整个时间范围 | 函数名前面没有 i ,比如 rate, delta, etc. | 取时间范围内的 第一个 和 最后一个 值进行计算 |
| instant | 即时/瞬间 | 不推测样本到整个时间范围 | 函数名前面带有 i ,比如 irate, idelta, etc. | 取时间范围内的 最后一个 和 倒数二个 值进行计算 |
extrapolated(外推/推测) 指:为了覆盖范围向量选择器中指定的完整时间范围,会推断整个时间范围内需要补充样本的时间点及该点的样本值。所以即使样本值都是整数,仍然可能会得到一个非整数的结果。对应的, instant 则不会执行推断的行为,而是直接取时间范围内第一个和最后一个值
说白了就是利用 Interpolation(插值) 进行计算以获得最后结果。假如,node_network_receive_bytes_total 指标有如下两个样本
node_network_receive_bytes_total[40s]
100 @1734400800.000 // (10:00:00 样本值为 100)
103 @1734400830.000 // (10:00:30 样本值为 103)
如果我们需要计算 10:00:00 ~ 10:00:40 之间的变化量(e.g. delta)
- 如果是 extrapolated 的计算方式,则会推测 10:00:40 的样本的值,然后计算 10:00:00 10:00:40 两个数之间的变化量。
- 结果可能是 3.2132345…..
- 如果是 instant 的计算方式,则不会推测 10:00:40 的样本值,而是直接用离 10:00:40 最近的 10:00:30 的这个样本值与 10:00:00 的样本值进行计算。
- 结果是 3
在进行外推时还有一个细节,就是外推的阈值,比如 30 到 40 之间差了 10,那外推的时候,是推算 31, 32,33…, 40 中具体哪个点的值呢?这是由一个 extrapolationThreshold 阈值定义的。
TODO: 用插值来描述这个计算方式合适吗?(AI 说是插值,但是我看官方文档只在直方图相关函数里用了 Interpolation 描述,关于 rate 和 delta 的是 extrapolated 这个词)
变化量相关的代码逻辑详见 PromQL 中的变化量函数部分
单调性处理
在部分变化量相关的函数描述中,有这么一句:
[!Note] Breaks in monotonicity (such as counter resets due to target restarts) are automatically adjusted for(单调性中断(比如由于目标重启导致的计数器重置)会自动处理)
这句话翻译成人话是这样的:用于计算的样本中如果存在由于采样目标重启引起计数器归 0 的情况(会导致后面的样本的值比前一个样本的值小),那么会在后面样本的值加上前面样本的值。
比如获取了 5 个数值 2, 4, 6, 0, 2,那么 counterCorrection 的值就是 6,变成 2, 4, 6, 6, 8。主要是为了防止计数器重置导致的计算错误。在代码中称为 counterCorrection(计数器矫正)
变化量相关的函数根据是否处理单调性中断,还可以分为两类
- 处理单调性中断 # 这类函数适用于 Counter 类型的指标。e.g. rate, increase, etc.
- 不处理单调新中断 # 这类函数适用于 Gauge 类型的指标。e.g. delta, deriv, etc.
