Prometheus 衍生品
概述
Prometheus 高可用
参考:
Prometheus 本身没有集群的概念,也就没有主备,也就没有互相备份,并且,Prometheus 是主动 pull 数据的,所以 如果 Prometheus 想要高可用就需要多个 Prometheus Server 共享存储,那么如果要共享存储,则无法保持数据一致性,因为共享存储内的数据会收到两份数据。官方给出了一个办法,就是使用 remote 配置,将数据保存到第三方存储中,而不是通过 Prometheus 自己的数据系统进行保存。
如果多个 Prometheus 分别保存自己的数据,那么当一个节点 down 掉后,另一个节点就算数据没丢失,也没法保证两边的数据一致性。所以,Prometheus 通过远程存储的功能,来实现基本的数据高可用功能。
高可用实践文章:
- 使用 Thanos+Prometheus+Grafana 打造监控系统:https://mp.weixin.qq.com/s/8Ws2po_oT5sSKLD3nGYwMw
高科用方案推荐
Cortex
项目地址:https://github.com/cortexproject/cortex
Thanos
具有长期存储功能的高可用 Prometheus
https://www.qikqiak.com/k8strain/monitor/thanos/
Victoria Metrics
快速,经济高效且可扩展的时间序列数据库
项目地址:https://github.com/VictoriaMetrics/VictoriaMetrics
m3db
项目地址:https://github.com/m3db/m3
高可用方案对比
Victoria Metrics 与 Thanos 对比
参考:
这篇文章对比有误差,并没有用 Thanos 的 Receiver 架构模式进行对比,实际上,Thanos 的 Receiver 模式与 VM 是类似的,也是通过 Remote Write 来实现数据转存。
Thanos 与 Cortex 对比
发展现状
Thanos 项目创建于 2017 年 12 月份。在 2019 年 8 月份成为 CNCF 沙盒项目。目前的维护成员主要来自于 Red Hat。
Cortex 项目创建于 2016 年 2 月份。在 2018 年 8 月成为 CNCF 沙盒项目。项目维护成员主要来自于 Weavework。
| 项目名称 | Watch | Star | Fork | Issues | Contributors |
|---|---|---|---|---|---|
| Thanos | 157 | 5.2k | 654 | 87 | 188 |
| Cortex | 90 | 2.4k | 296 | 230 | 90 |
从项目发展上讲 Thanos 相对于 Cortex 更加年轻,在活跃度上呈后来者居上的态势。且 prometheus-operator 项目中已经引入了 Thanos 的部署用例和代码库,两者的契合度相对较高。Cortex 目前实验性的 blocks 数据块写入后端存储的特性也复用了 Thanos 的代码。
集群架构
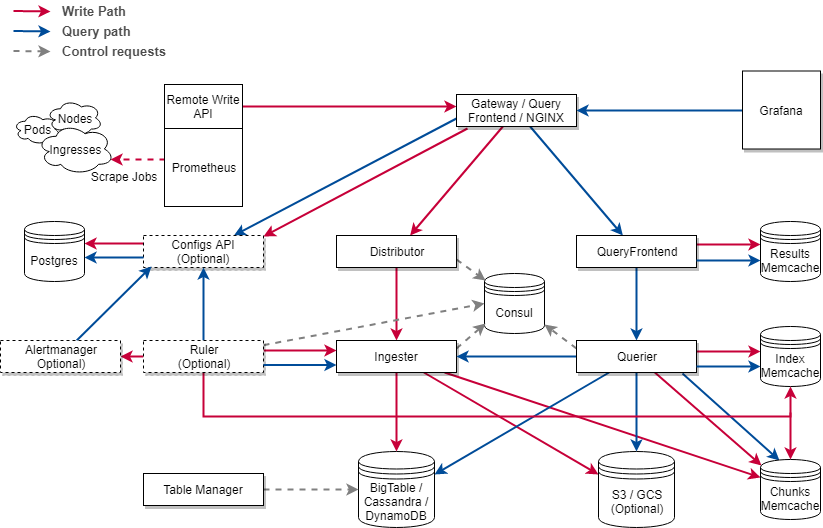
Cortex 的定位是提供 Prometheus as a Service,采用中心化的架构。Prometheus 可能来自于多个不同的地域,所有的数据都汇入一个 Cortex 数据中心,由 Cortex 集中写入,查询和告警。
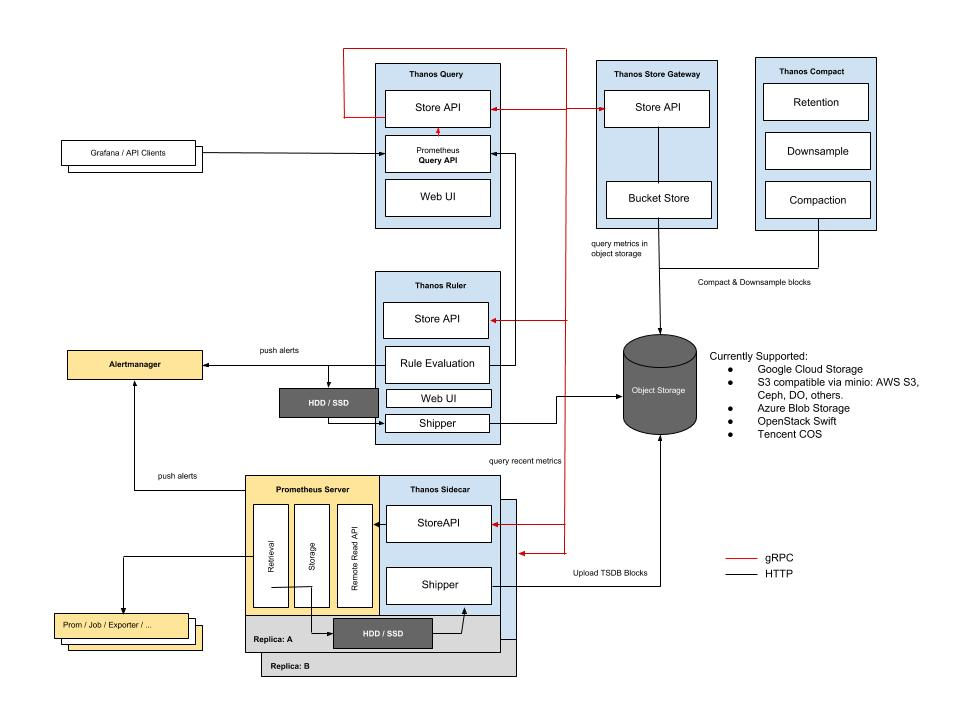
