故障处理
概述
公众号-CNCF,记一次远程写性能问题引发的Prometheus版本升级事件
compaction failed
compaction failed 是一个 Prometheus 在压缩数据时产生的错误,导致该问题的因素多种多样,最常见的就是使用 NFS 作为 Prometehus 时序数据库的后端存储。
官方文档中曾明确表明不支持 NFS 文件系统

该问题的表现形式通常为文件丢失,比如,某个 Block 中的 meta.json 文件丢失
msg="compaction failed" err="plan compaction: open /prometheus/01FHHPS3NR7M2E8MAV37S61ME6/meta.json: no such file or directory"
msg="Failed to read meta.json for a block during reloadBlocks. Skipping" dir=/prometheus/01FHHPS3NR7M2E8MAV37S61ME6 err="open /prometheus/01FHHPS3NR7M2E8MAV37S61ME6/meta.json: no such file or directory"
经过日志筛选,该问题起源于一次 Deleting obsolete block 操作之后的 compact blocks,也就是删除过期块后压缩块。 失败操作源于:
msg="compaction failed" err="delete compacted block after failed db reloadBlocks:01FHHPS3NR7M2E8MAV37S61ME6: unlinkat /prometheus/01FHHPS3NR7M2E8MAV37S61ME6/chunks: directory not empty"
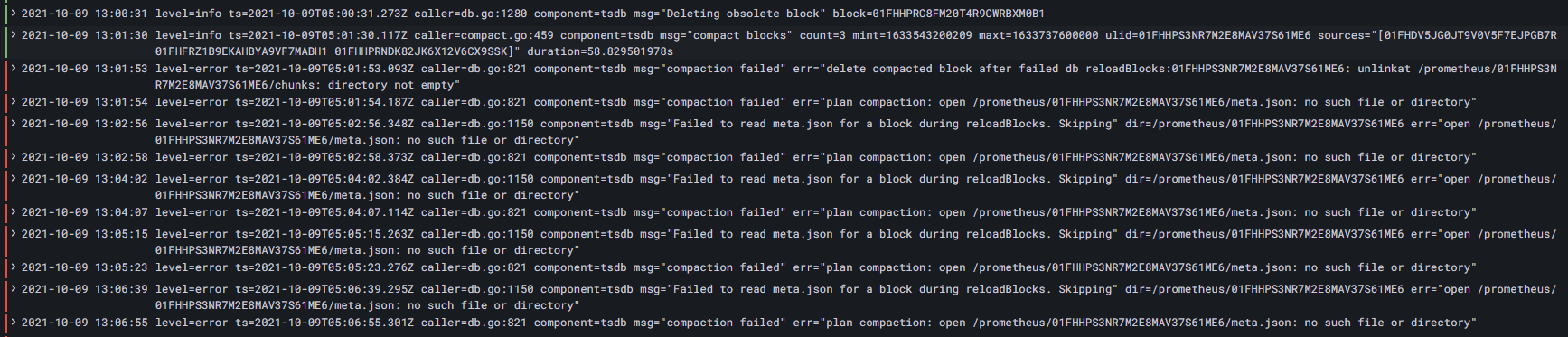
这些报错日志信息,可以在 ./prometheus/tsdb/db.go 代码中找到
解决方式
可以直接删除 01FHHPS3NR7M2E8MAV37S61ME6 块,也就是直接删除这个目录,并重启 Prometheus
Error on ingesting out-of-order result from rule evaluation
Error on ingesting out-of-order result from rule evaluation
该问题通常是由于记录规则的处理结果中,包含 NaN 而产生的告警,所有 NaN 的时间序列都会被丢弃,并不会保存到数据库中。

下面是报错的具体内容,可以看到 numDropped 是记录规则查询后生成的新时间序列中,被丢弃的时间序列。
caller=manager.go:651 component="rule manager" group=kube-apiserver.rules msg="Error on ingesting out-of-order result from rule evaluation" numDropped=231
caller=manager.go:651 component="rule manager" group=kube-apiserver-availability.rules msg="Error on ingesting out-of-order result from rule evaluation" numDropped=121
这个错误日志,可以从 Prometheus 代码中 ./prometheus/rules/manager.go 的 Group.Eval() 方法中看到,每次评估规则时,只要有异常值得序列,都会抛出该错误日志信息。
// Eval runs a single evaluation cycle in which all rules are evaluated sequentially.