delta() - 增量/差量
delta(v range-vector) 计算范围向量 v 中,所有时间序列元素的第一个和最后一个值之间的差异。
- 函数返回值:一个瞬时向量。
[!Tip] delta() 函数推荐用于 Gauges 类型的时间序列数据。
例如,下面的例子返回过去两小时的 CPU 温度差:
delta(cpu_temp_celsius{host="zeus"}[2h])
increase()
increase(V RangeVector[Duration]) 计算范围向量 V 在时间窗口 Duration 内,第一个和最后一个样本的增长量, 该函数会自动处理单调性中断的情况(e.g. 因目标重启导致的计数器重置)。
- 函数返回值:类型只能是 Counter 类型,主要作用是增加图表和数据的可读性。使用 rate 函数记录规则的使用率,以便持续跟踪数据样本值的变化。
例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的增长数:
increase(http_requests_total{job="apiserver"}[5m])
rate()
Note: https://claude.ai/share/85f83732-e4cc-4ee8-b7ff-1424a9e4f11c
rate(V RangeVector[Duration]) 计算范围向量 V 在时间窗口 Duration 内 平均每秒增长了多少数值(通过区间向量中首尾两个样本数据来计算增长速率),该函数会自动处理单调性中断的情况(e.g. 因目标重启导致的计数器重置)。
[!Tip] rate() 与 irate() 更推荐用在 Counter 类型的 Metrics 上,在长期趋势分析或者告警中推荐使用这个函数。
该函数的返回结果不带有度量指标,只有标签列表。
例如,以下表达式返回区间向量中每个时间序列过去 15 分钟内 HTTP 请求数的每秒增长速率:
rate(http_requests_total[15m])
结果:
{code="200",handler="label_values",instance="120.77.65.193:9090",job="prometheus",method="get"} 0
{code="200",handler="query_range",instance="120.77.65.193:9090",job="prometheus",method="get"} 0
{code="200",handler="prometheus",instance="120.77.65.193:9090",job="prometheus",method="get"} 0.2
...
irate(V RangeVector[Duration]) 反应出的是瞬时增长速率。irate 函数是通过区间向量中最后两个样本数据来计算增长速率,这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内最后两个样本数据的 HTTP 请求数的增长速率:
irate(http_requests_total{job="api-server"}[5m])
[!Warning] 当将 rate() 函数与聚合运算符(例如 sum())或随时间聚合的函数(任何
XXX_over_time的函数)一起使用时,必须先执行 rate 函数,然后再进行聚合操作,否则当采样目标重新启动时 rate() 无法检测到计数器是否被重置。
[!Tip] irate 常用于绘制快速变化的计数器,在长期趋势分析或者告警中更推荐使用 rate 函数。因为使用 irate 函数时,速率的简短变化会重置 FOR 语句,形成的图形有很多波峰,难以阅读。
用一个简单的不太严谨的人话总结一下:
- 比如带宽这种,短时、高频、大幅度变化的要使用 irate 来体现出来短时变化速率;
- 长时、低频、小幅度变化的使用 rate 来体现一个长期的均值变化速率。
更不严谨且简单一点,可以说:时间范围短的用 irate;时间范围长的用 rate(不过总的来说还是要多角度结合看,比如时间范围中变化幅度大不大之类的。毕竟 irate 只取最后两个样本,时间跨度太长了就不明显了)
deriv()
[!Tip] delta() 函数推荐用于 Gauges 类型的时间序列数据。
deriv(V RangeVector[Duration]) 计算范围向量 V 在窗口时间 Duration 内中,每个样本的每秒导数(计算时使用了简单线性回归)。
为了进行计算,范围向量必须至少包含两个浮点数样本。如果范围向量中存在 +Inf 或 -Inf ,则计算出的斜率和偏移量值将为 NaN 。
[!Note] 导数,i.e. 斜率,也可以理解为变化率
predict_linear() - 线性预测
predict_linear(v range-vector, t scalar) 预测时间序列 v 在 t 秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。该函数的返回结果不带有度量指标,只有标签列表。
例如,基于 2 小时的样本数据,来预测主机可用磁盘空间的是否在 4 个小时候被占满,可以使用如下表达式:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
通过下面的例子来观察返回值:
predict_linear(http_requests_total{code="200",instance="120.77.65.193:9090",job="prometheus",method="get"}[5m], 5)
结果:
{code="200",handler="query_range",instance="120.77.65.193:9090",job="prometheus",method="get"} 1
{code="200",handler="prometheus",instance="120.77.65.193:9090",job="prometheus",method="get"} 4283.449995397104
{code="200",handler="static",instance="120.77.65.193:9090",job="prometheus",method="get"} 22.99999999999999
...