Thanos 采用的是分散式的架构,其数据可以分散在多个数据中心,且分别存储于多个对象存储桶中。对于数据的写入,查询和告警可分散也可集中。
特性对比
| 特性名称 | Thanos | Cortex |
|---|---|---|
| 全局查询 | 集群级支持 | 租户级支持 |
| 全局告警 | 集群级支持 | 租户级支持 |
| 高可用 | 部分支持 | 支持 |
| 长期存储 | 支持 | 支持 |
| 多集群 | 支持 | 不支持 |
| 多租户 | 部分支持 | 支持 |
| 集群拓展 | 支持 | 支持 |
| 查询缓存 | 支持 | 支持 |
| 查询拆分 | 按时间区间拆分 | 按天拆分 |
| 下采样 | 支持 | 不支持 |
| 数据去重 | 查询时去重 | 写入时去重 |
| 存储时效 | 支持 | 不支持 |
数据写入
Thanos 主要使用 pull 方式的数据写入,通过 Sidecar 将 Prometheus 在本地生成的长期只读数据上传到对象存储中。
Cortex 使用 push 方式的数据写入,prometheus 通过 remote wirte 接口将数据写入到 Distributor 组件中,由 Distributor 分发给 Ingester 将数据写入到存储后端。
值得注意的是 Thanos 新推出的实验性组件 Receiver 也采用与 Cortex 相同的数据写入方式,通过 Prometheus 的 Remote Write 接口将数据写入 Receiver 组件,也使用哈希环的的方式保证写入数据的多副本可靠性。
数据存储
Thanos 使用 TSDB 的 blocks 存储,每个 blocks 块初始存储 2 小时长的数据,后续在长期存储中经过压缩存储时长会增大。
Cortex 使用 TSDB 的 chunks 存储,每个 chunks 块存储 12 小时长的数据。新推出的实验性特性将支持 blocks 存储。
Thanos 将长期存储的数据都存放于对象存储中。
Cortex 则将 index 和 chunks 分开存储,index 存储于 NoSQL 键值存储中如 BigTable,Cassandra 和 DynamoDB,chunks 存储于 BigTable,Cassandra,DynamoDB 和对象存储中。其实验性的 blocks 存储只支持存放于对象存储。
数据去重
Thanos 在读取时由 query 对数据进行去重。而 Cortex 在写入时就会在 Distributor 进行去重。这意味着 Thanos 会存储多份的冗余数据。存储的开销也会相应地更大。
查询优化
目前 prometheus 的查询痛点在于做大时间跨度的查询时需要耗费大量的时间和内存资源。
Thanos 采取的优化方式包括对长期存储的数据进行下采样,在查询大跨度时间的数据时使用采样跨度更大的数据块做查询。除此之外还可以按时间段进行拆分,分配每个长期存储网关所负责查询的时间段。还可以按照存储桶进行拆分,数据写入到多个存储桶中,而每个长期存储网关负责查询一个存储桶。时间拆分和桶拆分可以同时使用,从部署架构层面进行优化。
Cortex 采取的优化方式是将数据进行缓存,在查询时通过读取缓存中的查询结果,index 和 chunks,并生成子查询用以补足缓存中所遗漏的内容。在做大时间跨度的查询时会将其拆分为多个单天的子查询并行处理。并且查询后的结果也会被缓存下来用于后续的查询。
多租户