func (g *Group) Eval(ctx context.Context, ts time.Time) {
var samplesTotal float64
for i, rule := range g.rules {
select {
case <-g.done:
return
default:
}
func(i int, rule Rule) {
......
for _, s := range vector {
if _, err := app.Append(0, s.Metric, s.T, s.V); err != nil {
rule.SetHealth(HealthBad)
rule.SetLastError(err)
switch errors.Cause(err) {
case storage.ErrOutOfOrderSample:
numOutOfOrder++
level.Debug(g.logger).Log("msg", "Rule evaluation result discarded", "err", err, "sample", s)
case storage.ErrDuplicateSampleForTimestamp:
numDuplicates++
level.Debug(g.logger).Log("msg", "Rule evaluation result discarded", "err", err, "sample", s)
default:
level.Warn(g.logger).Log("msg", "Rule evaluation result discarded", "err", err, "sample", s)
}
} else {
seriesReturned[s.Metric.String()] = s.Metric
}
}
if numOutOfOrder > 0 {
level.Warn(g.logger).Log("msg", "Error on ingesting out-of-order result from rule evaluation", "numDropped", numOutOfOrder)
}
if numDuplicates > 0 {
level.Warn(g.logger).Log("msg", "Error on ingesting results from rule evaluation with different value but same timestamp", "numDropped", numDuplicates)
}
......
}(i, rule)
}
if g.metrics != nil {
g.metrics.GroupSamples.WithLabelValues(GroupKey(g.File(), g.Name())).Set(samplesTotal)
}
g.cleanupStaleSeries(ctx, ts)
}
Error on ingesting out-of-order samples
故障现象
查看日志发现很多 Error on ingesting out-of-order samples Warn 信息
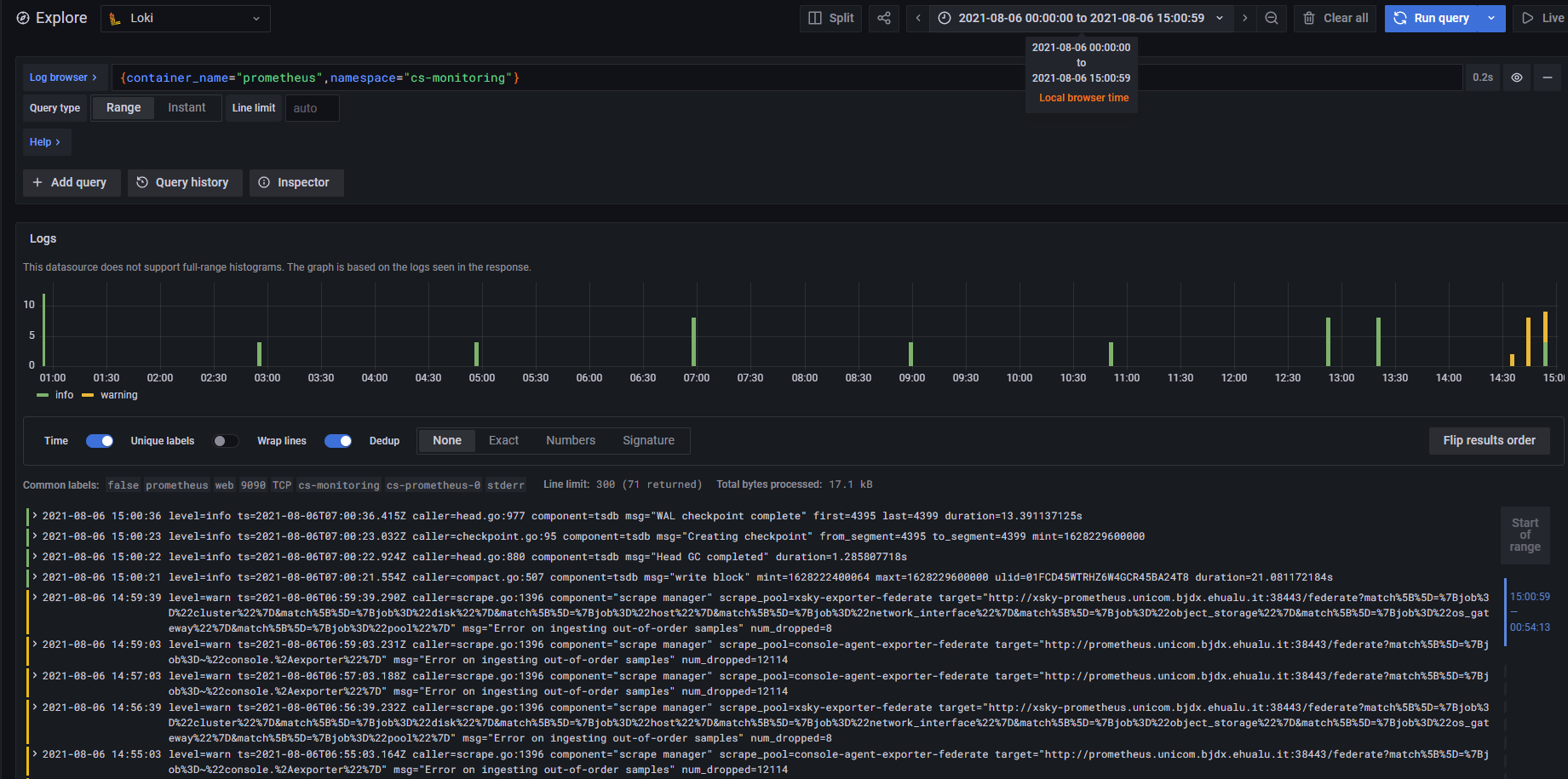
故障原因
参考:
当一个 job 中从多个 Prometheus 中采集相同指标时,就容易产生这个问题。比如,下图示例:
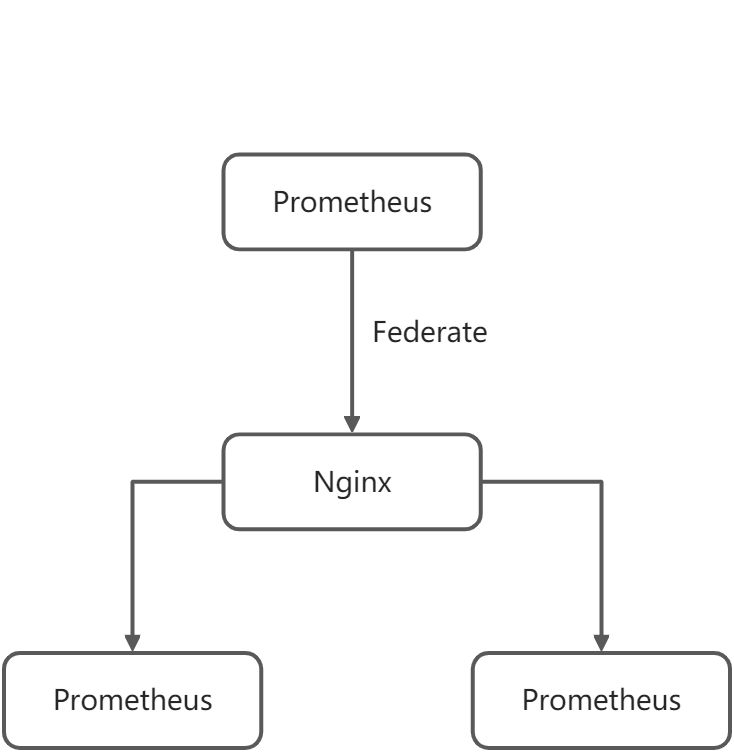
当采集目标是具有相同数据的多个 Prometheus,并且采集时轮流采集,就会很容易产生上述问题
故障处理
每个 Job 配置中,添加 honor_timestamps: false 配置。
反馈
此页是否对你有帮助?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.