这个函数一般只用在 Gauge 类型的时间序列上。
时间相关
时间相关的函数都有一个通用的格式: FUNCTION_NAME(v=vector(time()) instant-vector)。FUNCTION_NAME 有如下几个
- day_of_month() # 返回被给定 UTC 时间所在月的第 N 天。返回值范围:1~31
- day_of_week() # 返回被给定 UTC 时间所在周的第 N 天。返回值范围:0~6,0 表示星期天。
- days_in_month() # 返回当月一共有多少天。返回值范围:28~31
- minute() # 返回给定 UTC 时间当前小时的第 N 分钟。结果范围:0~59。、
- hour() # 返回给定 UTC 时间的当前第 N 小时。时间范围:0~23
- month() 返回给定 UTC 时间当前属于第 N 月,结果范围:0~12。
- year() # 函数返回被给定 UTC 时间的当前年份。
这些函数的参数是给定的 UTC 时间 Unix 时间戳,可以通过即时向量获取指定时序数据中样本的时间作为参数
参数也可以省略,省略时,默认为当前 UTC 时间
除了上面这些有通用格式的,下面还有两个比较特殊的
time()
time() 函数返回从 1970-01-01 到现在的秒数。注意:它不是直接返回当前时间,而是时间戳。
通常与 process_start_time_seconds 之类的指标同时使用,以 time() - process_start_time_seconds{} 即可计算出程序已经运行了多长时间
这个减法的意思是:当前时间减去程序启动时的时间,就是程序知道现在已经运行了多长时间。
timestamp()
timestamp(v instant-vector) 函数返回向量 v 中的每个样本的时间戳(从 1970-01-01 到现在的秒数)。
[!Tip] 若想获取非 UTC 的时间,有一个通用的解决方案,就是将 Unix 时间戳加上对应时区的秒数
比如东八区的时间,就是需要加上 $8*3600$ 秒,
FUNC(vector(time() + 8 * 3600));然后各种函数使用运算结果后的 Unix 时间戳作为参数输出结果。
- e.g. 获取当前东八区的第 N 小时:
hour(vector(time() + 8 * 3600));第 N 月:month(vector(time() + 8 * 3600))。利用时间戳的秒数,可以规避很多复杂的问题。
最佳实践
(hour() + 8) % 24 获取东八区的第 N 个小时。通过对 24 取余,确保结果始终在 0-23 的范围内。当 UTC 时间在 16:00 到 23:59 之间时,简单地 +8 会导致结果超过 23,这就是为什么我们需要 % 24 操作。当 UTC 时间是 23:00 时,(23 + 8) % 24 = 7,正确显示东八区的 7:00。
聚合范围向量
XXX_over_time()
下面的函数列表允许传入一个区间向量,它们会聚合每个时间序列的范围,并返回一个瞬时向量:
- avg_over_time(range-vector) # 范围向量内所有度量指标的平均值。
- min_over_time(range-vector) # 范围向量内所有度量指标的最小值。
- max_over_time(range-vector) # 范围向量内所有度量指标的最大值。
- sum_over_time(range-vector) # 范围向量内所有度量指标的求和。
- count_over_time(range-vector) # 范围向量内所有度量指标的样本数据个数。
- quantile_over_time(scalar, range-vector) # 范围向量内所有度量指标的样本数据值分位数,φ-quantile (0 ≤ φ ≤ 1)。
- stddev_over_time(range-vector) # 范围向量内所有度量指标的总体标准差。
- stdvar_over_time(range-vector) # 范围向量内所有度量指标的总体标准方差。
- first_over_time(RangeVector) # 范围向量内,最老时间点的值
- 3.9 版本新增的函数。关于
first_over_time(foo[5m])与foo offset 5m之间异同的讨论 https://github.com/prometheus/prometheus/issues/16963
- 3.9 版本新增的函数。关于
- last_over_time(RangeVector) # 范围向量内,最新时间点的值
- present_over_time(RangeVector) # 没懂
注意: 即使范围向量内的值分布不均匀,它们在聚合时的权重也是相同的。
Label 变化
label_join()
label_join(
v instant-vector,
dst_label string,
separator string,
src_label_1 string,
src_label_2 string,
...