Cortex 的多租户实现了租户的查询和告警相关配置的隔离。所有的 Cortex 组件在发送的请求中都会携带一个 Header X-Scope-OrgID,表示租户 ID。当 Ingester 在写入数据时发现有一个新的租户 ID 时,则认为这是一个新的租户,当 Querier 在读取数据时,会判断请求中的租户 ID 是否已经存在。创建新租户的过程是随着指标数据的写入自动完成的,不存在租户的创建或删除接口,也不存在租户的鉴权和认证,这些需要在入口网关中实现。
Thanos 的多租户目前只是实验性功能且不完整,其中的 Reciever 组件实现了多租户的数据写入隔离,与 Cortex 相似也是使用了请求头携带租户 ID,相当于 Cortex 中 Distributor 和 Ingester 的结合体。对于多租户的查询目前推荐的方式是为每个租户的 Prometheus+Sidecar 设置专门查询用的 Query,或者是通过prom-label-proxy来为查询强制添加过滤标签,以标签作为租户隔离的依据。
多集群
Thanos 的集群架构式分散式的,依靠 Querier 组件的分层架构支持了跨多个 Thanos 集群的查询和评估告警。
Cortex 的集群架构是中心式的,目前暂不支持跨集群。
高可用
Thanos 中的 Compact 组件是单例部署,暂不支持高可用,其他组件都支持高可用。
Cortex 中的所有组件均实现了多副本部署,支持高可用。
集群拓展
Thanos 集群具有灵活的拓展性,对于内部的集群可以通过 Sidecar+Prometheus 拓展,对于外部的集群可以通过 Prometheus+Receiver 拓展。
Cortex 的集群拓展只需要加新的 Prometheus 实例对接到写入网关上即可。
维护成本
资源开销
Thanos 中对于内存开销较大的组件是 Store,该组件会将部分查询频繁的数据块索引进行缓存。
Cortex 中对于内存开销较大的组件是缓存中间件,这其中缓存了 index,chunks 和查询结果。
相比之下 Cortex 缓存的数据会更多,占用的内存开销更大。
第三方组件依赖
Thanos 的外部组件依赖仅有对象存储后端(存放长期数据)。而 Cortex 的外部组件依赖包括了 Postgres(存放各租户的规则配置),Consul 键值存储(集群治理,后续会以 gossip 替代),存储后端(存放长期数据),Redis 或 Memcached(查询缓存)。
更多的组件依赖使得 Cortex 的维护难度会更大。
部署配置复杂性
Thanos 的部署配置目前分为两个部分:
- 通过prometheus-operator部署 Prometheus+Sidecar,包括配置每个 prometheus 集群所对应的 recording 和 alerting 规则;
- 通过helm charts部署配置其他的组件。
Cortex 的部署配置可以使用helm charts,对于多租户的告警相关配置需要通过接口请求配置。
其他痛点
Thanos Query 会向多个 StoreAPI 服务发起查询请求,汇聚所有的请求结果后才会响应,随着集群架构的扩展,StoreAPI 服务的数量增加导致了出现连接问题的可能性也会增加,为了避免部分查询对整体的影响,Querier 上实现了部分响应的特性,根据设置条件(如超时时间)使得查询不会出现过长的等待。然而这又带来了另一个问题,查询的返回结果可能会不完整,需要根据场景在查询稳定性和完整性上做取舍。
Cortex 的多租户功能需要外部做一定程度的开发封装,在网关上自行实现请求的认证和鉴权,对于各个租户的相关配置是以接口方式实现,需要外部封装接口的请求客户端。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.