)
函数可以将时间序列 v 中多个标签 src_label_XXX 的值,通过 separator 作为连接符写入到一个新的标签 dst_label 中。
Note: 可以有多个 src_label 标签。非常类似 Relabeling(重新标记) 的某个功能。
例如,以下表达式返回的时间序列多了一个 foo 标签,标签值为 etcd,etcd-k8s:
up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"}
=> up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"} 1
label_join(up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"}, "foo", ",", "job", "service")
=> up{endpoint="api",foo="etcd,etcd-k8s",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"} 1
label_replace()
为了能够让客户端的图表更具有可读性(比如 Grafana 的 表格面板),可以通过 label_replace 函数为时间序列添加额外的标签、更改已有标签的值。label_replace 的具体参数如下:
label_replace(
v instant-vector,
dst_label string,
replacement string,
src_label string,
regex string
)
该函数会依次对 v 中的每一条时间序列进行处理,通过 regex 匹配 src_label 的值,并将匹配部分 relacement 写入到 dst_label 标签中。
下面的是一个新增 Label 的例子
label_replace(
up,
"host",
"$1",
"instance",
"(.*):.*"
)
函数处理后,时间序列将多一个 host 标签,值为 Exporter 实例的 IP 地址:
up{host="localhost",instance="localhost:9090",job="prometheus"} 1
up{host="localhost",instance="localhost:9100",job="node"} 1
下面的是一个修改 Label 的值的例子。将 node_uname_info 指标内,instance 标签的值中的 9100 去掉,只保留 IP
label_replace(
node_uname_info{},
"instance",
"$1",
"instance",
"(.*):9100"
)
数值计算
sqrt()
sqrt(v instant-vector) 函数计算向量 v 中所有元素的平方根。
abs() - 绝对值
abs(v instant-vector) 返回输入向量的所有样本的 Absolute Value(绝对值)。
ceil()/floor() - 向上/下四舍五入取整
ceil(v instant-vector) 将 v 中所有元素的样本值向上四舍五入到最接近的整数。例如:
node_load5{instance="192.168.1.75:9100"}
# 结果为 2.79
ceil(node_load5{instance="192.168.1.75:9100"})
# 结果为 3
floor(v instant-vector) 函数与 ceil() 函数相反,将 v 中所有元素的样本值向下四舍五入到最接近的整数。
round(v instant-vector, to_nearest=1 scalar) 函数与 ceil 和 floor 函数类似,返回向量中所有样本值的最接近的整数。to_nearest 参数是可选的,默认为 1,表示样本返回的是最接近 1 的整数倍的值。你也可以将该参数指定为任意值(也可以是小数),表示样本返回的是最接近它的整数倍的值。
ln()/log2()/log10() - 对数
ln(v instant-vector) 计算瞬时向量 v 中所有样本的 natural logarithm(自然对数)(以常数 e(约等于 2.71828)为底的对数)。
特殊情况:
- ln(+Inf) = +Inf
- ln(0) = -Inf
- ln(x < 0) = NaN
- ln(NaN) = NaN
log2(v instant-vector) 计算瞬时向量 v 中所有样本的 binary logarithm(二进制对数)(以 2 为底的对数)。输入向量中的直方图样本会被静默忽略,其特殊情况处理方式与 ln 函数相同。
log10(v instant-vector) 计算瞬时向量 v 中所有样本的 decimal logarithm(十进制对数)(以 10 为底的对数)。输入向量中的直方图样本会被静默忽略,其特殊情况处理方式与 ln 函数相同。
其他函数
scalar() # scalar(v instant-vector) 函数的参数是一个单元素的瞬时向量,它返回其唯一的时间序列的值作为一个标量。如果度量指标的样本数量大于 1 或者等于 0, 则返回 NaN。
exp()
exp(v instant-vector) 函数,输入一个瞬时向量,返回各个样本值的 e 的指数值,即 e 的 N 次方。当 N 的值足够大时会返回 +Inf。特殊情况为:
- Exp(+Inf) = +Inf
- Exp(NaN) = NaN
histogram_quantile()
histogram_quantile(φ float, b instant-vector) 从 bucket 类型的向量 b 中计算 φ (0 ≤ φ ≤ 1) 分位数(百分位数的一般形式)的样本的最大值。(有关 φ 分位数的详细说明以及直方图指标类型的使用,请参阅直方图和摘要)。向量 b 中的样本是每个 bucket 的采样点数量。每个样本的 labels 中必须要有 le 这个 label 来表示每个 bucket 的上边界,没有 le 标签的样本会被忽略。直方图指标类型自动提供带有 _bucket 后缀和相应标签的时间序列。
可以使用 rate() 函数来指定分位数计算的时间窗口。
例如,一个直方图指标名称为 employee_age_bucket_bucket,要计算过去 10 分钟内 第 90 个百分位数,请使用以下表达式:
histogram_quantile(0.9, rate(employee_age_bucket_bucket[10m]))
返回:
这表示最近 10 分钟之内 90% 的样本的最大值为 35.714285714285715。
这个计算结果是每组标签组合成一个时间序列。我们可能不会对所有这些维度(如 job、instance 和 method)感兴趣,并希望将其中的一些维度进行聚合,则可以使用 sum() 函数。例如,以下表达式根据 job 标签来对第 90 个百分位数进行聚合:
histogram_quantile() 函数必须包含 le 标签 histogram_quantile(0.9, sum(rate(employee_age_bucket_bucket[10m])) by (job, le))
如果要聚合所有的标签,则使用如下表达式:
histogram_quantile(0.9,sum(rate(employee_age_bucket_bucket[10m])) by (le))
注意
histogram_quantile 这个函数是根据假定每个区间内的样本分布是线性分布来计算结果值的(也就是说它的结果未必准确),最高的 bucket 必须是 le="+Inf" (否则就返回 NaN)。
如果分位数位于最高的 bucket(+Inf) 中,则返回第二个最高的 bucket 的上边界。如果该 bucket 的上边界大于 0,则假设最低的 bucket 的的下边界为 0,这种情况下在该 bucket 内使用常规的线性插值。
如果分位数位于最低的 bucket 中,则返回最低 bucket 的上边界。
如果 b 含有少于 2 个 buckets,那么会返回 NaN,如果 φ < 0 会返回 -Inf,如果 φ > 1 会返回 +Inf。
sort()
sort(v instant-vector) 函数对向量按元素的值进行升序排序,返回结果:key: value = 度量指标:样本值[升序排列]。
sort_desc()
sort(v instant-vector) 函数对向量按元素的值进行降序排序,返回结果:key: value = 度量指标:样本值[降序排列]。
应用示例
计算 Counter 指标增长率
我们知道 Counter 类型的监控指标其特点是只增不减,在没有发生重置(如服务器重启,应用重启)的情况下其样本值应该是不断增大的。为了能够更直观的表示样本数据的变化剧烈情况,需要计算样本的增长速率。
通过增长率表示样本的变化情况
increase(v range-vector) 函数是 PromQL 中提供的众多内置函数之一。其中参数 v 是一个区间向量,increase 函数获取区间向量中的第一个后最后一个样本并返回其增长量。因此,可以通过以下表达式 Counter 类型指标的增长率:
increase(node_cpu[2m]) / 120
这里通过 node_cpu[2m] 获取时间序列最近两分钟的所有样本,increase 计算出最近两分钟的增长量,最后除以时间 120 秒得到 node_cpu 样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均 CPU 使用率。
rate(v range-vector) 函数,rate 函数可以直接计算区间向量 v 在时间窗口内平均增长速率。因此,通过以下表达式可以得到与 increase 函数相同的结果:
rate(node_cpu[2m])
需要注意的是使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL 提供了另外一个灵敏度更高的函数 irate(v range-vector)。
irate(v range-vector) 函数同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate 函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate(node_cpu[2m])
irate 函数相比于 rate 函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate 的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用 rate 函数。
预测 Gauge 指标变化趋势
在一般情况下,系统管理员为了确保业务的持续可用运行,会针对服务器的资源设置相应的告警阈值。例如,当磁盘空间只剩 512MB 时向相关人员发送告警通知。 这种基于阈值的告警模式对于当资源用量是平滑增长的情况下是能够有效的工作的。 但是如果资源不是平滑变化的呢? 比如有些某些业务增长,存储空间的增长速率提升了高几倍。这时,如果基于原有阈值去触发告警,当系统管理员接收到告警以后可能还没来得及去处理问题,系统就已经不可用了。 因此阈值通常来说不是固定的,需要定期进行调整才能保证该告警阈值能够发挥去作用。 那么还有没有更好的方法吗?
PromQL 中内置的 predict_linear(v range-vector, t scalar) 函数可以帮助系统管理员更好的处理此类情况,predict_linear 函数可以预测时间序列 v 在 t 秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间的是否在 4 个小时候被占满,可以使用如下表达式
- predict_linear(node_filesystem_free{job=“node”}[2h], 4 * 3600) < 0
统计 Histogram 指标的分位数
Prometheus 的四种监控指标类型,其中 Histogram 和 Summary 都可以同于统计和分析数据的分布情况。区别在于 Summary 是直接在客户端计算了数据分布的分位数情况。而 Histogram 的分位数计算需要通过 histogram_quantile(φ float, b instant-vector)函数进行计算。其中 φ(0<φ<1)表示需要计算的分位数,如果需要计算中位数 φ 取值为 0.5,以此类推即可。
以指标 http_request_duration_seconds_bucket 为例:
# HELP http_request_duration_seconds request duration histogram
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.5"} 0
http_request_duration_seconds_bucket{le="1"} 1
http_request_duration_seconds_bucket{le="2"} 2
http_request_duration_seconds_bucket{le="3"} 3
http_request_duration_seconds_bucket{le="5"} 3
http_request_duration_seconds_bucket{le="+Inf"} 3
http_request_duration_seconds_sum 6
http_request_duration_seconds_count 3
当计算 9 分位数时,使用如下表达式:
histogram_quantile(0.5, http_request_duration_seconds_bucket)
通过对 Histogram 类型的监控指标,用户可以轻松获取样本数据的分布情况。同时分位数的计算,也可以非常方便的用于评判当前监控指标的服务水平。
获取分布直方图的中位数
需要注意的是通过 histogram_quantile 计算的分位数,并非为精确值,而是通过 http_request_duration_seconds_bucket 和 http_request_duration_seconds_sum 近似计算的结果。
动态标签替换
一般来说来说,使用 PromQL 查询到时间序列后,可视化工具会根据时间序列的标签来渲染图表。例如通过 up 指标可以获取到当前所有运行的 Exporter 实例以及其状态:
up{instance="localhost:8080",job="cadvisor"} 1
up{instance="localhost:9090",job="prometheus"} 1
up{instance="localhost:9100",job="node"} 1
这是可视化工具渲染图标时可能根据,instance 和 job 的值进行渲染,为了能够让客户端的图标更具有可读性,可以通过 label_replace 标签为时间序列添加额外的标签。label_replace 的具体参数如下:
label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)
该函数会依次对 v 中的每一条时间序列进行处理,通过 regex 匹配 src_label 的值,并将匹配部分 relacement 写入到 dst_label 标签中。如下所示:
label_replace(up, "host", "$1", "instance", "(.*):.\_")
函数处理后,时间序列将包含一个 host 标签,host 标签的值为 Exporter 实例的 IP 地址:
up{host="localhost",instance="localhost:8080",job="cadvisor"} 1
up{host="localhost",instance="localhost:9090",job="prometheus"} 1
up{host="localhost",instance="localhost:9100",job="node"} 1
除了 label_replace 以外,Prometheus 还提供了 label_join 函数,该函数可以将时间序列中 v 多个标签 src_label 的值,通过 separator 作为连接符写入到一个新的标签 dst_label 中:
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)
label_replace 和 label_join 函数提供了对时间序列标签的自定义能力,从而能够更好的于客户端或者可视化工具配合。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.